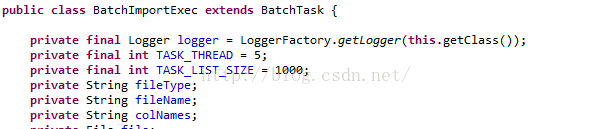
package batchpoc;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.Map;
public class BatchDTO implements Serializable {
private String pkBtTaskId = "";
private String taskName = "";
private String actionType = "";
private String taskDesc = "";
private String status = "";
private String commitedBy = "";
private Date commitedTime = null;
private String resultLog = "";
private String batchId = "";
private boolean headSkip = true;
private String errorLogPath = "";
private String logRootPath = "";
private boolean errorFlag = false;
private String campId = "";
private String[] data = null;
private long totalCount = 0;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result
+ ((actionType == null) ? 0 : actionType.hashCode());
result = prime * result + ((batchId == null) ? 0 : batchId.hashCode());
result = prime * result + ((campId == null) ? 0 : campId.hashCode());
result = prime * result
+ ((commitedBy == null) ? 0 : commitedBy.hashCode());
result = prime * result
+ ((commitedTime == null) ? 0 : commitedTime.hashCode());
result = prime * result + Arrays.hashCode(data);
result = prime * result + (errorFlag ? 1231 : 1237);
result = prime * result
+ ((errorLogPath == null) ? 0 : errorLogPath.hashCode());
result = prime * result + (headSkip ? 1231 : 1237);
result = prime * result
+ ((logRootPath == null) ? 0 : logRootPath.hashCode());
result = prime * result
+ ((pkBtTaskId == null) ? 0 : pkBtTaskId.hashCode());
result = prime * result
+ ((resultLog == null) ? 0 : resultLog.hashCode());
result = prime * result + ((status == null) ? 0 : status.hashCode());
result = prime * result
+ ((taskDesc == null) ? 0 : taskDesc.hashCode());
result = prime * result
+ ((taskName == null) ? 0 : taskName.hashCode());
result = prime * result + (int) (totalCount ^ (totalCount >>> 32));
return result;
}
public String getPkBtTaskId() {
return pkBtTaskId;
}
public void setPkBtTaskId(String pkBtTaskId) {
this.pkBtTaskId = pkBtTaskId;
}
public String getTaskName() {
return taskName;
}
public void setTaskName(String taskName) {
this.taskName = taskName;
}
public String getActionType() {
return actionType;
}
public void setActionType(String actionType) {
this.actionType = actionType;
}
public String getTaskDesc() {
return taskDesc;
}
public void setTaskDesc(String taskDesc) {
this.taskDesc = taskDesc;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getCommitedBy() {
return commitedBy;
}
public void setCommitedBy(String commitedBy) {
this.commitedBy = commitedBy;
}
public Date getCommitedTime() {
return commitedTime;
}
public void setCommitedTime(Date commitedTime) {
this.commitedTime = commitedTime;
}
public String getResultLog() {
return resultLog;
}
public void setResultLog(String resultLog) {
this.resultLog = resultLog;
}
public String getBatchId() {
return batchId;
}
public void setBatchId(String batchId) {
this.batchId = batchId;
}
public boolean isHeadSkip() {
return headSkip;
}
public void setHeadSkip(boolean headSkip) {
this.headSkip = headSkip;
}
public String getErrorLogPath() {
return errorLogPath;
}
public void setErrorLogPath(String errorLogPath) {
this.errorLogPath = errorLogPath;
}
public String getLogRootPath() {
return logRootPath;
}
public void setLogRootPath(String logRootPath) {
this.logRootPath = logRootPath;
}
public boolean isErrorFlag() {
return errorFlag;
}
public void setErrorFlag(boolean errorFlag) {
this.errorFlag = errorFlag;
}
public String getCampId() {
return campId;
}
public void setCampId(String campId) {
this.campId = campId;
}
public String[] getData() {
return data;
}
public void setData(String[] data) {
this.data = data;
}
public long getTotalCount() {
return totalCount;
}
public void setTotalCount(long totalCount) {
this.totalCount = totalCount;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (!(obj instanceof BatchDTO)) {
return false;
}
BatchDTO other = (BatchDTO) obj;
if (actionType == null) {
if (other.actionType != null) {
return false;
}
} else if (!actionType.equals(other.actionType)) {
return false;
}
if (batchId == null) {
if (other.batchId != null) {
return false;
}
} else if (!batchId.equals(other.batchId)) {
return false;
}
if (campId == null) {
if (other.campId != null) {
return false;
}
} else if (!campId.equals(other.campId)) {
return false;
}
if (commitedBy == null) {
if (other.commitedBy != null) {
return false;
}
} else if (!commitedBy.equals(other.commitedBy)) {
return false;
}
if (commitedTime == null) {
if (other.commitedTime != null) {
return false;
}
} else if (!commitedTime.equals(other.commitedTime)) {
return false;
}
if (!Arrays.equals(data, other.data)) {
return false;
}
if (errorFlag != other.errorFlag) {
return false;
}
if (errorLogPath == null) {
if (other.errorLogPath != null) {
return false;
}
} else if (!errorLogPath.equals(other.errorLogPath)) {
return false;
}
if (headSkip != other.headSkip) {
return false;
}
if (logRootPath == null) {
if (other.logRootPath != null) {
return false;
}
} else if (!logRootPath.equals(other.logRootPath)) {
return false;
}
if (pkBtTaskId == null) {
if (other.pkBtTaskId != null) {
return false;
}
} else if (!pkBtTaskId.equals(other.pkBtTaskId)) {
return false;
}
if (resultLog == null) {
if (other.resultLog != null) {
return false;
}
} else if (!resultLog.equals(other.resultLog)) {
return false;
}
