android使用Python脚本编译侯建我们所需要的所有的库
使用Python需要注意的一些事项
比如我们想使用modules库下的common.py的类,我们得导入,但是导入的话如果没有__init__文件的话导入不了的,这点得注意
from modules import common__init__.py,为什么必须得使用这个呢
这个跟java有点区别,java中只要是在一个项目中的所有的类都可以通过包名导入,Python,__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件。
通常__init__.py 文件为空,但是我们还可以为它增加其他的功能。我们在导入一个包时,实际上是导入了它的__init__.py文件。这样我们可以在__init__.py文件中批量导入我们所需要的模块,而不再需要一个一个的导入。
原来这个文件的所有其实就相当我们java中的构造函数一下,默认的话是为空的,但是如果我们想要在初始化的时候做一些初始化动作,我们可以在里面做出一些处理。这样理解就很方便了。
这个做完以后我们得配置环境,进行下载andorid sdk,然后我们在安装相应的依赖
那么如何通过脚本实现下载android sdk 呢
def download_sdk():
"""
Download the SDK from Google
"""
url = ""
url_macosx = "https://dl.google.com/android/android-sdk_r24.0.2-macosx.zip"//mac电脑下的下载android sdk
url_linux = "https://dl.google.com/android/android-sdk_r24.3.4-linux.tgz"//对于linux下的下载
if sys.platform == "linux2":
url = url_linux
else:
url = url_macosx
file_name = url.split('/')[-1]//这里的-1的意思就是数据的最后一个数
u = urllib2.urlopen(url)//用于进行网络请求的
f = open(common.getConfig("rootDir") + "/" + file_name, 'wb')//函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。这里的common.getConfig(xxx)就是从我们的setting.properties文件读取相应的键值对的值,这里的这个值就是我们的项目的根目录,我们希望再次后面添加我们要下载文件的文件名,wb的意思是: 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
meta = u.info()
file_size = int(meta.getheaders("Content-Length")[0])
common.logger.debug("Downloading: %s \r\n FileName: %s \r\n FileSize: \r\n %s" % (url, file_name, file_size))
block_sz = file_size / 100
count = 0
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
count = count + 1
if count % 10 == 0:
sys.stdout.write('\r[{0}] {1}%'.format('#' * (count / 10), count))
sys.stdout.flush()
f.close()
//上面就是进行io流的读写然后进行一些显示屏幕的展示
androidSDKZIP = f.name
print common.term.cyan + str(common.config.get('qarkhelper', 'FILE_DOWNLOADED_TO')) + androidSDKZIP.decode(
'string-escape').format(t=common.term)
print common.term.cyan + str(common.config.get('qarkhelper', 'UNPACKING')) + androidSDKZIP.decode(
'string-escape').format(t=common.term)
//上面这个是对相应位置的一个File downloaded to/Users/zew/mysvn/xxx/xxx/android-sdk_r24.0.2-macosx.zip
\nUnpacking Android SDK Manager.../Users/zew/mysvn/xxx/xxx/android-sdk_r24.0.2-macosx.zip
//判断是否是linux
if sys.platform == "linux2":
try:
if not os.path.exists(androidSDKZIP.rsplit(".", 1)[0])://这里的就是/Users/zew/mysvn/qark/qark/android-sdk_r24.0.2-macosx
os.makedirs(androidSDKZIP.rsplit(".", 1)[0])//如果没有的话就创建这个文件夹
extract(androidSDKZIP, androidSDKZIP.rsplit(".", 1)[0])
except Exception as e:
logger.error(e.message)
common.writeKey('AndroidSDKPath', androidSDKZIP.rsplit(".", 1)[0] + "/android-sdk-linux/")
else:
zf = zipfile.ZipFile(androidSDKZIP)//进行一次解压
for filename in [zf.namelist()]://然后解压完了遍历
try:
if not os.path.exists(androidSDKZIP.rsplit(".", 1)[0]):
os.makedirs(androidSDKZIP.rsplit(".", 1)[0])
zf.extractall(androidSDKZIP.rsplit(".", 1)[0] + "/", zf.namelist(), )//这里我们通过暴力解压的方式把这个zip文件进行解压。
except Exception as e:
logger.error(e.message)
else:
logger.info('Done')
common.writeKey('AndroidSDKPath', androidSDKZIP.rsplit(".", 1)[0] + "/android-sdk-macosx/")//这个操作是把android sdk的路径写进配置文件中方便下次直接使用
# We dont need the ZIP file anymore
os.remove(androidSDKZIP)//然后我们再删除那个zip包,因为以后我们已经不再需要了
run_sdk_manager()
那里面有这么一个问题file_name = url.split('/')[-1],这个-1代表什么意思呢?
