53.大数据之旅——java分布式项目14-信息检索技术之Lucene,Solr
信息检索技术
概念介绍
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。
全文检索主要对非结构化数据的数据检索。
结构化数据和非结构化数据
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档,网页等。
当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
注:非结构化数据另外一种叫法叫:全文数据。
数据搜索
按照数据的分类,搜索也分为两种:
对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
我们重点来探讨对非结构化数据的搜索。
顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
比如:利用windows的搜索也可以搜索文件内容,如果做全盘文件的检索,速度会相当的慢,因为硬盘上的数据很大。Linux下的grep命令也是这一种方式。
大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?
这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
索引与全文检索

比如字典,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。
所以,字典的拼音表和部首检字表就相当于字典的索引,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
下面这幅图来自《Lucene in action》,但却不仅仅描述了Lucene的检索过程,而是描述了全文检索的一般过程。

全文检索原理
全文检索大体分两个过程,创建索引(Indexing)和搜索索引(Search)。
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
正向索引
已知文件,欲检索数据,这是建立:文件——数据的映射,称为正向索引,比如下图:

反向索引
在大多数的应用中,我们想做的是搜索某个数据都出现在了哪些文件里或网页里
这是已知数据,欲检索文件,这是建立:数据——文件的映射,称为反向索引,又称倒排索引。
假如我们有100篇文章,想查看一下lucene,hadoop,solr 在哪些文章中出现过,如下图:

左边保存的是一系列字符数据,称为词典。每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
比如我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
- 取出包含字符串“lucene”的文档链表。
- 取出包含字符串“solr”的文档链表。
- 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

注意:全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。尤其是在数据量小的时候更是如此。并且对一个很大量的数据创建索引也是一个很慢的过程。
然而两者还是有区别的,顺序扫描是每次都要扫描,而创建索引的过程仅仅需要一次,以后便是一劳永逸的了,每次搜索,创建索引的过程不必经过,仅仅搜索创建好的索引就可以了。
这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
如何创建索引
全文检索的索引创建过程一般有以下几步:
1.第一步:一些要索引的原文档(Document)。
为了方便说明索引创建过程,这里特意用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
2.第二步:将原文档传给分词组件(Tokenizer)。
分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
- 将文档分成一个一个单独的单词。
- 去除标点符号。
- 去除停词(Stop word)。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
英语中挺词(Stop word)如:“the”,“a”,“this”等。
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
经过分词(Tokenizer)后得到的结果称为词元(Token)。
在我们的例子中,便得到以下词元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
第三步:将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
补充:语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索drove,而drive也能被搜索出来。
第四步:将得到的词(Term)传给索引组件(Indexer)。
索引组件(Indexer)主要做以下几件事情:
4.1. 利用得到的词(Term)创建一个字典。
在我们的例子中字典如下:
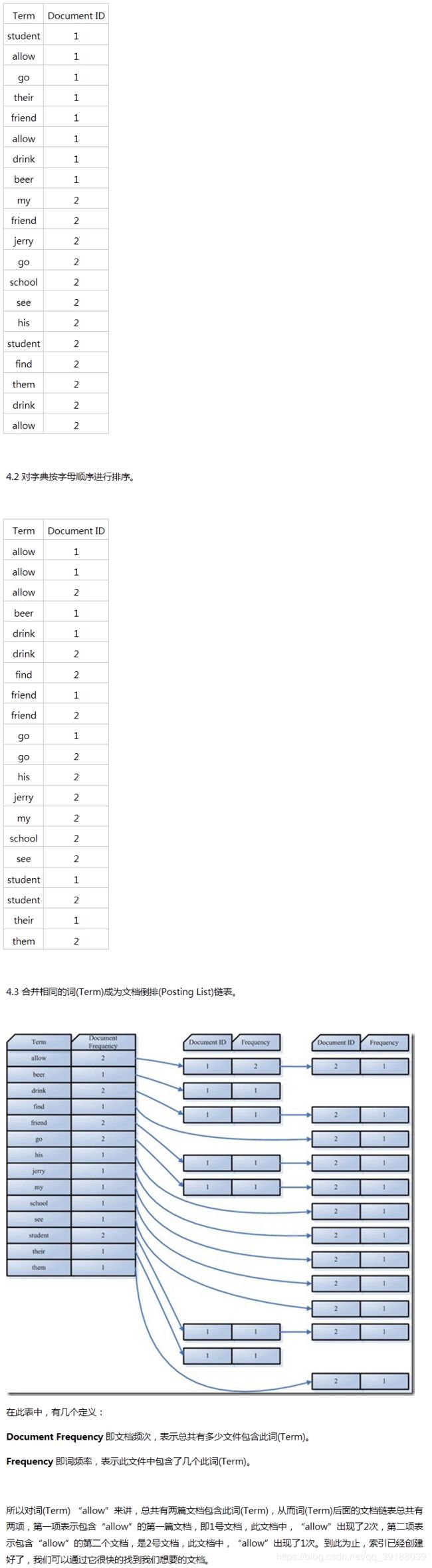
搜索结果排名
问题的引出
请思考这样一个问题:
如果仅仅只有一个或十个文档包含我们查询的字符串,我们的确找到了。然而如果结果有一千个,甚至成千上万个呢?那个又是您最想要的文件呢?
如何计算文档和查询语句的相关性呢?
处理思路:我们把查询语句看作一片短小的文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的相关性好,就应该排在前面。
首先,一个文档有很多词(Term)组成,如search, lucene, full-text, this, a, what等。
其次对于文档之间的关系,不同的Term重要性不同,比如针对一篇关于Lucene的技术文档,search, Lucene, full-text就相对重要一些,this, a , what可能相对不重要一些。所以如果两篇文档都包含search, Lucene,fulltext,这两篇文档的相关性好一些,此外就算一篇文档包含this, a, what,另一篇文档不包含this, a, what,也不能影响两篇文档的相关性。
因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如search, Lucene, fulltext。然后判断这些词(Term)之间的关系。
找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。
向量空间模型算法(Vector Space Model)
概念介绍
向量空间模型(VSM:Vector Space Model)由Salton等人于20世纪70年代提出,并成功地应用于文本检索系统。
VSM概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。
M个无序特征项ti,词根/词/短语/其他每个文档dj可以用特征项向量来表示(a1j,a2j,…,aMj)权重计算,N个训练文档AM*N= (aij) 文档相似度比较
向量空间模型 (或词组向量模型) 是一个应用于信息过滤,信息撷取,索引以及评估相关性的代数模型。
算法原理
- 计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
我们来看一下模型公式:
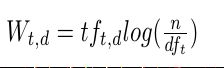
说明:

