主席树详解
转自:点击打开链接
主席树又称函数式线段树,顾名思义,也就是通过函数来实现的线段树,至于为什么叫主席树,那是因为是fotile主席创建出来的这个数据结构(其实貌似是当初主席不会划分树而自己想出来的另一个处理方式。。。。是不是很吊呢? ORZ...)不扯了,切入正题。
主席树就是利用函数式编程的思想来使线段树支持询问历史版本、同时充分利用它们之间的共同数据来减少时间和空间消耗的增强版的线段树。
很多问题如果用线段树处理的话需要采用离线思想,若用主席树则可直接在线处理。故很多时候离线线段树求解可以转化为在线主席树求解。注意,主席树本质就是线段树,变化就在其实现可持久化,后一刻可以参考前一刻的状态,二者共同部分很多。一颗线段树的节点维护的是当前节点对应区间的信息,倘若每次区间都不一样,就会给处理带来一些困难。有时可以直接细分区间然后合并,此种情况线段树可以直接搞定;但有时无法通过直接划分区间来求解,如频繁询问区间第k小元素,当然,此问题有比较特殊的数据结构-划分树。其实还有一个叫做归并树,是根据归并排序实现的,每个节点保存的是该区间归并排序后的序列,因此,时间、空间复杂度都及其高, 所以一般不推荐去用。当然,主席树也是可以解决的。
#include
#include
#include
#include
using namespace std;
const int N = 100000 + 5;
vectornode[N << 2];
int T, n, q, ql, qr, ans, k, sz;
int a[N], b[N];
inline int read(){//快速读入是邪教
char c;
int ret = 0;
int sgn = 1;
do{c = getchar();}while((c < '0' || c > '9') && c != '-');
if(c == '-') sgn = -1; else ret = c - '0';
while((c = getchar()) >= '0' && c <= '9') ret = ret * 10 + (c - '0');
return sgn * ret;
}
void Build(int o, int l, int r){
node[o].clear();
if(l == r){
node[o].push_back(a[l]);
return ;
}
int m = (l + r) >> 1;
Build(o << 1, l, m);
Build(o << 1|1, m + 1, r);
node[o].resize(r - l + 1);
merge(node[o<<1].begin(), node[o<<1].end(), node[o<<1|1].begin(), node[o<<1|1].end(), node[o].begin());
}
int query(int o, int l, int r, int x){
//if(ql > r || qr < l) return 0;
if(ql <= l && qr >= r) return upper_bound(node[o].begin(), node[o].end(), x) - node[o].begin();
int m = (l + r) >> 1;
int ret = 0;
if(ql <= m)ret += query(o << 1, l, m, x);
if(qr > m)ret += query(o << 1|1, m + 1, r, x);