下面我们走一段代码
def split():
line = 'a+b+c+d'
print line.split('+')[-1]
if __name__ == "__main__":
split()打印结果是:d
那就是说[-1]的意思就是那个数组的最后一个位置-1。大家不要觉得我这个分享下载依赖这个功能的时候给你们讲一些语法是个累赘,我们从小学习汉语一开始说什么,都是教你喊爸爸,妈妈,然后过于去学校学习语法,英语也是开始“how are you ”,"I am fine thank you",我在这里先教你去说也就是去使用,然后遇到了问题再教你语法上的东西,方便大家快速的对一门语言的掌握。
urllib2是什么东西
模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等
按照他的官网文档说在Python3中它已经被分成几个模块,但是我们现在使用的是2.7版本暂时依然去使用这个模块进行网络请求,
urllib2.urlopen(url[, data[, timeout[, cafile[, capath[, cadefault[, context]]]]])
Open the URL url, which can be either a string or a Request object.
data may be a string specifying additional data to send to the server, or None if no such data is needed. Currently HTTP requests are the only ones that use data; the HTTP request will be a POST instead of a GET when the data parameter is provided. data should be a buffer in the standard application/x-www-form-urlencoded format. The urllib.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format. urllib2 module sends HTTP/1.1 requests with Connection:close header included.
数据可能是一个字符串,指定要发送给服务器的其他数据,或者如果不需要这些数据,则为None。目前,HTTP请求是唯一使用数据的请求;当提供数据参数时,HTTP请求将是POST而不是GET。数据应该是标准application/x-www-form-urlencoding格式中的缓冲区。urllib.urlencode()函数接受2元组的映射或序列,并以这种格式返回字符串。urllib2模块发送带有连接的HTTP/1.1请求:包含关闭报头。
The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). This actually only works for HTTP, HTTPS and FTP connections.
可选的timeout参数指定了一个以秒为单位的超时,用于阻塞操作,比如连接尝试(如果没有指定,将使用全局默认超时设置)。这实际上只适用于HTTP、HTTPS和FTP连接。
If context is specified, it must be a ssl.SSLContext instance describing the various SSL options. See HTTPSConnection for more details.
如果指定了上下文,则必须是ssl。描述各种SSL选项的SSLContext实例。有关详细信息,请参阅HTTPSConnection。
The optional cafile and capath parameters specify a set of trusted CA certificates for HTTPS requests. cafile should point to a single file containing a bundle of CA certificates, whereas capath should point to a directory of hashed certificate files. More information can be found in ssl.SSLContext.load_verify_locations().
可选的cafile和capath参数为HTTPS请求指定一组受信任的CA证书。cafile应该指向一个包含一组CA证书的文件,而capath应该指向一个散列证书文件的目录。更多信息可以在ssl.SSLContext.load_verify_locations()中找到。
The cadefault parameter is ignored.
忽略cadefault参数。
This function returns a file-like object with three additional methods:
这个函数返回一个类文件的对象,另外还有三个方法:
geturl() — return the URL of the resource retrieved, commonly used to determine if a redirect was followed
info() — return the meta-information of the page, such as headers, in the form of an mimetools.Message instance (see Quick Reference to HTTP Headers)
getcode() — return the HTTP status code of the response.
Raises URLError on errors.
Note that None may be returned if no handler handles the request (though the default installed global OpenerDirector uses UnknownHandler to ensure this never happens).
In addition, if proxy settings are detected (for example, when a *_proxy environment variable like http_proxy is set), ProxyHandler is default installed and makes sure the requests are handled through the proxy.
Changed in version 2.6: timeout was added.
Changed in version 2.7.9: cafile, capath, cadefault, and context were added.open方法是什么?
刚刚有一串这么代码f = open(common.getConfig("rootDir") + "/" + file_name, 'wb')。
python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
open(name[, mode[, buffering]])-
name : 一个包含了你要访问的文件名称的字符串值。
-
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。这里的wb意思是:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
-
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
我们看我们调用的是open(String ,String)两个参数,但是这个文档给我们的是三个参数,按照对java的理解是那一定会有一个两个参数,和三个参数的重载方法,于是我点进去的时候查看发现,如下代码,会看到xxx=None的情况,这个是什么意思?
def open(name, mode=None, buffering=None): # real signature unknown; restored from __doc__
"""
open(name[, mode[, buffering]]) -> file object
Open a file using the file() type, returns a file object. This is the
preferred way to open a file. See file.__doc__ for further information.
"""
return file('/dev/null')这里我们要可入一个概念就是:如何定义一个有默认参数的函数,因为有默认的参数我们可以传也可以不传,不传的话就使用默认的参数
定义一个有可选参数的函数是非常简单的,直接在函数定义中给参数指定一个默认值,并放到参数列表最后就行了。例如:
def spam(a, b=42):
print(a, b)
spam(1) # Ok. a=1, b=42
spam(1, 2) # Ok. a=1, b=2如果默认参数是一个可修改的容器比如一个列表、集合或者字典,可以使用None作为默认值,就像下面这样:
# Using a list as a default value
def spam(a, b=None):
if b is None:
b = []
...如果你并不想提供一个默认值,而是想仅仅测试下某个默认参数是不是有传递进来,可以像下面这样写:
_no_value = object()
def spam(a, b=_no_value):
if b is _no_value:
print('No b value supplied')
...