这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有不同。
- 判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:
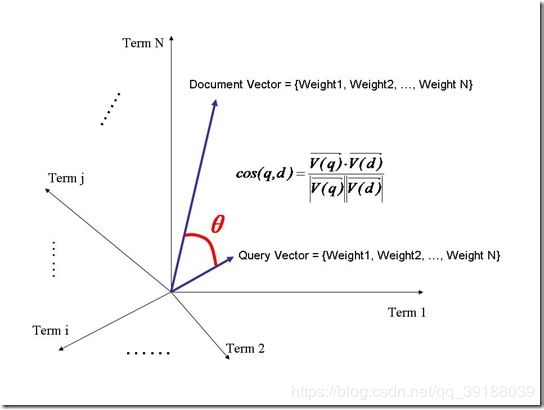
我们认为两个向量之间的夹角越小,相关性越大。
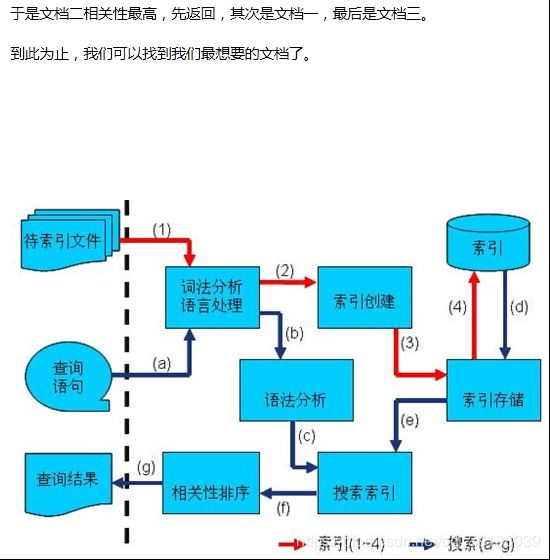
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
相关性打分公式如下