return ret;
}
void work(){
//ql = read();
//qr = read();
//k = read();
scanf("%d%d%d", &ql, &qr, &k);
int lt = 1, rt = sz;
while(lt <= rt){
int md = (lt + rt) >> 1;
if(query(1, 1, n, b[md]) >= k)rt = md - 1;
else lt = md + 1;
}
printf("%d\n", b[rt+1]);
}
int main(){
scanf("%d", &T);
while(T--){
scanf("%d%d", &n, &q);
//n = read();
//q = read();
//for(int i = 1; i <= n; i ++) a[i] = b[i] = read();
for(int i = 1; i <= n; i ++)scanf("%d", a + i), b[i] = a[i];
Build(1, 1, n);
sort(b + 1, b + n + 1);
sz = unique(b + 1, b + n + 1) - (b + 1);
while(q --)work();
}
return 0;
}
主席树的每个节点对应一颗线段树,此处有点抽象。在我们的印象中,每个线段树的节点维护的树左右子树下标以及当前节点对应区间的信息(信息视具体问题定)。对于一个待处理的序列a[1]、a[2]…a[n],有n个前缀。每个前缀可以看做一棵线段树,共有n棵线段树;若不采用可持久化结构,带来的严重后果就是会MLE,即对内存来说很难承受。根据可持久化数据结构的定义,由于相邻线段树即前缀的公共部分很多,可以充分利用,达到优化目的,同时每棵线段树还是保留所有的叶节点只是较之前共用了很多共用节点。主席树很重要的操作就是如何寻找公用的节点信息,这些可能可能出现在根节点也可能出现在叶节点。
下面是某大牛的理解:所谓主席树呢,就是对原来的数列[1…n]的每一个前缀[1…i](1≤i≤n)建立一棵线段树,线段树的每一个节点存某个前缀[1…i]中属于区间[L…R]的数一共有多少个(比如根节点是[1…n],一共i个数,sum[root] = i;根节点的左儿子是[1…(L+R)/2],若不大于(L+R)/2的数有x个,那么sum[root.left] = x)。若要查找[i…j]中第k大数时,设某结点x,那么x.sum[j] - x.sum[i - 1]就是[i…j]中在结点x内的数字总数。而对每一个前缀都建一棵树,会MLE,观察到每个[1…i]和[1…i-1]只有一条路是不一样的,那么其他的结点只要用回前一棵树的结点即可,时空复杂度为O(nlogn)。
我自己对主席树的理解,是一个线段树在修改一个值的时候,它只要修改logn个节点就可以了,那么我们只要每次增加logn个节点就可以记录它原来的状态了, 即你在更新一个值的时候仅仅只是更新了一条链,其他的节点都相同,即达到共用。由于主席树每棵节点保存的是一颗线段树,维护的区间相同,结构相同,保存的信息不同,因此具有了加减性。(这是主席树关键所在,当除笔者理解了很久很久,才相通的),所以在求区间的时候,若要处区间[l, r], 只需要处理rt[r] - rt[l-1]就可以了,(rt[l-1]处理的是[1,l-1]的数,rt[r]处理的是[1,r]的数,相减即为[l, r]这个区间里面的数。
