SLUB
slub把内存分组管理,每个组分别包含2^3、2^4、...2^11个字节,在4K页大小的默认情况下,另外还有两个特殊的组,分别是96B和192B,共11组。之所以这样分配是因为如果申请2^12B大小的内存,就可以使用伙伴系统提供的接口直接申请一个完整的页面即可。
slub就相当于零售商,它向伙伴系统“批发”内存,然后在零售出去。一下是整个slub系统的框图:
一切的一切源于kmalloc_caches[12]这个数组,该数组的定义如下:
struct kmem_cache kmalloc_caches[PAGE_SHIFT] __cacheline_aligned;
每个数组元素对应一种大小的内存,可以把一个kmem_cache结构体看做是一个特定大小内存的零售商,整个slub系统中共有12个这样的零售商,每个“零售商”只“零售”特定大小的内存,例如:有的“零售商”只"零售"8Byte大小的内存,有的只”零售“16Byte大小的内存。
每个零售商(kmem_cache)有两个“部门”,一个是“仓库”:kmem_cache_node,一个“营业厅”:kmem_cache_cpu。“营业厅”里只保留一个slab,只有在营业厅(kmem_cache_cpu)中没有空闲内存的情况下才会从仓库中换出其他的slab。
所谓slab就是零售商(kmem_cache)批发的连续的整页内存,零售商把这些整页的内存分成许多小内存,然后分别“零售”出去,一个slab可能包含多个连续的内存页。slab的大小和零售商有关。
相关数据结构:
物理页按照对象(object)大小组织成单向链表,对象大小时候objsize指定的。例如16字节的对象大小,每个object就是16字节,每个object包含指向下一个object的指针,该指针的位置是每个object的起始地址+offset。每个object示意图如下:
void*指向的是下一个空闲的object的首地址,这样object就连成了一个单链表。
向slub系统申请内存块(object)时:slub系统把内存块当成object看待
- slub系统刚刚创建出来,这是第一次申请。
此时slub系统刚建立起来,营业厅(kmem_cache_cpu)和仓库(kmem_cache_node)中没有任何可用的slab可以使用,如下图中1所示:
因此只能向伙伴系统申请空闲的内存页,并把这些页面分成很多个object,取出其中的一个object标志为已被占用,并返回给用户,其余的object标志为空闲并放在kmem_cache_cpu中保存。kmem_cache_cpu的freelist变量中保存着下一个空闲object的地址。上图2表示申请一个新的slab,并把第一个空闲的object返回给用户,freelist指向下一个空闲的object。 - slub的kmem_cache_cpu中保存的slab上有空闲的object可以使用。
这种情况是最简单的一种,直接把kmem_cache_cpu中保存的一个空闲object返回给用户,并把freelist指向下一个空闲的object。 - slub已经连续申请了很多页,现在kmem_cache_cpu中已经没有空闲的object了,但kmem_cache_node的partial中有空闲的object 。所以从kmem_cache_node的partial变量中获取有空闲object的slab,并把一个空闲的object返回给用户。
上图中,kmem_cache_cpu中已经都被占用的slab放到仓库中,kmem_cache_node中有两个双链表,partial和full,分别盛放不满的slab(slab中有空闲的object)和全满的slab(slab中没有空闲的object)。然后从partial中挑出一个不满的slab放到kmem_cache_cpu中。
上图中,kmem_cache_cpu中中找出空闲的object返回给用户。 - slub已经连续申请了很多页,现在kmem_cache_cpu中保存的物理页上已经没有空闲的object可以使用了,而此时kmem_cache_node中没有空闲的页面了,只能向内存管理器(伙伴算法)申请slab。并把该slab初始化,返回第一个空闲的object。
上图表示,kmem_cache_node中没有空闲的object可以使用,所以只能重新申请一个slab。
把新申请的slab中的一个空闲object返回给用户使用,freelist指向下一个空闲object。
向slub系统释放内存块(object)时,如果kmem_cache_cpu中缓存的slab就是该object所在的slab,则把该object放在空闲链表中即可,如果kmem_cache_cpu中缓存的slab不是该object所在的slab,然后把该object释放到该object所在的slab中。在释放object的时候可以分为一下三种情况:
- object在释放之前slab是full状态的时候(slab中的object都是被占用的),释放该object后,这是该slab就是半满(partail)的状态了,这时需要把该slab添加到kmem_cache_node中的partial链表中。
- slab是partial状态时(slab中既有object被占用,又有空闲的),直接把该object加入到该slab的空闲队列中即可。
- 该object在释放后,slab中的object全部是空闲的,还需要把该slab释放掉。
这一步产生一个完全空闲的slab,需要把这个slab释放掉。
slab思想
摘抄《深入linux设备驱动程序内核机制》的一段话:slab分配器的基本思想是,先利用页面分配器分配出单个或者一组连续的物理页面,然后在此基础上将整块页面分割成多个相等的小内存单元,以满足小内存空间分配的需要。当然,为了有效的管理这些小的内存单元并保证极高的内存使用速度和效率。
slab分配器结构
首先看下一张图,这是一张非常经典的图(所以也是从别的地方截取过来的,哈哈)基本上讲slab的都会上这张图(有些图可能会有点点不同,不过都是大同小异)
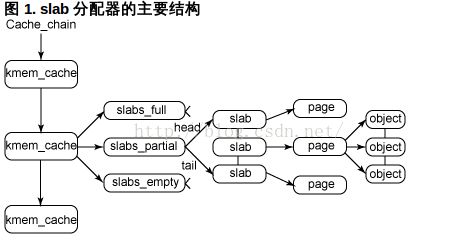
这是有struct kmem_cache 和 struct slab构成的slab分配器;