>>> spam(1)
No b value supplied
>>> spam(1, 2) # b = 2
>>> spam(1, None) # b = None
>>>
仔细观察可以发现到传递一个None值和不传值两种情况是有差别的。os.path.exists(androidSDKZIP.rsplit(".", 1)[0])
这段代码是什么意思呢?我们分两段看
- androidSDKZIP.rsplit(".", 1)[0]是什么意思?
str.rsplit([sep[, maxsplit]]),Python rsplit() 方法通过指定分隔符对字符串进行分割并返回一个列表,默认分隔符为所有空字符,包括空格、换行(\n)、制表符(\t)等。类似于 split() 方法,只不过是从字符串最后面开始分割。sep:可选参数,指定的分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等,maxsplit:可选参数,分割次数,默认为分隔符在字符串中出现的总次数。
官方给的定义是:Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done, the rightmost ones. If sep is not specified or None, any whitespace string is a separator. Except for splitting from the right, rsplit() behaves like split() which is described in detail below.
意思就是最多完成maxsplit次分拆,从右边开始计算,就是说,如果我们按照某个规则本可以分拆成10部分,如果maxsplit=1,那么只能从右边数,分割一次。
S = "this is string example....wow!!!"
print (S.rsplit())
print (S.rsplit(None, 1))
print (S.rsplit('i', 1))
print (S.rsplit('i', 2))
print (S.rsplit('w'))
['this', 'is', 'string', 'example....wow!!!']
['this is string', 'example....wow!!!'] //从右边开始,以None分割一次
['this is str', 'ng example....wow!!!'] //从右边开始,以i分割一次
['this ', 's str', 'ng example....wow!!!'] //从右边开始,以i分割2次
['this is string example....', 'o', '!!!'] //从右边开始,以w分割全部次数
- os.path.exists()是什么意思
androidSDKZIP.rsplit(".", 1)[0]内容是多少呢?
我们断点可以看到是:

zf = zipfile.ZipFile(androidSDKZIP)//进行一次解压,解压完我们通过zf.namelist()进行遍历,就是把这个压缩文件里的所有文件拿出来遍历,可以看出
![]()
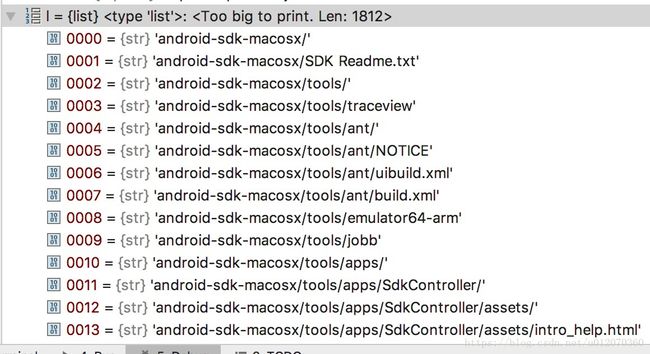
大约有一千多个文件。
然后我们对这个些文件进行暴力解压,zf.extractall(androidSDKZIP.rsplit(".", 1)[0] + "/", zf.namelist(), )
下面我们来学习一下Python的解压zip文件是如何操作的,ZipFile.extractall([path[, members[, pwd]]])¶
Extract all members from the archive to the current working directory. path specifies a different directory to extract to. members is optional and must be a subset of the list returned by namelist().pwd is the password used for encrypted files.
从存档中提取所有成员到当前工作目录。路径指定要提取到的不同目录。成员是可选的,并且必须是namelist()返回的列表的子集。pwd是加密文件的密码。
在这里我遇到一个问题解决了很久,我们解压出来的文件我看格式都是文本文稿,但是如果我直接手动去解压zip的话比如像,sdkmanager的文件的种类都是Unix executable,因为如果不是这个文件,当我手动切刀目录下下载依赖的话执行sdkmanager "extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2"等命令都是not commend,纠结了很久。
![]()
如果直接通过python解析后查看文件的格式会发现都是这种格式,根本没法执行。那么怎么解决呢?
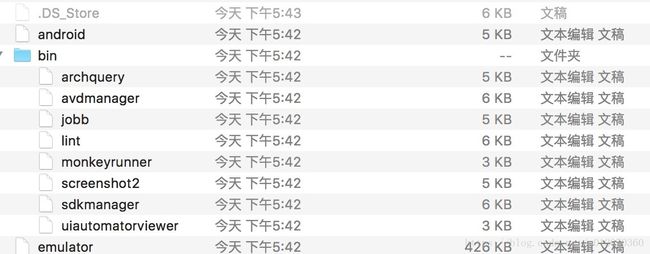
后来经过测试必须得走了这个方法才可以变成可执行的Unix文件
st = os.stat(android)
os.chmod(android, st.st_mode | stat.S_IEXEC)
很多人下载都是通过tools文件夹下的android进行下载的,其实在国内的话这种方式基本上是不可行,我也不知道为什么还有那么多人使用,所以接下来我要通过CLI去安装sdk相关文件,在低版本的话这个sdkManager是没有的,要下载高版本的tools,我这里下载的是26.1.1.