比如说(以区间第k大为例hdu2665题目戳这里http://acm.hdu.edu.cn/showproblem.php?pid=2665):
设n = 4,q= 1;
4个数分别为4, 1, 3 ,2;
ql = 1, qr = 3, k = 2;
1.建树
首先需要建立一棵空的线段树,也是最原始的主席树,此时主席树只含一个空节点,此时设根节点为rt[0],表示刚开始的初值状态,然后依次对原序列按某种顺序更新,即将原序列加入到对应位置。此过程与线段树一样,时间复杂度为O(nlogn),空间复杂度O(nlog(n))(笔者目前没有完全搞清究竟是多少, 不过保守情况下,线段树不会超过4*n)
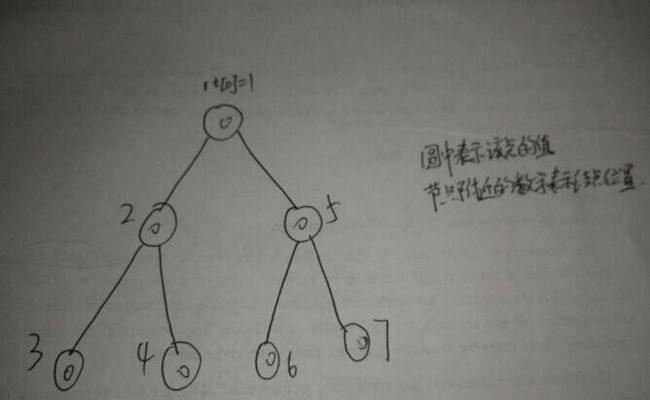
2.更新
我们知道,更新一个叶节点只会影响根节点到该叶节点的一条路径,故只需修改该路径上的信息即可。每个主席树的节点即每棵线段树的结构完全相同,只是对应信息(可以理解为线段树的结构完全一样,只是对应叶子节点取值不同,从而有些节点的信息不同,本质是节点不同),此时可以利用历史状态,即利用相邻的上一棵线段树的信息。相邻两颗线段树只有当前待处理的元素不同,其余位置完全一样。因此,如果待处理的元素进入线段树的左子树的话,右子树是完全一样的,可以共用,即直接让当前线段树节点的右子树指向相邻的上一棵线段树的右子树;若进入右子树,情况可以类比。此过程容易推出时间复杂度为O(logn),空间复杂度为 O(logn)。如图:

3.查询
先附上处理好之后的主席树, 如图:
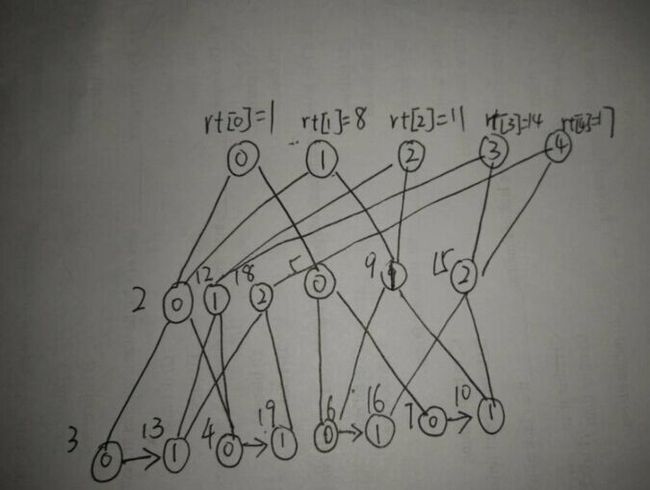
是不是看着很晕。。。。。。笔者其实也晕了,我们把共用的节点拆开来,看下图:
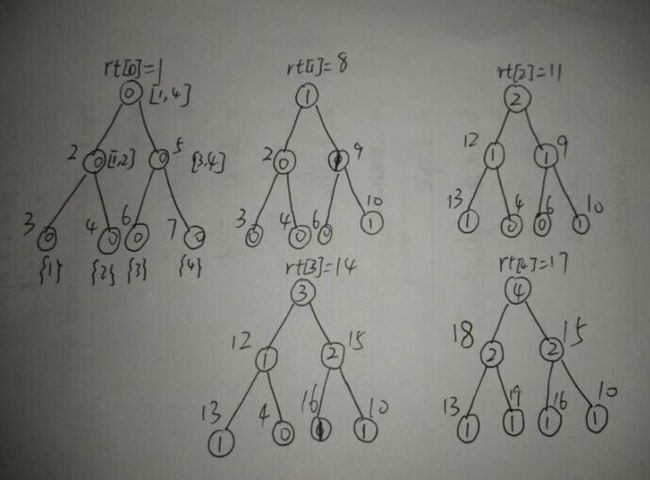
啊, 这下清爽多了,一眼看下去就知道每个节点维护的是哪棵线段树了,TAT,如果早就这样写估计很快就明白了,rt[i]表示处理完前i个数之后所形成的线段树,即具有了前缀和的性质,那么rt[r] - rt[l-1]即表示处理的[l, r]区间喽。当要查询区间[1,3]的时候,我们只要将rt[3] 和 rt[0]节点相减即可得到。如图:
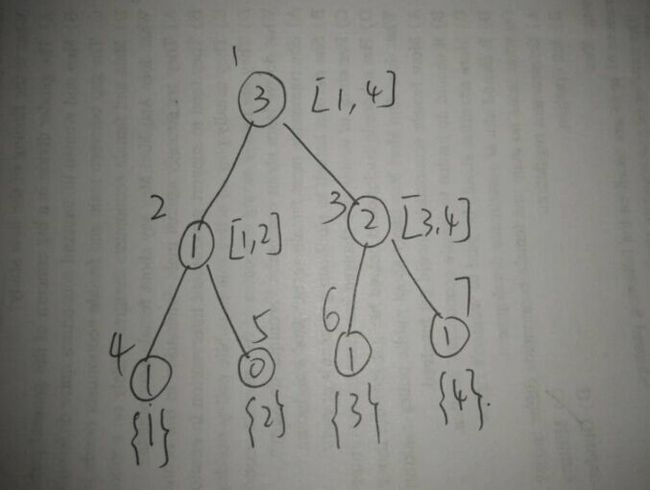
这样我们得到区间[l, r]的数要查询第k大便很容易了,设左节点中存的个数为cnt,当k<=cnt时,我们直接查询左儿子中第k小的数即可,如果k>cnt,我们只要去查右儿子中第k-cnt小的数即可,这边是一道很简单的线段树了。就如查找[1, 3]的第2小数(图上为了方便,重新给节点标号),从根节点1向下搜,发现左儿子2的个数为1,1<2,所有去右儿子3中搜第2-1级第1小的数,然后再往下搜,发现左儿子6便可以了,此时已经搜到底端,所以直接返回节点6维护的值3即可就可以了。
#include
#include
#include
using namespace std;
const int N = 100000 + 5;
int a[N], b[N], rt[N * 20], ls[N * 20], rs[N * 20], sum[N * 20];
int n, k, tot, sz, ql, qr, x, q, T;
void Build(int& o, int l, int r){
o = ++ tot;
sum[o] = 0;
if(l == r) return;
int m = (l + r) >> 1;
Build(ls[o], l, m);
Build(rs[o], m + 1, r);