从大方向来说,每个kmem_cache都是链接在一起形成一个全局的双向链表,由cache指向该链表,系统可以从Cache_chain开始扫描每个kmem_cache,来找到一个大小最合适的kmem_cache,然后从该kmem_cache中分配一个对象;
其中每个kmem_cache(有的地方也会叫这个kmem_cache为cache,原因是kmem_cache中的object有大有小(其实也是kmem_cache有大有小),当内存申请时,会有命中该kmem_cache的说法,和CPU中的cache命中是类似的意思,所以也会叫kmem_cache为cache(个人理解))有三条链表,slabs_full 表示该链表中每个slab的object对象都已经分配完了;slabs_partial 表示该链表中的slab的object对象部分分配完了;slabs_empty 表示该链表中的object对象全部没有分配出去;
其中每个slab都是一个或者多个连续的内存页组成,而每个slab被分成多个object对象。对象的分配和释放都是在slab中进行的,所以slab可以在三条链表中移动,如果slab中的object都分配完了,则会移到full 链表中;如果分配了一部分object,则会移到partial链表中;如果所有object都释放了,则会移动到empty链表中;其中当系统内存紧张的时候,slabs_empty链表中的slab可能会被返回给系统。
kmem_cache分配
基本的概念就是这样,下面说说简单的代码实现;
首先所有的kmem_cache结构都是从cache_cache,这个内存是在系统还没有完全初始化好就创建了(这个结构我看到了两个版本,不过意思差不多):
- static kmem_cache_t cache_cache = {
- slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
- slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
- slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
- objsize: sizeof(kmem_cache_t),
- flags: SLAB_NO_REAP,
- spinlock: SPIN_LOCK_UNLOCKED,
- colour_off: L1_CACHE_BYTES,
- name: "kmem_cache",
- };
static kmem_cache_t cache_cache = {
slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES,
name: "kmem_cache",
};系统分配
先看下面两个结构体:
- struct cache_size{
- size_t cs_size;
- struct kmem_cache *cs_cachep;
- }
- struct cache_size malloc_sizes[] = {
- {.cs_size = 32},
- {.cs_size = 64},
- {.cs_size = 128},
- {.cs_size = 256},
- ................
- {.cs_size = ~0UL},
- };
struct cache_size{
size_t cs_size;
struct kmem_cache *cs_cachep;
}
struct cache_size malloc_sizes[] = {
{.cs_size = 32},
{.cs_size = 64},
{.cs_size = 128},
{.cs_size = 256},
................
{.cs_size = ~0UL},
};
在系统初始化时,内核会调用kmem_cache_init函数对malloc_size数组进行遍历,对数组中的每个元素都调用kmem_cache_create()函数在cache_cache中分配一个struct kmem_cache 实例,并且把kmem_cache所在的地址赋值给cache_size中的cs_cachep指针(malloc_sizes[x]->cs_cachep);
- void __init kmem_cache_init(void)
- {
- struct cache_size *sizes = malloc_sizes;//数组
- struct cache_names *names = cache_names;//cache名称
- .....
- while(sizes->cs_size != ULONG_MAX){//从32到~0UL都遍历每个元素
- if(!sizes->cs_cachep)//表示还没有被初始化
- {
- // kmem_cache_create就是创建一个kmem_cache
- nbsp; sizes->cs_cachep = kmem_cache_create(names->name, sizes->cs_size,
- ARCH_KMALLOC_MINALIGN,
- ARCH_KMALLOC_FLAGS|SLAB_PANIC,
- NULL);
- }
- sizes++;
- names++;
- }
- .....
- }
void __init kmem_cache_init(void)
{
struct cache_size *sizes = malloc_sizes;//数组
struct cache_names *names = cache_names;//cache名称
.....
while(sizes->cs_size != ULONG_MAX){//从32到~0UL都遍历每个元素
if(!sizes->cs_cachep)//表示还没有被初始化
{
// kmem_cache_create就是创建一个kmem_cache
sizes->cs_cachep = kmem_cache_create(names->name, sizes->cs_size,
ARCH_KMALLOC_MINALIGN,
ARCH_KMALLOC_FLAGS|SLAB_PANIC,
NULL);
}
sizes++;
names++;
}
.....
