图像车牌识别-SVM分类器的构建(字符识别部分)
车牌识别系统识别部分采用了SVM分类器,训练一定数量的样本,构建了一个SVM分类器,实现车牌汉字和字母,以及数字的识别。
<1> SVM
SVM是支持向量机(Support Vector Machine)的简称,对于解决小样本、非线性、高维的模式识别问题有很多特有的优势。
简单地讲呢,SVM分类算法的实质就是在样本的特征空间中找到一个最优的超平面,使这个超平面离所有的类的样本的距离最小者最大化。
如下图所示,总共有两类,每类的样本数为五,最优超平面即为可以将两类分开,且两类中离分类面最近的样本与分类面的距离最大。
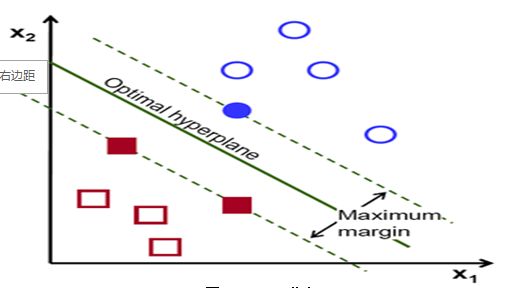
对于只有两类的SVM分类器,SVM分类器就是一个线性分类器。
opencv已经帮我们封装好了SVM算法,我们所要做的就是使用opencv中的SVM类,调用其load载入保存了特征向量的文件,再调用SVM类的识别函数即可。
<2>构建SVM分类器
车牌字符包括汉字和字母和数字,车牌的第一个字符一定为汉字,第二个字符一定为字母,其余五个可能为数字和也有可能是数字和字母的混合。由此实验中训练了三个分类器,分别进行汉字分类、字母分类、数字和字母分类,其中汉字分类器每类的样本只有一个,但在汉字处理较清晰的情况下,可以准确识别。字母分类器和数字与字母混合分类器的每个类的样本有20个。
要训练分类器首先必须提取每个样本的特征,将样本的特征数据保存起来(实验保存特征数据的文件格式为.xml文件)。
对每个样本都得提取特征,所以必须编写特定的样本提取程序来完成这项工作。将每类的样本的储存地址和编号保存到txt 文件中,偶数行保存样本地址,奇数行保存样本的编号,编写程序依次提取样本的特征,并保存到相应的.xml文件中(本实验生成的三个.xml文件:HOG_SVM_DATA、HOG_SVM_DATA_CHAR、HOG_SVM_DATA_CHARACTER)。
其中训练的样本汉字部分是我通过截图,在图像处理获得的,每个汉字只有一份,数字和字母部分是好像是从网上下载下来的,具体哪个链接不记得了,不过还是非常感谢资料的原创提供者!
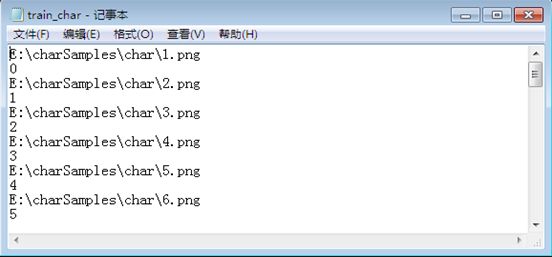
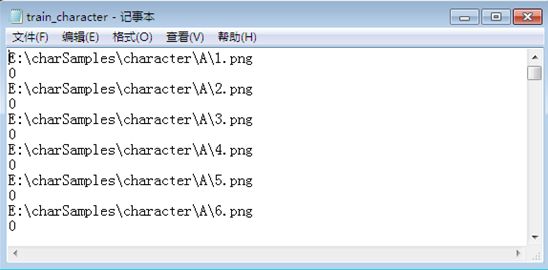
实验中我是分别将汉字、数字、字母的保存路径和编号记录在三个不同的txt文件中,如下图所示:
汉字样本txt文件
字母样本txt文件
数字样本txt文件
在根据上一篇文章中介绍的提取HOG特征,并将其以.xml的文件格式保存。
代码找了半天没找到,只能用我报告上的图片了:

其中参数(28,28)表示移动窗口大小,不过在对图片进行特征提取时已经将图片的尺寸改为(28,28),(14,14)表示块大小,(7,7)表示单步移动尺寸,块每移动一步的大小为7个像素,每个块包括四个小区域(CELL),所以每个小区域的大小亦设置为(7,7),参数9表示每个小区域生产9个方向的梯度直方图,这样每个小区域就有9维特征,共有16个小区域,就可以生成16*9维的特征向量。
识别是只需调用opencv中SVM类中的load函数载入保存特征向量的文件,在调用SVM类中的识别函数即可。
<3>使用已经构建好的SVM实现识别
对已经分割好的字符图片,要进行一定的处理,使其与之前训练的样本图片具有相同性质,继而提取分类器所需要的特征,按一定的顺序逐个识别。调用分类器识别字符时,只需调用SVM类中laod函数加载训练好的数据,再调用SVM分类器的.predict函数进行识别。
识别部分代码如下:
CvSVM svm = CvSVM(); //数字和字母混合识别
svm.load("HOG_SVM_DATA.xml");
CvSVM svm_character = CvSVM(); //单独识别字母
svm_character.load("HOG_SVM_DATA_CHARACTER.xml");
CvSVM svm_char = CvSVM(); //单独识别汉字
svm_char.load("HOG_SVM_DATA_CHAR.xml");
IplImage* img[7];
char result[200];
int ret[7];
//剪切字符图片
img[0]=Image_process(The_split_Image1); // 汉字
img[1]=Image_process(The_split_Image2); //字母
//字母和数字混合
img[2]=Image_process(The_split_Image3);
img[3]=Image_process(The_split_Image4);
img[4]=Image_process(The_split_Image5);
img[5]=Image_process(The_split_Image6);
img[6]=Image_process(The_split_Image7);
IplImage* trainTempImg=cvCreateImage(cvSize(28,28),8,1);
//识别数字和字母
for(int i=2;i<=6;i++)
{
cvZero(trainTempImg);