Lucene介绍

官网:http://lucene.apache.org/
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。
Lucene的优点
Lucene作为一个全文检索引擎,其具有如下突出的优点:
1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
Lucene的创始人

Lucene['lusen]的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者。
他还有另外一个称号,就是Hadoop之父。
Lucene 创建索引
准备工作
在pom.xml文件里引入Lucence的依赖jar包
pom.xml配置:
<dependency>
<groupId>com.jtgroupId>
<artifactId>jt-commonartifactId>
<version>0.0.1-SNAPSHOTversion>
dependency>
<dependency>
<groupId>org.apache.solrgroupId>
<artifactId>solr-solrjartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>4.10.2version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>4.10.2version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>4.10.2version>
dependency>
<dependency>
<groupId>org.wltea.analyzergroupId>
<artifactId>ik-analyzerartifactId>
<version>2012FF_u1version>
dependency>
/**
* 用来测试Lucene的创建索引和索引查询
*
* 如果想为tb_item建立全文索引:实现思路
* ①表里的一条信息对应一个doc对象
* Document doc1=new Document();
* doc1.add(new LongField("id","536563",Store.Yes)
* doc1.add(new TextFiele("title","阿尔卡特 (OT-927) 炭黑 联通3G手机 双卡双待",Store.Yes)
* ……
* 最后如果有3000条商品,就会有3000个doc对象,就会为这3000doc对象创建索引
*
* @author ysq
*
*/
public class TestDemo {
@Test
public void create () throws Exception{
//指定索引存储的目录路径,下面表明会在当前工程下创建索引目录
Directory directory=FSDirectory.open(new File("./index"));
//创建英语标准分词器
//Analyzer analyzer=new StandardAnalyzer();
//Analyzer analyzer=new ChineseAnalyzer();
Analyzer analyzer=new IKAnalyzer();
IndexWriterConfig config=
new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
IndexWriter writer=new IndexWriter(directory, config);
//自定义创建文档对象
Document doc1=new Document();
//TextField表示的是插入文本类型,此外还支持:LongField ,DoubleField等
//title是自定义的属性名,不固定
//Thinking in Java 是title对应的属性值
//Store 是否存储。Yes表示存储,可以检索到,也可以打印出内容。
//No,不存储,可以检索到,但不能打印内容。所以在海量数据时,应该设置为No。节省空间
doc1.add(new TextField("title","Thinking in Java",Store.YES));
doc1.add(new TextField("desc","学习Java的入门书籍",Store.YES));
Document doc2=new Document();
doc2.add(new TextField("title","Thinking in C++",Store.YES));
doc2.add(new TextField("desc", "学习C++的必备教材",Store.YES));
writer.addDocument(doc1);
writer.addDocument(doc2);
//记得关闭writer,否则索引文件不会生成
writer.close();
}
执行测试后,会在当前工程下生成index索引目录

Lucene 查询索引
代码:
//根据索引搜索文档(doc)
@Test
public void search() throws Exception{
Directory directory=FSDirectory.open(new File("./index"));
IndexSearcher searcher=new IndexSearcher(IndexReader.open(directory));
//声明查询条件,下列中表示查询 titel中含java的文档
//注意英文的大小写问题,比如In就搜索不到
TermQuery query=new TermQuery(new Term("desc","学习"));
//①参:查询条件对象
//②参:返回top n结果。
TopDocs docs=searcher.search(query,20);
for(ScoreDoc sd:docs.scoreDocs){
//获取文档的得分,是一个>0,小于1的数
float score=sd.score;
//根据docId 获取doc。
Document doc=searcher.doc(sd.doc);
System.out.println("文档得分:"+score+"标题:"+
doc.get("title")+"描述:"+doc.get("desc"));
}
directory.close();
}
Solr介绍