}
初始化后的slab分配器如下图(图片来自于《深入linux设备程序机制》):

从上面的图可以看出,第一行为malloc_sizes[]数组的所有元素,由于malloc_size[]数组中存放的是 struct cache_size结构体元素,所以cache_size->cs_size 和 cache_size->cs_cachep; 其中每个cs_cachep指向一个kmem_cache,表示该kmem_cache中slab分配的对象大小为cs_size;这就很容易理解了;
注意,这是slab分配器只是个空壳子,kmem_cache下面是三条空的链表,也就是说kmem_cache下面没有一个slab也没有一个page更没有一个对象;这时候仅仅是定义了一个规则,表示该kmem_cache下的对象大小都固定为cs_size。至于什么时候创建slab,后面再讨论;
手动分配
所谓手动分配就是在自己程序中分配,其实就是理解下kmem_cache_create()函数:
struct kmem_cache* kmem_cache_create(const char* name, size_t size, size_t align, unsigned long flags, void(*ctor)(void*));
参数 name 是指向字符串的指针,用来生成kmem_cache的名字,会在/proc/slabinfo中出现;生成的kmem_cache对象会用一个指针指向该name;所以要保证name在kmem_cache对象有效周期内都有效;
参数 size 是用来指定slab分配的对象大小;
参数 align 是表示数据对齐的,一般使用0就可以;
参数 flags 是创建kmem_cache标识位掩码,使用0,表示默认;
参数 void (*ctor)(void*) 是构造函数,当slab分配一个新页面时,会对该页面中的每个内存对象调用该构造函数;
返回值:从cache_cache中返回一个指向kmem_cache实例的*cachep指针;当然该kmem_cache对象也会被加入cache_chain链表中;
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
其中cachep就是上面kmem_cache_create()函数返回的kmem_cache对象,该函数会返回cachep下的一个空闲的内存对象;flags 则是在没有空闲对象,需要从物理页分配一个新页时,才使用的到;
kmalloc函数
下面把kmalloc函数简单的分析下,代码把无关的东西删除掉了,主要是说明下kmalloc的工作原理;对照下面的图会很容易知道该函数做了些什么;
- void * kmalloc(size_t size, int flags)
- {
- struct cache_size *csizep = malloc_sizes;//定义好大小的数组
- struct kmem_cache *cachep;
- while(size > csizep->cs_size)//这是关键,从malloc_sizes数组(其实也是从kmem_cache链表)中遍历,得到地一个大于等于size的cache
- csizep++;
- cachep = csizep->cs_cachep;
- return kmem_cache_alloc(cachep, flags)//这里会发现正真分配对象的还是靠kmem_cache_alloc()函数
- }
void * kmalloc(size_t size, int flags)
{
struct cache_size *csizep = malloc_sizes;//定义好大小的数组
struct kmem_cache *cachep;
while(size > csizep->cs_size)//这是关键,从malloc_sizes数组(其实也是从kmem_cache链表)中遍历,得到地一个大于等于size的cache
csizep++;
cachep = csizep->cs_cachep;
return kmem_cache_alloc(cachep, flags)//这里会发现正真分配对象的还是靠kmem_cache_alloc()函数
}
slab的创建
前面说了,kmem_cache_create()仅仅是从cache_cache中分配一个kmem_cache实例,并不会分配实际的物理页,当然也就没有slab了(也没有对象)。那什么时候会创建一个slab呢?
只有满足下面两个条件时,才会给kmem_cache分配Slab:
(1)已发出一个分配新对象的请求;(2)kmem_cache中没有了空闲对象;
其实本质就是:需要得到该kmem_cache下一个对象,而kmem_cache没有空闲对象,这时候就会给kmem_cache分配一个slab了。所以新分配的kmem_cache只有被要求分配一个对象时,才会调用函数去申请物理页;
具体的分配流程:
首先会调用kmem_cache_grow()函数给kmem_cache分配一个新的Slab。其中,该函数调用kmem_gatepages()从伙伴系统获得一组连续的物理页面;然后又调用kmem_cache_slabgmt()获得一个新的Slab结构;还要调用kmem_cache_init_objs()为新Slab中的所有对象申请构造方法(如果定义的话);最后,调用kmem_slab_link_end()把这个Slab结构插入到缓冲区中Slab链表的末尾。
从slab的分配可以知道,其实所有的内存最终还是要伙伴系统来分配,这里就可以知道,这些内存都是连续的物理页。
这是后面增加的(感觉非常有必要提下):在某些情况下内核模块可能需要频繁的分配和释放相同的内存对象,这时候slab可以作为内核对象的缓存,当slab对象被释放时,slab分配器并不会把对象占用的物理空间还给伙伴系统。这样的好处是当内核模块需要再次分配内存对象时,不需要那么麻烦的向伙伴系统申请,而是可以直接在slab链表中分配一个合适的对象;以上是slub算法的主要原理。