def run_sdk_manager():
"""
Runs the SDK manager
"""
flag_no_ui = " --no-ui"
android = common.getConfig('AndroidSDKPath') + "/tools/bin/sdkmanager"
# need to have execute permission on the android executable
st = os.stat(android)
os.chmod(android, st.st_mode | stat.S_IEXEC)
# Android list sdk
android_cmd1 = sdkmanager + "extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2"
args1 = shlex.split(android_cmd1)
p1 = Popen([android, 'extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2'], stdout=PIPE, stdin=PIPE, stderr=STDOUT)
if not common.interactive_mode:
p1.stdin.write(common.args.acceptterms)
else:
p1.stdin.write("y\n")
for line in iter(p1.stdout.readline, b''):
print line,
if "Do you accept the license" in line:
p1.stdin.flush()
p1.stdin.write("y\n")
output, err = p1.communicate("y\n")
common.set_environment_variables()def set_environment_variables():
os.environ["PATH"] += os.pathsep + getConfig('AndroidSDKPath') + 'tools' + os.pathsep + getConfig(
'AndroidSDKPath') + 'platform-tools' + os.pathsep + getConfig('AndroidSDKPath') + 'tools/lib'
os.environ["ANDROID_HOME"] = getConfig('AndroidSDKPath')
先看 st = os.stat(sdkmanager)
Python的stat(path)方法在给定路径上执行统计系统调用。
- path - 这是要统计信息是必需的路径。
os.chmod(sdkmanager, st.st_mode | stat.S_IEXEC),这段代码的意思就是os.chmod() 方法用于更改文件或目录的权限os.chmod(path, mode),这里的path是指文件名路径或目录路径。mode:可用以下选项按位或操作生成, 目录的读权限表示可以获取目录里文件名列表, ,执行权限表示可以把工作目录切换到此目录 ,删除添加目录里的文件必须同时有写和执行权限 ,文件权限以用户id->组id->其它顺序检验,最先匹配的允许或禁止权限被应用。- stat.S_IXOTH: 其他用户有执行权0o001
- stat.S_IWOTH: 其他用户有写权限0o002
- stat.S_IROTH: 其他用户有读权限0o004
- stat.S_IRWXO: 其他用户有全部权限(权限掩码)0o007
- stat.S_IXGRP: 组用户有执行权限0o010
- stat.S_IWGRP: 组用户有写权限0o020
- stat.S_IRGRP: 组用户有读权限0o040
- stat.S_IRWXG: 组用户有全部权限(权限掩码)0o070
- stat.S_IXUSR: 拥有者具有执行权限0o100
- stat.S_IWUSR: 拥有者具有写权限0o200
- stat.S_IRUSR: 拥有者具有读权限0o400
- stat.S_IRWXU: 拥有者有全部权限(权限掩码)0o700
- stat.S_ISVTX: 目录里文件目录只有拥有者才可删除更改0o1000
- stat.S_ISGID: 执行此文件其进程有效组为文件所在组0o2000
- stat.S_ISUID: 执行此文件其进程有效用户为文件所有者0o4000
- stat.S_IREAD: windows下设为只读
- stat.S_IWRITE: windows下取消只读
反正我的理解就是设置下这个sdkManager的执行的权限问题。
下面这个就是最关键的了,这个目的我是为了下载一下constraint-layout的依赖
p1 = Popen([sdkmanager, 'extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2'], stdout=PIPE, stdin=PIPE, stderr=STDOUT)说明这个命令之前我们科普一下如果我们想去ping一下谷歌的网站我们改执行什么
是不是要在终端执行:ping -c 5 ww.google.com,这个-c参数代表在发送指定数目的包之后停止,5 这个参数对应上面的 -c 参数,意思是发送5个包就停止发送了。最后一个参数是指你需要ping的网址
child = subprocess.Popen(["ping","-c","5","www.google.com"])
那我们想要执行的终端命令式
sdkmanager "extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2"那么如何设计这个shell命令呢
自然就能理解p1 = Popen([sdkmanager, 'extras;m2repository;com;android;support;constraint;constraint-layout-solver;1.0.2'], stdout=PIPE, stdin=PIPE, stderr=STDOUT)是什么意思了。
下面我们简单的了解一下打印和文件的写入,上述代码中有这么一段文件
p1.stdin.write(common.args.acceptterms)了解这个我们先了解一下python print 和 sys.stdout.write()的区别
当我们使用print(obj)在console上打印对象的时候,实质上调用的是sys.stdout.write(obj+'\n'),print在打印时会自动加个换行符,以下两行等价:
sys.stdout.write('hello'+'\n')
print 'hello'
打印结果都是
hello
hello
其实他还有个特殊的功能就是其实原始的 sys.stdout 指向控制台,如果把文件的对象的引用赋给 sys.stdout,那么 print 调用的就是文件对象的 write 方法,将对象写入文件中:
def writeTest():
f_handler = open('out.log', 'w')
sys.stdout = f_handler
print('hello')当然我们执行完了会查看到本地还有个文件生成

打开会发现是:hello
那么如果你还想在控制台打印一些东西的话,最好先将原始的控制台对象引用保存下来,
向文件中打印之后再恢复 sys.stdout
比如我们先用一个成员变量记录一下
__console__=sys.stdout
乱七八糟的一对操作
sys.stdout=__console__刚刚下载sdk,以及一些依赖,那么我们是不是想想其实我们还是有一些没有做,那就是我们虽然下载完了,但是我们
配置环境变量,比如我们的android home,tools,platform-tools三个环境变量。我查了很多文档暂时发现一种设置环境
变量的方式是设置完以后仅仅适用于当前程序,并没有改变整个系统
def set_environment_variables():
os.environ["PATH"] += os.pathsep + getConfig('AndroidSDKPath') + 'tools' + os.pathsep + getConfig(
'AndroidSDKPath') + 'platform-tools' + os.pathsep + getConfig('AndroidSDKPath') + 'tools/lib'
os.environ["ANDROID_HOME"] = getConfig('AndroidSDKPath')os.environ["PATH"],这个是什么意思呢?讲解这个我们先看看Python如果获取系统的话环境变量
def getEnvirKeys():
for key in os.environ.keys():
print(key)
打印结果:
PYTHONIOENCODING
ANDROID_NDK_HOME
VERSIONER_PYTHON_PREFER_32_BIT
LC_CTYPE
LOGNAME
USER
HOME
PATH
PYTHONUNBUFFERED
PS1
VIRTUAL_ENV
SHELL
VERSIONER_PYTHON_VERSION
XPC_FLAGS
PYCHARM_MATPLOTLIB_PORT
SSH_AUTH_SOCK
PYTHONPATH
XPC_SERVICE_NAME
CLASSPATH
Apple_PubSub_Socket_Render
TMPDIR
GRADLE_HOME
PYCHARM_HOSTED
__CF_USER_TEXT_ENCODING
PWD
如何获取指定环境变量名对应的的值呢?
def getEnvirValues():
dir = os.environ.get('ANDROID_NDK_HOME')
print(dir)
打印结果:
/Users/zew/Library/Android/android-ndk-r16b那么小伙伴们肯定回想那我们应该可以设置环境变量吧?那我们试一试
def setEnvir():
dir = "D:\LearnTool"
os.environ['ANDROID_NDK_HOME'] = dir
print(os.environ.get('ANDROID_NDK_HOME'))
打印结果
D:\LearnTool然后我打开系统的环境变量文件查看发现
然后是:export ANDROID_NDK_HOME=/Users/zew/Library/Android/android-ndk-r16b
可以查看系统的环境变量并没哟改变那么,os.environ["PATH"]的作用是什么呢?如果要是你你会觉得这个参数的设置方法
到底有什么用呢?其实也不难理解,这个设置环境变量的方法我们可以理解成只对这个程序进程生效,不会永久更新而已。
有的小伙伴想如何做到永久更新环境变量呢?
//TODO 这个地方牵扯到一些shell指令,先放着。
一切都准备就绪了,我们现在执行以下,看是不是能把constraint-layou代码自动拉下来呢?

ok,到此为止我们可以拉通过拉下来,下面我们需要做的是这段脚本能帮我们把整个项目中所有的仓库代码都拉下来
如何去完善呢?
现在我有个需求,就是我们在执行shell命令的时候如果加载一个进度,这个过程必须得知道就是我们在执行shell的返回
流文件的大小。
p1 = Popen([sdkmanager, itemdepend], stdout=PIPE, stdin=PIPE, stderr=STDOUT)弄清楚这个问题我们先看下这个代码的含义。
官方给的Popen的定义就是:
Open a pipe to or from command. The return value is an open file object connected to the pipe, which can be read or written depending on whether mode is 'r' (default) or 'w'. The bufsize argument has the same meaning as the corresponding argument to the built-in open() function. The exit status of the command (encoded in the format specified for wait()) is available as the return value of the close() method of the file object, except that when the exit status is zero (termination without errors), None is returned.
