爬取研招网招考信息
电子信息类考研科目
为了了解全国研究生院校电子系信息类专硕考察科目,特地开发一份爬虫程序将研招网的相关考试信息爬取下来,方便自己日后使用,也方便大家分析相关高校
文章目录
- 电子信息类考研科目
- 1.理清代码逻辑
- 2.请求并提取所需数据
- 3.MongoDB数据库存储数据
- 4.使用server酱微信消息提醒
- 5.代码分享
1.理清代码逻辑
找到全国所有省份的代号>>>找该省份所有的大学>>>找大学中所有电子信息相关专业>>>提取考察科目信息
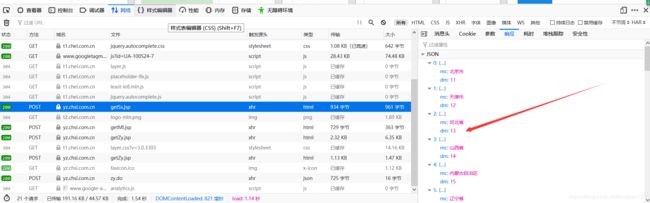
(1)通过网页接受的数据包分析各省份的对应的代码如下图,为了避免麻烦,我最终还是选择了手刃咱们全国的省份~~,大家也可以直接对下图获取的的json包做处理
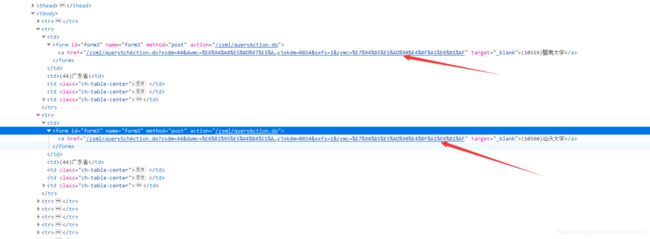
 (2)以搜索广东省的电子信息专业为例(如下图),数据并没有通过json包发送,而是院校的相对链接嵌在html代码中,于是得使用beatifulsoup去制作一锅汤~~,去寻找其中的珍品
(2)以搜索广东省的电子信息专业为例(如下图),数据并没有通过json包发送,而是院校的相对链接嵌在html代码中,于是得使用beatifulsoup去制作一锅汤~~,去寻找其中的珍品
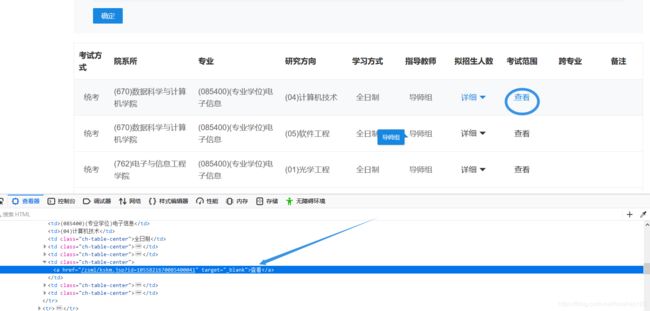
 (3)选取一所高校一探究竟,这个上一步如此的相似,数据也没有单独发包,都是嵌入在html页面中,这还是得再去制作一锅汤,不过这回得检查“查看”元素的源代码
(3)选取一所高校一探究竟,这个上一步如此的相似,数据也没有单独发包,都是嵌入在html页面中,这还是得再去制作一锅汤,不过这回得检查“查看”元素的源代码
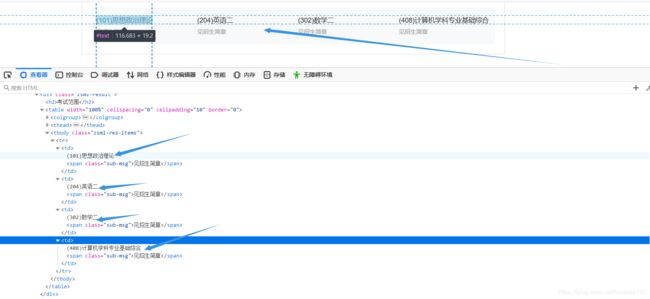
 (4)以院校的专业为例,进入页面查看相关考察科目,任然没有发现我需要的json包~~(大哥能不能体谅我们这种没怎么学html的同学),既然这样,那么咱们继续做汤呗
(4)以院校的专业为例,进入页面查看相关考察科目,任然没有发现我需要的json包~~(大哥能不能体谅我们这种没怎么学html的同学),既然这样,那么咱们继续做汤呗
 (5)接下来就是咱们安装以及使用MongoDB数据库了(这是一个我没有玩过的全新版本~~),为了操作,我也下载了他的可视化软件
(5)接下来就是咱们安装以及使用MongoDB数据库了(这是一个我没有玩过的全新版本~~),为了操作,我也下载了他的可视化软件
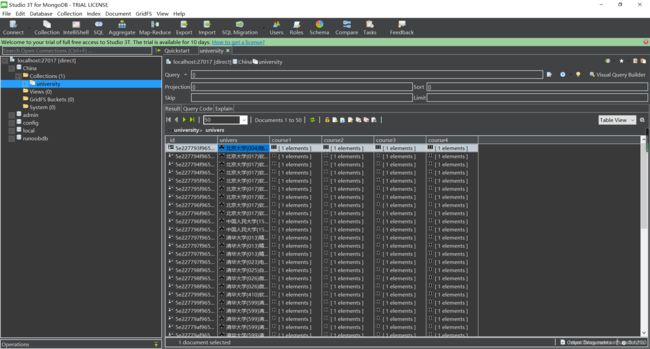
2.请求并提取所需数据
(1)爬取该省所有高校相对链接请求(如下图);对于爬虫程序,为了解决一些未知的错误,我选择try-except,这样不至于使程序因为一个小错误全程崩掉
 提取院校的相对链接;需要提取列表中所有的a标签的href属性
提取院校的相对链接;需要提取列表中所有的a标签的href属性
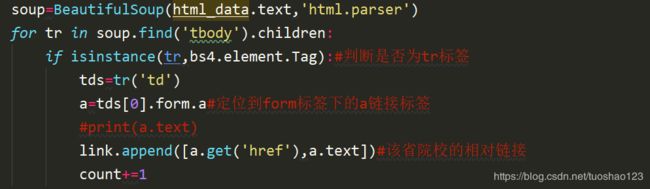 (2)拼接成院校完整链接,请求数据
(2)拼接成院校完整链接,请求数据
 提取院校专业的相对链接;
提取院校专业的相对链接;
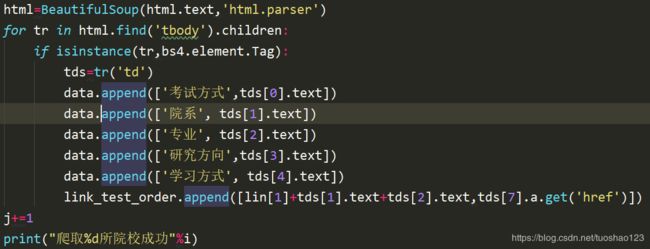 (3)拼接链接,请求个专业考察科目
(3)拼接链接,请求个专业考察科目

提取考察科目;
for tr in html_text.find_all('tbody',class_="zsml-res-items"):
#tr=tr.children
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
print("类型",type(tds[0]))
tds[0]=str(tds[0]).replace("\r\n","")
print("s类型",type(tds[0]))
tds[0]=tds[0].replace(" ","")
tds[1]=str(tds[1]).replace("\r\n","")
tds[1]=tds[1].replace(" ", "")
tds[2] = str(tds[2]).replace("\r\n","")
tds[2] = tds[2].replace(" ","")
tds[3] = str(tds[3]).replace("\r\n","")
tds[3] = tds[3].replace(" ", "")
con1 = Selector(text=tds[0])
con2 = Selector(text=tds[1])
con3 = Selector(text=tds[2])
con4 = Selector(text=tds[3])
#print(con1)
test_subject_data.append([con1.xpath("//td/text()").extract(),con2.xpath("//td/text()").extract(),con3.xpath("//td/text()").extract(),con4.xpath("//td/text()").extract()])