介绍
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器,确切的说是运行在Servlet容器(如 Apache Tomcat 或Jetty)的一个独立的全文搜索服务器。
Solr还对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
同类产品Elasticsearch
ElasticSearch也是一个基于Lucene的搜索服务器
10月13日,Elastic在云栖大会上宣布与阿里云达成新的合作伙伴关系,旨在共同研发及发布于阿里云上提供托管的 Elasticsearch,为中国市场提供崭新的用户体验。
这项名为 “ 阿里云 Elasticsearch ” 的新服务能让阿里云的客户随心所欲地运用 Elasticsearch 强大的实时搜索、采集及数据分析功能,是一站式而且主导性的解决方案。
阿里云总裁胡晓明表示:“作为全球领先的云计算服务商,阿里云致力于通过我们的平台向客户提供最先进的产品,使其保持竞争优势并促进创新。” 他指出:“阿里云 Elasticsearch ” 将会成为一项高度差异化的服务,因为它运用了Elastic先进的搜索产品及强大的 X-Pack功能,不论在服务的任何层面上,均容易上手使用以及方便管理。”
Elasticsearch与Solr的比较
当单纯的对已有数据进行搜索时,Solr更快。
当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
综上所述,Solr的架构不适合实时搜索的应用
Solr安装

Solr使用
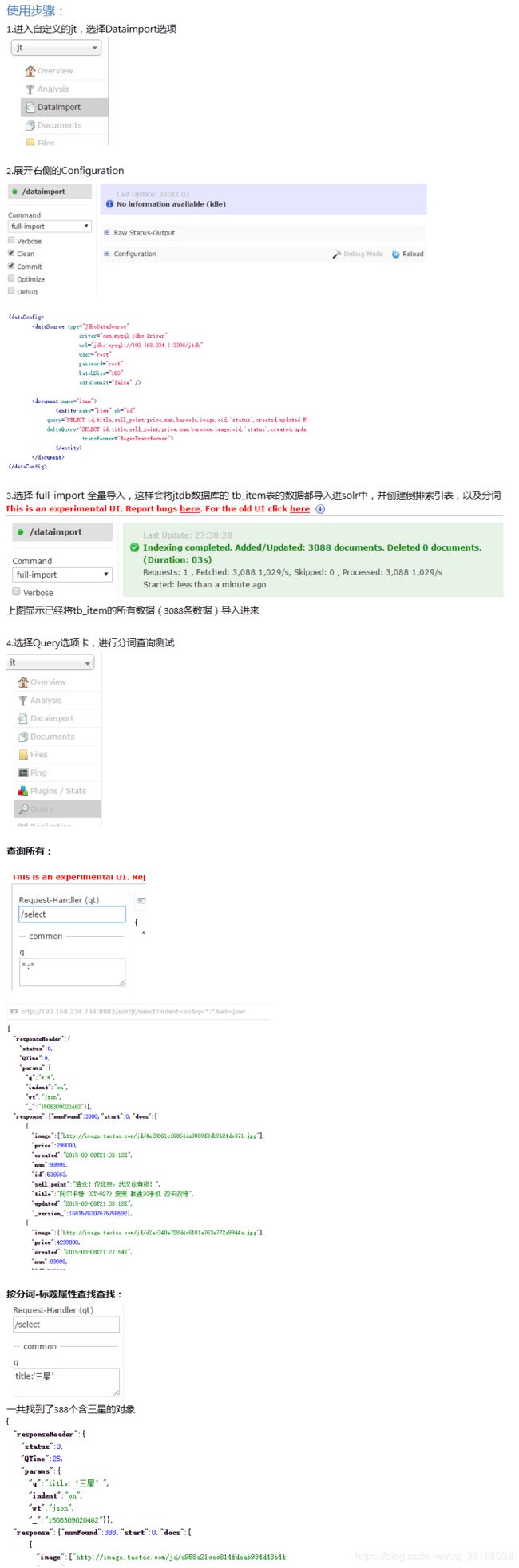
商品搜索整合
实现步骤:
1.配置nginx和hosts文件
配置示例:
#全文搜索solr服务器
server {
listen 80;
server_name solr.jt.com;
#charset koi8-r;
#access_log logs/host.access.log main;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://192.168.234.234:8983;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
#全文搜索服务器
server {
listen 80;
server_name search.jt.com;
#charset koi8-r;
#access_log logs/host.access.log main;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://127.0.0.1:8086;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
hosts文件:
2.引入相关的pom依赖(添加到 jt-parent工程):
相关坐标:
<dependency>
<groupId>org.apache.solrgroupId>
<artifactId>solr-solrjartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>5.2.1version>
dependency>
<dependency>
<groupId>org.wltea.analyzergroupId>
<artifactId>ik-analyzerartifactId>
<version>5.3.0version>
dependency>
3.建立jt-search工程(web-app骨架),并添加jt-common工程,jt-dubbo工程的依赖