从命令打开管道。返回值是一个连接到管道的打开文件对象,根据mode是'r'(默认)还是'w',可以读取或写入该对象。bufsize参数的含义与内置open()函数的相应参数相同。命令的退出状态(编码为为wait()指定的格式),可以作为文件对象的close()方法的返回值使用,但是当退出状态为0时(终止时没有错误),则不返回。根据这些可能大家还不是很清楚什么意思,先不管,先看它的几个参数什么意思。
popen(args,stdout=PIPE, stdin=PIPE, stderr=STDOUT)
第一个列表里的[]是args的一种变现形式
args参数,可以是一个字符串,也可以是一个包含程序参数的列表,要执行程序一般就是执行程序列表的第一项,或者
字符串本身。
test.txt文件内容是:这是一个popen命令打开的文件,这里说明一下test.txt文本文件内容是:“这是一个popen命令打开的文件”
比如:Popen(["cat","test.txt"])
def popenTest():
Popen(["cat", "test.txt"])
打印结果是:
这是一个popen命令打开的文件当我们执行:Popen("test.txt")
Popen("cat test.txt")
打印结果是:
File "/Users/zew/PycharmProjects/RepDemo/Text2.py", line 88, in
popenTest()
File "/Users/zew/PycharmProjects/RepDemo/Text2.py", line 83, in popenTest
Popen("cat test.txt")
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 710, in __init__
errread, errwrite)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 1335, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or directory 后者不会工作,因为如果是一个字符串的话,必须是程序的路径才可以
但是下面的可以工作,Popen("test.txt",shell=True),这是因为它相当于Popen([/bin/sh],"-c","cat test.txt")
好啦,咱们来试一下哈,这里我们必须去把/bin/sh下的sh文件设置成环境变量才可以,否则的话我们要在test.txt前面加上路径
Popen("cat test.txt", shell=True)
打印结果:
这是一个popen命令打开的文件其实这个Popen("cat test.txt", shell=True)的意思等价于你执行了
Popen(["/bin/sh", "-c", "cat /Users/zew/PycharmProjects/RepDemo/test.txt"])
打印结果
这是一个popen命令打开的文件这里因为我们已经sh环境变量,如果这样的话,系统其实是找不到sh文件,执行不到这个命令,所以最终我们把环境变量给取消了,然后在文件前面加上精确地路径才能执行,这里要注意一下。
因为这里的shell参数:如果把shell设置成True,指定的命令会在shell里解释执行。
至于后面这个几个参数什么意思,stdout=PIPE, stdin=PIPE, stderr=STDOUT
subprocess.PIPE:一个可以被用于Popen的stdin 、stdout 和stderr 3个参数的特输值,表示需要创建一个新的管道。
subprocess.STDOUT:一个可以被用于Popen的stderr参数的输出值,表示子程序的标准错误汇合到标准输出。
为了弄清楚到底这个p=Popen(args,xx,xxx),跟着我打开官方文档学习一下subprocess这个模块
subprocess
翻译过来就是子进程模块允许生成新进程,连接到它们的输入/输出/错误管道,并获得它们的返回码。本模块拟替换几个较旧的模块和功能。简单的来说就是subprocess包的主要功能就是执行外部的命令和程序,这个很好理解,比如上文我们需要打开一个test.txt文件或者下载一个文件,这个都是外部的命令,从这个意义上subprocess跟shell很类似。在Linux中一个进程可以fork另外一个进程,并且让这个进程执行一个程序,在python中我们通过subprocess包来fork一个子进程,并运行外部程序。
subprocess包中定义了有数个创建子进程的函数,这些函数有不同的方式创建子进程,所以我们根据自身的需要来选择使用,另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而进行进程中使用的文本。
1:先来连接一下Popen()方式:
popen创建对象后,主进程不会自动等待子进程完成,所以如果我们要有有什么需求需要主进程等待的话必须得调用wait()方法,父进程才会等待,
child = Popen(["ping", "-c", "5", "www.google.com"])
print ("parent process")
打印结果:
parent process
可以看出没有ping的结果,父进程在开启子进程之后并没有等待child的完成,而是直接运行print。,直接就继续的走下去了,这里的子进程一闪而过就没了那么作为对比
我们看一下
child = Popen(["ping", "-c", "5", "www.google.com"])
child.wait()
print ("parent process")
打印结果:
PING www.google.com (67.15.129.210): 56 data bytes
Request timeout for icmp_seq 0
Request timeout for icmp_seq 1
Request timeout for icmp_seq 2
Request timeout for icmp_seq 3
--- www.google.com ping statistics ---
5 packets transmitted, 0 packets received, 100.0% packet loss
parent process此外,你还可以在父进程中对子进程进行其它操作,比如我们上面例子中的child对象:
child.poll() # 检查子进程状态
child.kill() # 终止子进程
child.send_signal() # 向子进程发送信号
child.terminate() # 终止子进程
子进程的PID存储在child.pid
子进程的文本流控制
子进程的标准输入,标准输出,标准错误,并可以利用subprocess.PIPE将多个子进程的输入输出连接到一起,构成管道。
subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走。child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
开始我也不是很理解这段是什么意思,查找了很多资料,代码结合自己的理解,最后我理解的这个管道的意思是什么呢,就是现在进程可能fork A,B,C,D四个进程,每个进程我都可能会做一些事,各自完成自己的任务,本身没有什么问题。
比如我现在有个需求是每个进程都想进行进程间交互那该怎么实行呢,stidin,stdout设置为pipe,A想给B发送数据,则将B进程的stdin是A进程的stdout,每个进程的stdin都是上一个进程的stdout,这样就首尾相连了,先让A进程将文本写到管道缓冲区的一个区域a,随后B的stdin从该管道中将文本读走然后在B进程中输出文本也被放到该管道中,C的stdin从该管道中将文本读走然后在C进程中输出文本也放到该管道中,D的stdin从该管道中将文本读走然后输出文本也被放到该管道中,形成一个首位相连。
比如我现在有个shell命令:
ps aux | egrep 'xtrabackup|innobackupex' | grep -v grep | awk '{print $2}' | xargs kill这是(我比较常用的)杀掉备份进程的一行命令
那么如果如何将上述代码转换为python脚本表达呢?
推荐的做法:分别生成subprocess子进程,同时用管道相连。
import subprocess
import shlex
ps_proc = subprocess.Popen(shlex.split('ps aux'), stdout=subprocess.PIPE)
grep_proc = subprocess.Popen(shlex.split("egrep 'xtrabackup|innobackupex'"), stdin=ps_proc.stdout, stdout=subprocess.PIPE)
awk_proc = subprocess.Popen(shlex.split('awk "{print $2}"'), stdin=grep_proc.stdout, stdout=subprocess.PIPE)
kill_proc = subprocess.Popen(shlex.split('xargs kill'), stdin=awk_proc.stdout)
要注意的是,communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成。
我们还可以利用communicate()方法来使用PIPE给子进程输入:
child = Popen(["cat"], stdin=PIPE)
out = child.communicate("vamei")
打印:
vamei注意: 如果子进程输出了大量数据到stdout或者stderr的管道,并达到了系统pipe的缓存大小的话,
子线程会停止输出到pipe,但是父进程必须得等到子进程完成后才能继续,所以就造成了死锁,官方建议使用
communicate() 来避免这种情况的发生。因为communicate()会把stdout,stderr里的数据放到内存中,从而解决了这个问题,但是取的数据被缓冲在内存中,所以如果数据大小很大或没有限制,不要使用此方法。
官方给的提示:The data read is buffered in memory, so do not use this method if the data size is large or unlimited.
那么现在就有个一个是死锁,建议使用communicate(),另一方面内存有限不能读取大量的数据,怎么办呢?
回答这个问题肯定还有很多人跟我之前的问题一样,就是为什么我执行一个命令下载文件为什么还有这个担心呢,因为stdout写入pipe的只是一些输出流,比如我执行java -v,返回一堆命令-v,-verison这种,为什么我要关心这个呢?只要文件下载好了就行了啊,是的,因为我们下载的时候得让我们的进程wait()住,否则一闪而过就没了,上面我们有个例子:
child = Popen(["ping", "-c", "5", "www.google.com"])
child.wait()
print ("parent process")如果我们不wait的话,这个进程很快就结束了,我们并不能看到ping的结果,所以我们必须得wait(),让这个进程执行到最后。那么问题就出在这里,我们子线程如果每次在stdout在管道写了太多的数据里会导致停止再往pipe里输出,但是父进程必须得等到子线程完成后才能继续,也就是死锁了,如果使用communicate()的话把所有的数据都读到内存中解决了这个问题,但是直接读到内存中,主机就卡住了,也不行,如果解决这个问题呢?
解决办法就是数据一行一行的读,读取玩以后在wait,这样既保证了不会堵塞(PIPE里的数据有进有出,不会wait)
比如我是这么解决的
p1 = Popen([sdkmanager, itemdepend],
stdout=PIPE, stdin=PIPE, stderr=STDOUT)
for line in iter(p1.stdout.readline, b''):
pass
p1.wait()那么大家看我这段代码
for itemdepend in sdkdepends:
print "downloadeding:"+itemdepend
PROGRESS_BARS.append(itemdepend)
p1 = Popen([sdkmanager, itemdepend],
stdout=PIPE, stdin=PIPE, stderr=STDOUT)
if not common.interactive_mode:
p1.stdin.write(common.args.acceptterms)
else:
p1.stdin.write("y\n")
for line in iter(p1.stdout.readline, b''):
# print line,
if "Do you accept the license" in line:
p1.stdin.flush()
p1.stdin.write("y\n")
output, err = p1.communicate("y\n")
print "downloaded:"+itemdepend
# sys.stdout.write('\r[{0}]'.format('#'))
common.set_environment_variables()
print 'evevry thing has downloaded'一定会有疑问,为什么每次我们开启一个新的进程去执行命令玩以后并没有去wait呀,为什么你的命令可以一个进程完成一个任务在接着完成下一个进程任务,按理说,如果没有wait的话就像上文说的那样,一闪而过才对呀。我想跟多小伙伴会有这个问题,解释这个原因主要是在于我们在每个进程后面的调用了p1.communicate("y\n")方法,
官方给的解释是:
"""Interact with process: Send data to stdin. Read data from
stdout and stderr, until end-of-file is reached. Wait for
process to terminate. The optional input argument should be a
string to be sent to the child process, or None, if no data
should be sent to the child.
communicate() returns a tuple (stdout, stderr)."""