cvResize(img[i],trainTempImg);
HOGDescriptor *hog=new HOGDescriptor(cvSize(28,28),cvSize(14,14),cvSize(7,7),cvSize(7,7),9);
vector<float>descriptors; //结果数组
hog->compute(trainTempImg, descriptors,Size(1,1), Size(0,0));
CvMat* SVMtrainMat=cvCreateMat(1,descriptors.size(),CV_32FC1);
int n=0;
//将特征保存到MAT中
for(vector<float>::iterator iter=descriptors.begin();iter!=descriptors.end();iter++)
{
cvmSet(SVMtrainMat,0,n,*iter);
n++;
}
ret[i] = svm.predict(SVMtrainMat); //检测结果
}
//识别汉
cvZero(trainTempImg);
cvResize(img[0],trainTempImg);
HOGDescriptor *hog1=new HOGDescriptor(cvSize(28,28),cvSize(14,14),cvSize(7,7),cvSize(7,7),9);
vector<float>descriptors1; //结果数组
hog1->compute(trainTempImg, descriptors1,Size(1,1), Size(0,0));
CvMat* SVMtrainMat1=cvCreateMat(1,descriptors1.size(),CV_32FC1);
int n=0;
for(vector<float>::iterator iter=descriptors1.begin();iter!=descriptors1.end();iter++)
{
cvmSet(SVMtrainMat1,0,n,*iter);
n++;
}
ret[0] = svm_char.predict(SVMtrainMat1);//检测结果
//识别字母
cvZero(trainTempImg);
cvResize(img[1],trainTempImg);
HOGDescriptor *hog2=new HOGDescriptor(cvSize(28,28),cvSize(14,14),cvSize(7,7),cvSize(7,7),9);
vector<float>descriptors2; //结果数组
hog2->compute(trainTempImg, descriptors2,Size(1,1), Size(0,0));
CvMat* SVMtrainMat2=cvCreateMat(1,descriptors2.size(),CV_32FC1);
n=0;
for(vector<float>::iterator iter=descriptors2.begin();iter!=descriptors2.end();iter++)
{
cvmSet(SVMtrainMat2,0,n,*iter);
n++;
}
ret[1] = svm_character.predict(SVMtrainMat2);//检测结果
//将ret[]中的结果转换为相应的类别标记flag
char ret_char[34]={'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H',
'J','K','L','M','N','P','Q','R','S','T','U','V','W','X','Y','Z'}; //排列的顺序为训练时txt文件排列顺序
char ret_character[26]={'A','B','C','D','E','F','G','H','J','K','L','M','N','O','P','Q','R','S','T',
'U','V','W','X','Y','Z','I'};
char chinese_character[34][4]={"澳","藏","川","鄂","甘","赣","港","贵","桂","黑","沪","吉","冀","津","晋","京","警","辽","鲁","蒙","闽","宁","青","琼","陕","苏","皖","湘","新","学","渝","粤","云","浙"};
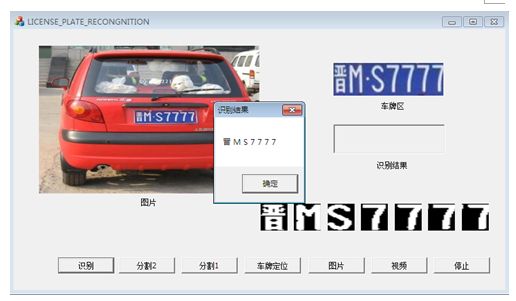
sprintf(result, "%s %c %c %c %c %c %c\r\n",chinese_character[ret[0]],ret_character[ret[1]],ret_char[ret[2]],ret_char[ret[3]],ret_char[ret[4]],ret_char[ret[5]],ret_char[ret[6]] );
MessageBox(CString(result),_T("识别结果"),MB_OK);自己设计的GUI效果如下: