python编程读取wav文件数据
主要功能
命令行传参,输入语音文件,对wav文件进行解析,得到语音数据,同时将数据保存到命令行输入的文件中,也可将数据打印到屏幕上。
将输入文件xxx.wav语音文件的采样数据读出保存在文本文件yyy.txt中。如无-o项则输出到屏幕上。如果是双声道数据,输入-l,打印左声道数据,输入-r,打印右声道数据,如果输入-a或者不输入,打印双声道数据。如果为单声道数据,则直接打印。使用python编程实现。
程序
#将wav语音文件转化为数据文件
# -*- coding: utf-8 -*-
import numpy as np
import sys
import wave #语音文件处理包
import getopt
def main(argv): #定义一个函数
try: #首先执行try后的程序,如果输入格式不对,则执行except getopt.GetoptError:后的程序
opts, args = getopt.getopt(argv[1:], "i:o:lrah", ["input", "output","left","right","all","help"]) #命令行输入参数
except getopt.GetoptError:
print('输入参数错误,输入格式为:python wav2txt.py -i test.wav -o text3.txt -l/-r/-a,\n其中wav2txt.py为程序文件名称,test.wav为语音文件,text3.txt为.wav文件的数据保存到的文件,\n-l/-r/-a分别为左声道,右声道,双声道,对于单声道语音文件,最后这部分没必要加,但对双声道数据则可以分别保存左声道,右声道,或两个声道的数据')
sys.exit()
for opt, arg in opts:
if opt in ("-h", "--help"): #打印帮助
#test.wav为单声道语音文件,test2.wav为双声道语音文件
print('单声道:python wav2txt.py -i test.wav -o text3.txt')
print('打印双声道的左声道数据:python wav2txt.py -i test2.wav -o text3.txt -l')
print('打印双声道的右声道数据:python wav2txt.py -i test2.wav -o text3.txt -r')
print('打印双声道的数据:python wav2txt.py -i test2.wav -o text3.txt或者python wav2txt.py -i test2.wav -o text3.txt -a')
print('无-o项时输出到屏幕上:python wav2txt.py -i test2.wav' )
sys.exit()
#判断双声道的且输入参数中含有-l/-r/-a等的情况,包括左声道,右声道,和双声道
elif opt in ("-i", "--input"):
input = arg
#当未输入"-o"项时,将数据打印到屏幕上,【注意】:因语音文件数据较多,且每行只打印一个,谨慎使用
f = wave.open(input, 'rb') # 打开语音文件
params = f.getparams() # 得到语音参数
nchannels, sampwidth, framerate, nframes = params[:4] # 分别为声道数,量化位数,采样频率,采样点数
# print("wav params is :", params)
# print("声道数=", nchannels, "\t量化位数=", sampwidth, "\t采样频率=", framerate, "\t采样点数=", nframes)
data = f.readframes(nframes)
# 将字符串转换为数组,得到一维的short类型的数组
# data = np.fromstring(data, dtype=np.short)
data = np.frombuffer(data, dtype=np.short)
# 整合左声道和右声道的数据
data = np.reshape(data, [nframes, nchannels]) # 将采样数据规整为每行nchannels个数据,如果为单声道,每行一个数据,如果双声道,每行就两个数据
length = len(data) # 该段语音采样点个数
argc = len(sys.argv)
if argc == 3:
if nchannels == 1:
for i in range(length):
s = str(data[i, 0]).replace('[', ").replace('[',") # 去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
print(s)
# file.write(s) # 将语音采样数据写入文本文件中
#file.close() # 关闭输出文件
f.close() # 关闭输入的语音文件
exit()
if nchannels == 2:
for i in range(length):
s = str(data[i, 0]).replace('[', ").replace('[',") + ' ' + str(data[i, 1]).replace('[',
").replace('[',") # 去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
# file.write(s) # 将语音采样数据写入文本文件中
print(s)
# file.close() # 关闭输出文件
f.close() # 关闭输入的语音文件
exit()
elif opt in ("-o", "--output"):
output = arg
f = wave.open(input, 'rb') #打开语音文件
params = f.getparams() # 得到语音参数
nchannels, sampwidth, framerate, nframes = params[:4] #分别为声道数,量化位数,采样频率,采样点数
# print("wav params is :", params)
print("声道数=", nchannels, "\t量化位数=", sampwidth, "\t采样频率=", framerate, "\t采样点数=", nframes)
# open a txt file
file = open(output, 'w') #打开输出的txt文件
data = f.readframes(nframes)
# 将字符串转换为数组,得到一维的short类型的数组
#data = np.fromstring(data, dtype=np.short)
data = np.frombuffer(data, dtype=np.short)
# 整合左声道和右声道的数据
data = np.reshape(data, [nframes, nchannels]) #将采样数据规整为每行nchannels个数据,如果为单声道,每行一个数据,如果双声道,每行就两个数据
length=len(data)#该段语音采样点个数
#左声道j=0
elif opt in ("-l", "--left"): #表示保存左声道数据
if nchannels == 2:
for i in range(length):
s = str(data[i, 0]).replace('[', ").replace('[',") #去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) #将语音采样数据写入文本文件中
file.close() #关闭输出文件
f.close() #关闭输入的语音文件
exit()
elif nchannels==1:
print("为单声道语音文件,输入错误")
elif opt in ("-r", "--right"): #表示保存右声道数据
if nchannels == 2:
for i in range(length):
s = str(data[i, 1]).replace('[', ").replace('[',") #去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) #将语音采样数据写入文本文件中
file.close() #关闭输出文件
f.close() # 关闭输入的语音文件
exit()
elif nchannels==1:
print("为单声道语音文件,输入错误")
elif opt in ("-a", "--all"):
if nchannels==2:
for i in range(length):
#同时打印左右声道数据,中间空格分开
s = str(data[i, 0]).replace('[', ").replace('[',")+' '+str(data[i, 1]).replace('[', ").replace('[',") #去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) #将语音采样数据写入文本文件中
file.close() #关闭输出文件
f.close() # 关闭输入的语音文件
exit()#打印结束,退出
elif nchannels==1:
print("为单声道语音文件,输入错误")
#命令行输入时最后不带-l/-r/-a这些参数的情况
if nchannels == 1:
for i in range(length):
s = str(data[i, 0]).replace('[', ").replace('[',") #去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) #将语音采样数据写入文本文件中
file.close() #关闭输出文件
f.close() # 关闭输入的语音文件
exit()
if nchannels == 2:
for i in range(length):
s = str(data[i, 0]).replace('[', ").replace('[',") + ' ' + str(data[i, 1]).replace('[', ").replace('[',") #去除"[" 和 "]"
s = s.replace("'", ").replace(',',") + '\n' # 去除单引号,逗号,每行末尾追加换行符
file.write(s) #将语音采样数据写入文本文件中
file.close() #关闭输出文件
f.close() # 关闭输入的语音文件
exit()
if __name__ == "__main__":
# sys.argv[1:]为要处理的参数列表,sys.argv[0]为脚本名,所以用sys.argv[1:]过滤掉脚本名。
main(sys.argv) #调用函数
结果
参数错误:

查看帮助文档:
python wav2txt.py -h
结果:

1 当不输入-o项时,打印到屏幕上
单声道:
python wav2txt.py -i test.wav
屏幕打印结果:

双声道:
python wav2txt.py -i test2.wav
屏幕打印结果:
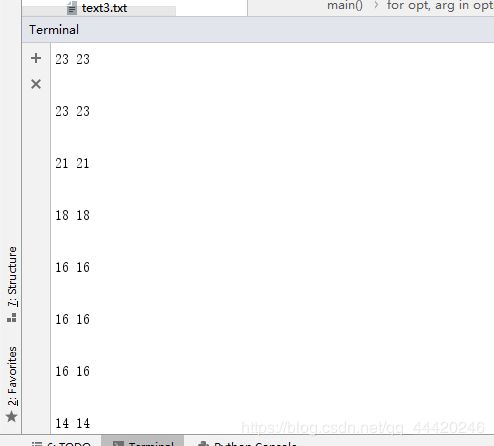
2 当输入-o项
-
当为单声道语音文件时:
python wav2txt.py -i test.wav -o text3.txt保存文件结果

-
双声道数据保存文件结果
左声道:
python wav2txt.py -i lantian2.wav -o text3.txt -l
右声道:
python wav2txt.py -i lantian2.wav -o text3.txt -r
左声道和右声道数据保存文件结果同单声道。
双声道:
python wav2txt.py -i lantian2.wav -o text3.txt -a
或者
python wav2txt.py -i lantian2.wav -o text3.txt
保存文件结果:


matab对比验证
使用matlab读入语音文件,得到数据,进行对比:
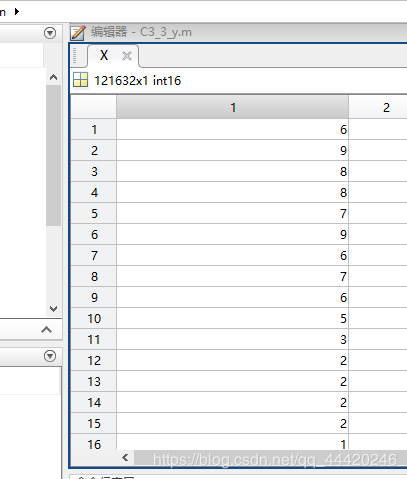
%单声道
[X,FS]=audioread('C:\Users\CL\Desktop\学习\python\wav\test.wav','native');
结果:
%双声道
[X,FS]=audioread('C:\Users\CL\Desktop\学习\python\wav\test2.wav','native');
结果:
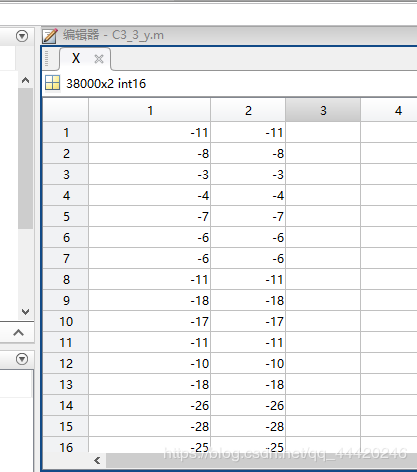
和python编程结果进行对比,结果正确。