与进程交互:将数据发送到stdin。从stdout和stderr读取数据,直到到达文件末尾。等待进程终止。
可选输入参数应该是要发送给子进程的字符串,或者如果不应该发送数据给子进程,则为None。通信()返回一个元组(stdout, stderr)。如果没有这个方法会怎么样呢,我们期待的是很快进程就可以终止
但是测试的时候发现自然可以进程等待一个个执行,这是什么问题呢?
再仔细看代码发现了
for line in iter(p1.stdout.readline, b''):这个不同在迭代输出流的。所以进程一直不会停止。ok,那我们试一下把这个readline删除会是什么样子呢?
for itemdepend in sdkdepends:
print "downloadeding:"+itemdepend
PROGRESS_BARS.append(itemdepend)
p1 = Popen([sdkmanager, itemdepend],
stdout=PIPE, stdin=PIPE, stderr=STDOUT)
if not common.interactive_mode:
p1.stdin.write(common.args.acceptterms)
else:
p1.stdin.write("y\n")
# for line in iter(p1.stdout.readline, b''):
# # print line,
# if "Do you accept the license" in line:
# p1.stdin.flush()
# p1.stdin.write("y\n")
# output, err = p1.communicate("y\n")
print "downloaded:"+itemdepend
['build-tools;26.0.0', 'build-tools;26.0.2', 'platforms;android-26', 'platform-tools', 'extras;m2repository;com;android;support;constraint;constraint-layout;1.0.2', 'sources;android-26']
downloadeding:build-tools;26.0.0
downloaded:build-tools;26.0.0
downloadeding:build-tools;26.0.2
downloaded:build-tools;26.0.2
downloadeding:platforms;android-26
downloaded:platforms;android-26
downloadeding:platform-tools
downloaded:platform-tools
downloadeding:extras;m2repository;com;android;support;constraint;constraint-layout;1.0.2
downloaded:extras;m2repository;com;android;support;constraint;constraint-layout;1.0.2
downloadeding:sources;android-26
downloaded:sources;android-26
evevry thing has downloaded
出掉了那个readline代码以后,迅速的执行完但是看文件里并没有生成,说明进程一晒而过就结束了,并没有挂起等待的过程
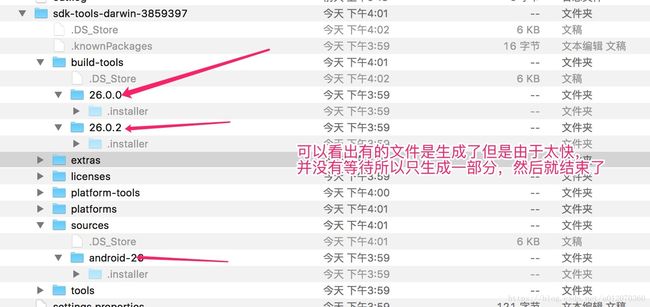
但是随后我过一会发现之前的文件全部下载了,说明其实虽然我们刚刚一闪而过了,但是进程其实并没有杀死,还给我们
默默的执行指令动作。


好啦!
上面总结起来就是完成了sdk基本上所有的下载,但是还有一些优化的工作
- 我们能不能能不能动态的下载我们想要下载的构建版本和依赖
- 我们不能再下载的过程中能不能有个图形化进度条让我看到
- 我们能不能在执行脚本的时候帮我检测到如果指定文件如果含有相同的文件的时候自动跳过呢?
围绕着三个问题,我们来娓娓道来
好啦。
1:我们接下来,完成gradle的各个版本以及对应的第三方的库文件的下载。
引申:
一、什么是管道
如果你使用过Linux的命令,那么对于管道这个名词你一定不会感觉到陌生,因为我们通常通过符号“|"来使用管道,但是管理的真正定义是什么呢?管道是一个进程连接数据流到另一个进程的通道,它通常是用作把一个进程的输出通过管道连接到另一个进程的输入。
举个例子,在shell中输入命令:ls -l | grep string,我们知道ls命令(其实也是一个进程)会把当前目录中的文件都列出来,但是它不会直接输出,而是把本来要输出到屏幕上的数据通过管道输出到grep这个进程中,作为grep这个进程的输入,然后这个进程对输入的信息进行筛选,把存在string的信息的字符串(以行为单位)打印在屏幕上。
#include
int pipe(int file_descriptor[2]); 我们可以看到pipe函数的定义非常特别,该函数在数组中墙上两个新的文件描述符后返回0,如果返回返回-1,并设置errno来说明失败原因。
数组中的两个文件描述符以一种特殊的方式连接起来,数据基于先进先出的原则,写到file_descriptor[1]的所有数据都可以从file_descriptor[0]读回来。由于数据基于先进先出的原则,所以读取的数据和写入的数据是一致的。
pipe是基于文件描述符工作的,所以在使用pipe后,数据必须要用底层的read和write调用来读取和发送。
不要用file_descriptor[0]写数据,也不要用file_descriptor[1]读数据,其行为未定义的,但在有些系统上可能会返回-1表示调用失败。数据只能从file_descriptor[0]中读取,数据也只能写入到file_descriptor[1],不能倒过来。