mydict={"univers":link_test_order[i][0],"course1":test_subject_data[i][0],"course2":test_subject_data[i][1],"course3":test_subject_data[i][2],"course4":test_subject_data[i][3]}
x = mycol.insert_one(mydict)
#print("test",test_subject_data)
print("正在爬取%s考试科目"%(link_test_order[i][0]))
3.MongoDB数据库存储数据
(1)连接本地数据数据库,并创建数据表
 (2)向表中插入数据
(2)向表中插入数据
mydict={"univers":link_test_order[i][0],"course1":test_subject_data[i][0],"course2":test_subject_data[i][1],"course3":test_subject_data[i][2],"course4":test_subject_data[i][3]}
x = mycol.insert_one(mydict)
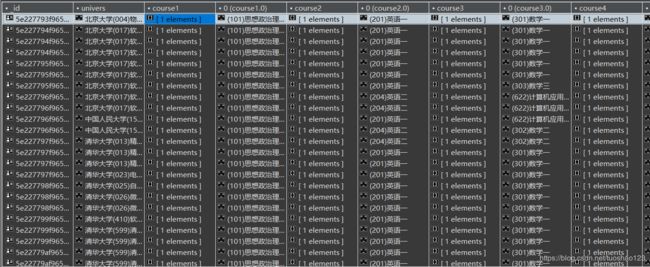
(3)爬取数据存储如下
4.使用server酱微信消息提醒
注册之后都会有key,原谅我打了马赛克,server酱注册地址
![]()
5.代码分享
import requests
import bs4
from bs4 import BeautifulSoup
from scrapy import Selector
import pymongo
import time
#连接数据库
myclient=pymongo.MongoClient("mongodb://localhost:27017/")
mydb=myclient["China"]
mycol=mydb["university"]
dblist=myclient.list_database_names()
code_university=[[11,"北京市"],
[12,"天津市"],
[13,"河北省"],
[14,"山西省"],
[15,"内蒙古自治区"],
[21,"辽宁省"],
[22,"吉林省"],
[23,"黑龙江省"],
[31,"上海市"],
[32,"江苏省"],
[33,"浙江省"],
[34,"安徽省"],
[35,"福建省"],
[36,"江西省"],
[37,"山东省"],
[41,"河南省"],
[42,"湖北省"],
[43,"湖南省"],
[44,"广东省"],
[45,"广西壮族自治区"],
[46,"海南省"],
[50,"重庆市"],
[51,"四川省"],
[52,"贵州省"],
[53,"云南省"],
[54,"西藏自治区"],
[61,"陕西省"],
[62,"甘肃省"],
[63,"青海省"],
[64,"宁夏回族自治区"],
[65,"新疆维吾尔族自治区"]
]
chrome_info={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0'}
#配置表单信息
form_data={'ssdm':'','dwmc':'','mldm':'zyxw','mlmc':'','yjxkdm':'0854','zymc':'电子信息','xxfs':''}
base_url='https://yz.chsi.com.cn'
#爬取该省所有研究生院校的数据
def get_Us_data(form_data1,i):
try:
#post
html_data=requests.post('https://yz.chsi.com.cn/zsml/queryAction.do',headers=chrome_info,data=form_data1)
print("正在爬取%s所有研究生院校链接"%code_university[i][1])
except:
print("请求高校数据出错")
#提取该省所有高校链接地址
count=0
link=[]
soup=BeautifulSoup(html_data.text,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#判断是否为tr标签
tds=tr('td')
a=tds[0].form.a#定位到form标签下的a链接标签
#print(a.text)
link.append([a.get('href'),a.text])#该省院校的相对链接
count+=1
print(count)
return link
def get_thisUniversity_data(link):
# post表单信息
data=[]#存储爬取的数据
j=0
link_test_order=[]
#print("分割大学名称、序号中")
for i in range(len(link)):
try:
lin=link[i][1].split(')')
form_data1={'ssdm':form_data['ssdm'],'dwmc':lin[1],'mldm':form_data['mldm'],'mlmc':form_data['mlmc'],'yjxkdm':form_data['yjxkdm'],'xxfs':form_data['xxfs'],'zymc':form_data['zymc']}