Item类代码:
@JsonIgnoreProperties(ignoreUnknown=true)
public class Item extends BasePojo{
@Field("id")
private Long id;
@Field("title")
private String title;
@Field("sellPoint")
private String sellPoint;
@Field("price")
private Long price;
@Field("image")
private String image;
private String[] images;
9.配置 jt-search的 tomcat端口,启动测试 (8086端口)
全文检索商品
所在工程 jt-web
SearchController代码:
@Controller
public class SearchController {
@Autowired
private DubboSearchRestService dubboSearchRestService;
//http://www.jt.com/search.html?q=
@RequestMapping("/search")
public String search(String q,Model model) throws Exception{
//防止中文转页面时乱码
q = new String(q.getBytes("ISO-8859-1"), "UTF-8");
List<Item> itemList=dubboSearchRestService.getItemListBySearch(q);
model.addAttribute("itemList", itemList);
model.addAttribute("query", q);
return "search";
}
}
所在工程 jt-dubbo
DubboSearchRestService接口代码:
@Path("search")
@Consumes({MediaType.APPLICATION_JSON,MediaType.TEXT_XML})
@Produces({ContentType.APPLICATION_JSON_UTF_8,ContentType.TEXT_XML_UTF_8})
public interface DubboSearchRestService {
@POST
@Path("item")
List<Item> getItemListBySearch(String q);
}
所在工程 jt-search
DubboSearchRestServiceImpl代码:
public class DubboSearchRestServiceImpl implements DubboSearchRestService{
@Autowired
private HttpSolrServer httpSolrServer;
@Override
public List<Item> getItemListBySearch(String q) {
SolrQuery solrQuery=new SolrQuery();
solrQuery.setQuery(q);
solrQuery.setStart(0);
solrQuery.setRows(200);
try {
QueryResponse queryResponse=httpSolrServer.query(solrQuery);
List<Item> itemList=queryResponse.getBeans(Item.class);
return itemList;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
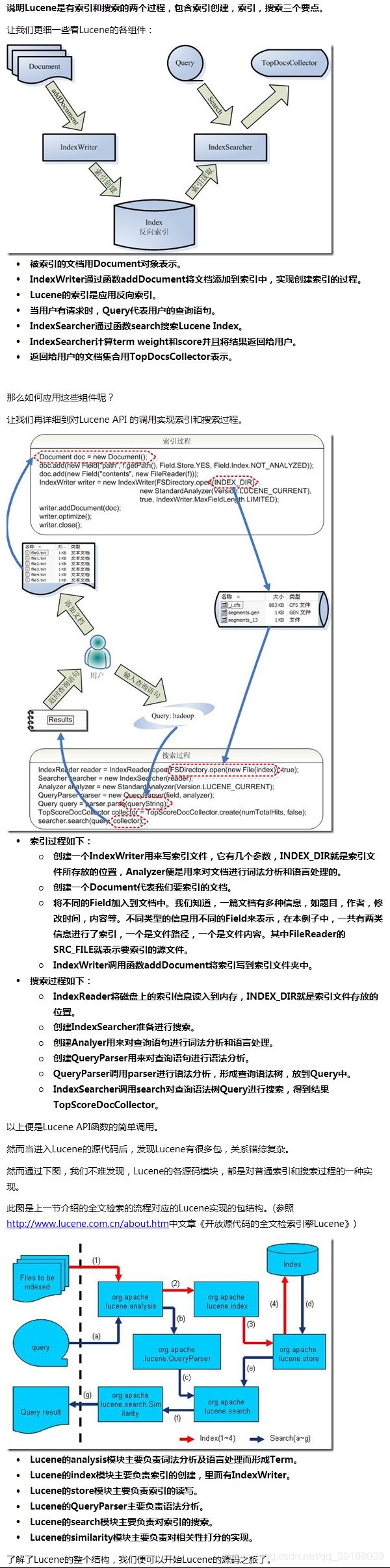
Lucene架构
Lucene总的来说是:
一个高效的,可扩展的,全文检索库。
全部用Java实现,无须配置。
仅支持纯文本文件的索引(Indexing)和搜索(Search)。
不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
在Lucene in action中,Lucene 的构架和过程如下图,

上一篇 52.大数据之旅——java分布式项目13-购物车,Quartz使用,RabbitMQ(消息队列)