}
void update(int& o, int l, int r, int last, int p){
o = ++ tot;
ls[o] = ls[last];
rs[o] = rs[last];
sum[o] = sum[last] + 1;
if(l == r) return;
int m = (l + r) >> 1;
if(p <= m) update(ls[o], l, m, ls[last], p);
else update(rs[o], m + 1, r, rs[last], p);
}
int query(int ss, int tt, int l, int r, int k){
if(l == r) return l;
int m = (l + r) >> 1;
int cnt = sum[ls[tt]] - sum[ls[ss]];
if(k <= cnt) return query(ls[ss], ls[tt], l, m, k);
else return query(rs[ss], rs[tt], m + 1, r, k - cnt);
}
void work(){
scanf("%d%d%d", &ql, &qr, &x);
int ans = query(rt[ql - 1], rt[qr], 1, sz, x);
printf("%d\n", b[ans]);
}
int main(){
scanf("%d", &T);
while(T--){
scanf("%d%d", &n, &q);
for(int i = 1; i <= n; i ++) scanf("%d", a + i), b[i] = a[i];
sort(b + 1, b + n + 1);
sz = unique(b + 1, b + n + 1) - (b + 1);
tot = 0;
Build(rt[0],1, sz);
//for(int i = 0; i <= 4 * n; i ++)printf("%d,rt = %d,ls = %d, rs = %d, sum = %d\n", i, rt[i], ls[i], rs[i], sum[i]);
for(int i = 1; i <= n; i ++)a[i] = lower_bound(b + 1, b + sz + 1, a[i]) - b;
for(int i = 1; i <= n; i ++)update(rt[i], 1, sz, rt[i - 1], a[i]);
for(int i = 0; i <= 5 * n; i ++)printf("%d,rt = %d,ls = %d, rs = %d, sum = %d\n", i, rt[i], ls[i], rs[i], sum[i]);
while(q --)work();
}
return 0;
}
看着这个时间的复杂度和归并树一比,从此对归并树无爱了,估计不会再用了。。。。ORZ~~
4.总结
由以上可知,主席树是一种特殊的线段树集,他几乎具有所有线段树的所有优势,并且可以保存历史状态,以便以后加以利用,主席树查找和更新时时间空间复杂度均为O(logn), 且空间复杂度约为O(nlogn + nlogn)前者为空树的空间复杂度,后者为更新n次的空间复杂度,主席树的缺点就是空间耗损巨大,但还是可以接受的。当然主席树不止这点应用,他可以处理许多区间问题,例如求区间[l, r]中的值介于[x,y]的值。总之应用多多。
转自:点击打开链接
主席树真是神奇的物种!