Url=base_url+link[i][0]
html=requests.post(Url,headers=chrome_info,data=form_data1)
html=BeautifulSoup(html.text,'html.parser')
for tr in html.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
data.append(['考试方式',tds[0].text])
data.append(['院系', tds[1].text])
data.append(['专业', tds[2].text])
data.append(['研究方向',tds[3].text])
data.append(['学习方式', tds[4].text])
link_test_order.append([lin[1]+tds[1].text+tds[2].text,tds[7].a.get('href')])
j+=1
print("爬取%d所院校成功"%i)
except:
print("爬取%s数据失败",link[i][1])
print("该省共%d个相关专业"%len(link_test_order))
return link_test_order
#请求各院校各专业的考试信息数据
def get_test_order(link_test_order):
test_subject_data=[]
for i in range(len(link_test_order)):
Url = base_url + link_test_order[i][1]
html = requests.get(Url, headers=chrome_info)
html_text=BeautifulSoup(html.text,'html.parser')
for tr in html_text.find_all('tbody',class_="zsml-res-items"):
#tr=tr.children
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
print("类型",type(tds[0]))
tds[0]=str(tds[0]).replace("\r\n","")
print("s类型",type(tds[0]))
tds[0]=tds[0].replace(" ","")
tds[1]=str(tds[1]).replace("\r\n","")
tds[1]=tds[1].replace(" ", "")
tds[2] = str(tds[2]).replace("\r\n","")
tds[2] = tds[2].replace(" ","")
tds[3] = str(tds[3]).replace("\r\n","")
tds[3] = tds[3].replace(" ", "")
con1 = Selector(text=tds[0])
con2 = Selector(text=tds[1])
con3 = Selector(text=tds[2])
con4 = Selector(text=tds[3])
#print(con1)
test_subject_data.append([con1.xpath("//td/text()").extract(),con2.xpath("//td/text()").extract(),con3.xpath("//td/text()").extract(),con4.xpath("//td/text()").extract()])
mydict={"univers":link_test_order[i][0],"course1":test_subject_data[i][0],"course2":test_subject_data[i][1],"course3":test_subject_data[i][2],"course4":test_subject_data[i][3]}
x = mycol.insert_one(mydict)
#print("test",test_subject_data)
print("正在爬取%s考试科目"%(link_test_order[i][0]))
if __name__=="__main__":
for i in range(len(code_university)):
code=code_university[i][0]
form_data['ssdm']=code
#请求该省高校相对链接数据数据
link=get_Us_data(form_data,i)
#请求高校专业、方向数据
link_test_order=get_thisUniversity_data(link)
#爬取各专业具体考试科目
get_test_order(link_test_order)
time.sleep(5)
url = "https://sc.ftqq.com/你们自己的key.send?text=爬取大学结束~"
re = requests.get(url)
#数据存储