Orz一篇资料
题意:给n、m
下面有n个数 (编号1到n)
有m个询问,询问的是上面的数的编号在[l,r]之间第k小的数
n、m的范围都是
是主席树的入门题
借此来学习一下主席树
主席数利用函数式线段树来维护数列,一般用来解决区间第k大问题
空间时间的复杂度小于树套树(常数小)
划分树也可以解决区间第k大问题,但划分树不支持修改,主席树可以(用树状数组维护)
(这三道入门题都是无修改的)
我们先来YY一下这种求区间第k(大)小的题目···
最容易想到的做法就是对于每个询问,对[l, r]区间排个序,输出第k小
这样的复杂度是O()![]()
![]()
![]()
大家都很容易想到排序,但是对于每个询问每个区间排序的代价太大了...
再想想,让我们加入一些线段树的思想,
要求第k小,也就是与个数相关,那么我们可以 以[l,r]区间内的数的个数来建立一棵线段树
结点的值是数的个数,当我们要找第k小的数时,若左子树大于k,那么很显然第k小的数在左子树中;若左子树小于k,那么第k小的数在右子树中
建树的复杂度是O(nlogN),查询的复杂度是O(logN) (这里的N是不相同数的数量)
若我们仍对每个查询建树,那么复杂度丝毫没有降低(反而提高了),那有没有什么办法可以不要每次查询都建树呢?
(让我们联想一下前缀和) 假设我们知道[1, l-1]之间有多少个数比第k小的数小,那么我们只要减去这些数之后在[1, r]区间内第k小的数即是[l, r]区间内的第k小数
更确切的说,我们要求[l, r]区间内的第k小数 可以 用以[1, r]建立的线段树去减去以[1, l-1] 建立的线段树
这样能够减的条件是这两棵树必须是同构的。
若是不太明白, 我们来举个例子:
如有序列 1 2 5 1 3 2 2 5 1 2
我们要求 [5,10]第5小的数
(数列中不存在4、6、7、8 但根据原理就都写出来了,为方便理解,去掉了hash的步骤,实际的代码中其实只要一棵4个叶子节点的树即可)
(红色的为个数)
我们建立的[1, l-1] (也就是[1, 4])之间的树为

[1, r]也就是[1, 10]的树为
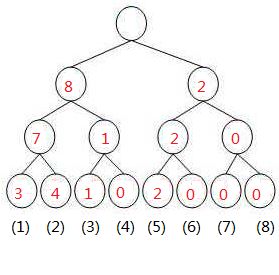
两树相减得到
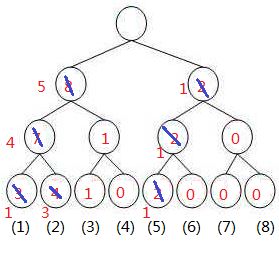
我们来找第5小的数:
发现左子树为5 所以第5小的数在左边, 再往下(左4右1) 发现左边小于5了 ,所以第5小的数在右边 所以第5小的数就是3了
同样的,我们只要建立[1, i] (i是1到n之间的所有值)的所有树,每当询问[l, r]的时候,只要用[1, r]的树减去[1, l-1]的树,再找第k小就好啦
我们将这n个树看成是建立在一个大的线段树里的,也就是这个线段树的每个节点都是一个线段树( ——这就是主席树)
最初所有的树都是空树,我们并不需要建立n个空树,只要建立一个空树,也就是不必每个节点都建立一个空树
插入元素时,我们不去修改任何的结点,而是返回一个新的树( ——这就是函数式线段树)
因为每个节点都不会被修改,所以可以不断的重复用,因此插入操作的复杂度为O(logn)
总的复杂度为O((n+m)lognlogN) (听说 主席树的芭比说 加上垃圾回收, 可以减少一个log~~~ 然而这只是听说)
你以为这样就结束了吗!!
你没有发现这样空间大到爆炸吗!!!
你在每个节点都建了一个线!段!树!这不MLE才有鬼呢!!!
那怎么办呢?
表示一棵[1, i]区间的线段树
那么与的区别就只有当前插入的这个元素以及它的父亲以及他父亲的父亲以及他父亲的父亲的父亲...
也就是改变的就只有他和他上面logn个数
所以,我们并不需要建一整棵树,我们只需要 单独建立logn个结点,跟连起来就好了
这样树的空间复杂度(NlogN) 以下是代码:
#include
#include
#include
#include
using namespace std;
const int MM=100010;
int node,n,m;
int sum[MM*20],rt[MM],lc[MM*20],rc[MM*20];
int a[MM],b[MM];
int p;
void build(int t,int l,int r)//建树
{
t=++node;
if(l==r)
return;
int mid=((l+r)>>1);
build(lc[t],l,mid);
build(rc[t],mid+1,r);
}
int update(int o,int l,int r)//更新
{
int rt=++node;
lc[rt]=lc[o];
rc[rt]=rc[o];
sum[rt]=sum[o]+1;
if(l==r)
return rt;
int mid=((l+r)>>1);
if(p<=mid)
lc[rt]=update(lc[rt],l,mid);
else
rc[rt]=update(rc[rt],mid+1,r);
return rt;
}
int query(int u,int v,int l,int r,int k)//查询
{
int ans,mid=((l+r)>>1),x=sum[lc[v]]-sum[lc[u]];//前缀和
if(l==r)
return l;
if(x>=k)//说明在左子树
ans=query(lc[u],lc[v],l,mid,k);//
else
ans=query(rc[u],rc[v],mid+1,r,k-x);
return ans;
}
int main()
{
int w;
scanf("%d",&w);
while(w--)
{
scanf("%d%d",&n,&m);
for(int i=1; i<=n; i++)
{
scanf("%d",&a[i]);
b[i]=a[i];
}
sort(b+1,b+n+1);//离散化
int q=unique(b+1,b+n+1)-b-1;//
build(rt[0],1,q);
for(register int i=1; i<=n; i++)
{
p=lower_bound(b+1,b+q+1,a[i])-b;//二分
rt[i]=rt[i-1];
rt[i]=update(rt[i],1,q);
}
int l,r,k,ans;
while(m--)
{
scanf("%d%d%d",&l,&r,&k);
ans=query(rt[l-1],rt[r],1,q,k);
printf("%d\n",b[ans]);
}
}
return 0;
}
题意:n个数,q个询问 (n<=50000, q<=10000)
Q x y z 代表询问[x, y]区间里的第z小的数
C x y 代表将(从左往右数)第x个数变成y
上篇介绍了在[x, y]区间内查询第z小的数的方法(静态主席树)
本题有更新操作
若仍用上篇的做法,
每次更新一个数,需要更新的是T[i], T[i+1]... ...T[n](该数所在的树以及它后面的所有树)
因为每棵树T[i]所记录的都是前缀(1到i的数出现的次数) 因此,改变i,会影响i到n的所有树
这样,每次更新的复杂度最坏为O(),最坏更新q次即为O() 复杂度相当庞大,很明显这样做是不行的
那怎么办呢?
我们可以发现,对于改变i处的数这个操作,对于T[i], T[i+1]... ...T[n]这些树的影响是相同的
都只改变了 “原来i处的数 的数量” 和 “现在i处的数 的数量” 这两个值而已
我们只要在原来的基础上增加一类树, 用它们来维护更新掉的数
即用树状数组来记录更新,每次更新棵树
下面来演示一下建树到查询的过程:
比如此题的第一个案例
5 3
3 2 1 4 7
Q 1 4 3
C 2 6
Q 2 5 3
先将序列以及要更新的数(C操作)离散化
即3 2 1 4 7 、 6 ---->(排序) ----> 1 2 3 4 6 7
那么我们就需要建一棵这样的树: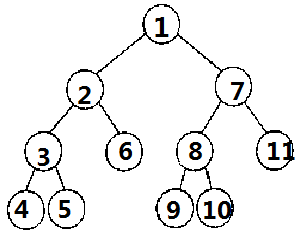
(圈里的都是结点的编号, 4、5、6、9、10、11号结点代表的分别是1、2、3、4、6、7)
(4、5、9、10你也可以任意作为6或11的儿子, 递归生成的是类似这样的, 这并不重要)
对于3 2 1 4 7(先不管需要更新的6)建完树见下图(建树过程同静态的,不明白的戳这里,上篇博客有讲)

(红色的是个数, 相同结点的个数省略了,同前一棵树)
对于C操作之前的Q,就跟静态的类似,减一减 找就好了
然后下面要更新了
对于更新, 我们不改变这些已经建好的树, 而是另建一批树S,用来记录更新,而这批线段树,我们用树状数组来维护
也就是树状数组的每个节点都是一颗线段树
一开始,S[0]、S[1]、S[2]、S[3]、S[4]、S[5](树状数组的每个节点)这些都与T[0]相同(也就是每个节点建了一棵空树)
对于C 2 6 这个操作, 我们只需要减去一个2,加上一个6即可
对于减去2
(树状数组i+lowbit(i)为i的父亲节点, 修改i,就要把i的所有父亲节点都修改了)
2在树状数组中出现的位置是 2、2+lowbit(2)=4 这两个位置,
因此要更新的是S[2]和S[4]这两个节点中的树
删去2后是这样

加上一个6 (同样是对于2号位置, 因此需要更新的仍是S[2]和S[4])
加上之后是这样

当查询的时候, 对树T的操作与静态的一致,另外再加上S树的值就好了
#include
using namespace std;
typedef long long LL;
#define lson l, m
#define rson m+1, r
const int N=60005;
int a[N], Hash[N];
int T[N], L[N<<5], R[N<<5], sum[N<<5];
int S[N];
int n, m, tot;
struct node
{
int l, r, k;
bool Q;
}op[10005];
int build(int l, int r)
{
int rt=(++tot);
sum[rt]=0;
if(l!=r)
{
int m=(l+r)>>1;
L[rt]=build(lson);
R[rt]=build(rson);
}
return rt;
}
int update(int pre, int l, int r, int x, int val)
{
int rt=(++tot);
L[rt]=L[pre], R[rt]=R[pre], sum[rt]=sum[pre]+val;
if(l>1;
if(x<=m)
L[rt]=update(L[pre], lson, x, val);
else
R[rt]=update(R[pre], rson, x, val);
}
return rt;
}
int lowbit(int x)
{
return x&(-x);
}
int use[N];
void add(int x, int pos, int val)
{
while(x<=n)
{
S[x]=update(S[x], 1, m, pos, val);
x+=lowbit(x);
}
}
int Sum(int x)
{
int ret=0;
while(x>0)
{
ret+=sum[L[use[x]]];
x-=lowbit(x);
}
return ret;
}
int query(int u, int v, int lr, int rr, int l, int r, int k)
{
if(l>=r)
return l;
int m=(l+r)>>1;
int tmp=Sum(v)-Sum(u)+sum[L[rr]]-sum[L[lr]];
if(tmp>=k)
{
for(int i=u;i;i-=lowbit(i))
use[i]=L[use[i]];
for(int i=v;i;i-=lowbit(i))
use[i]=L[use[i]];
return query(u, v, L[lr], L[rr], lson, k);
}
else
{
for(int i=u;i;i-=lowbit(i))
use[i]=R[use[i]];
for(int i=v;i;i-=lowbit(i))
use[i]=R[use[i]];
return query(u, v, R[lr], R[rr], rson, k-tmp);
}
}
void modify(int x, int p, int d)
{
while(x<=n)
{
S[x]=update(S[x], 1, m, p, d);
x+=lowbit(x);
}
}
int main()
{
int t;
scanf("%d", &t);
while(t--)
{
int q;
scanf("%d%d", &n, &q);
tot=0;
m=0;
for(int i=1;i<=n;i++)
{
scanf("%d", &a[i]);
Hash[++m]=a[i];
}
for(int i=0;i