if (status == null) {
if (other.status != null) {
return false;
}
} else if (!status.equals(other.status)) {
return false;
}
if (taskDesc == null) {
if (other.taskDesc != null) {
return false;
}
} else if (!taskDesc.equals(other.taskDesc)) {
return false;
}
if (taskName == null) {
if (other.taskName != null) {
return false;
}
} else if (!taskName.equals(other.taskName)) {
return false;
}
if (totalCount != other.totalCount) {
return false;
}
return true;
}
}
BatchTask.java
package batchpoc;
import java.util.concurrent.BlockingQueue;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public abstract class BatchTask{
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
public final static String TXT_IMP_EXP = "101";
public final static String EXCEL_IMP_EXP = "102";
public final static String TASK_RUNNING = "2";
public final static String TASK_FINISHED = "4";
public final static String TASK_FAILED = "5";
protected BatchDTO taskContext = null;
public BatchTask(BatchDTO taskContext) {
this.taskContext = taskContext;
}
public abstract void doBatch() throws Exception;
}
package batchpoc;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.openxml4j.opc.PackageAccess;
public class XLSEnumerationTask extends EnumerationEnginee {
public XLSEnumerationTask(BlockingQueue
XLSXParser.java-这个大了,就是用来处理大数据量的XLS文件的
package batchpoc;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.openxml4j.opc.PackageAccess;
import org.apache.poi.ss.usermodel.BuiltinFormats;
import org.apache.poi.ss.usermodel.DataFormatter;
import org.apache.poi.xssf.eventusermodel.ReadOnlySharedStringsTable;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.StylesTable;
import org.apache.poi.xssf.usermodel.XSSFCellStyle;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
/**
*/
public class XLSXParser {
private final Logger logger = LoggerFactory.getLogger(getClass());
/**
* The type of the data value is indicated by an attribute on the cell. The
* value is usually in a "v" element within the cell.
*/
enum xssfDataType {
BOOL, ERROR, FORMULA, INLINESTR, SSTINDEX, NUMBER,
}
int countrows = 0;
/**
* Derived from http://poi.apache.org/spreadsheet/how-to.html#xssf_sax_api
*
* Also see Standard ECMA-376, 1st edition, part 4, pages 1928ff, at
* http://www.ecma-international.org/publications/standards/Ecma-376.htm
*
* A web-friendly version is http://openiso.org/Ecma/376/Part4
*/
class MyXSSFSheetHandler extends DefaultHandler {
/**
* Table with styles
*/
private StylesTable stylesTable;
private Map dataMap = new HashMap();
/**
* Table with unique strings
*/
private ReadOnlySharedStringsTable sharedStringsTable;
/**
* Destination for data
*/
// private final PrintStream output;
/**
* Number of columns to read starting with leftmost
*/
// private final int minColumnCount;
// Set when V start element is seen
private boolean vIsOpen;
// Set when cell start element is seen;
// used when cell close element is seen.
private xssfDataType nextDataType;
// Used to format numeric cell values.
private short formatIndex;
private String formatString;
private final DataFormatter formatter;
private int thisRow = 0;
private int thisColumn = -1;
// The last column printed to the output stream
private int lastColumnNumber = -1;
// Gathers characters as they are seen.
private StringBuffer value;
/**
* Accepts objects needed while parsing.
*
* @param styles
* Table of styles
* @param strings
* Table of shared strings
* @param cols
* Minimum number of columns to show
* @param target
* Sink for output
*/
public MyXSSFSheetHandler(StylesTable styles,
ReadOnlySharedStringsTable strings, Map dataMap) {
this.stylesTable = styles;
this.sharedStringsTable = strings;
// this.minColumnCount = cols;
this.value = new StringBuffer();
this.nextDataType = xssfDataType.NUMBER;
this.formatter = new DataFormatter();
this.dataMap = dataMap;
}
/*
* (non-Javadoc)
*
* @see
* org.xml.sax.helpers.DefaultHandler#startElement(java.lang.String,
* java.lang.String, java.lang.String, org.xml.sax.Attributes)
*/
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
if ("inlineStr".equals(name) || "v".equals(name)) {
vIsOpen = true;
// Clear contents cache
value.setLength(0);
}
// c => cell
else if ("c".equals(name)) {
// Get the cell reference
String r = attributes.getValue("r");
int firstDigit = -1;
for (int c = 0; c < r.length(); ++c) {
if (Character.isDigit(r.charAt(c))) {
firstDigit = c;
break;
}
}
thisColumn = nameToColumn(r.substring(0, firstDigit));
// Set up defaults.
this.nextDataType = xssfDataType.NUMBER;
this.formatIndex = -1;
this.formatString = null;
String cellType = attributes.getValue("t");
String cellStyleStr = attributes.getValue("s");
if ("b".equals(cellType))
nextDataType = xssfDataType.BOOL;
else if ("e".equals(cellType))
nextDataType = xssfDataType.ERROR;
else if ("inlineStr".equals(cellType))
nextDataType = xssfDataType.INLINESTR;
else if ("s".equals(cellType))
nextDataType = xssfDataType.SSTINDEX;
else if ("str".equals(cellType))
nextDataType = xssfDataType.FORMULA;
else if (cellStyleStr != null) {
// It's a number, but almost certainly one
// with a special style or format
int styleIndex = Integer.parseInt(cellStyleStr);
XSSFCellStyle style = stylesTable.getStyleAt(styleIndex);
this.formatIndex = style.getDataFormat();
this.formatString = style.getDataFormatString();
if (this.formatString == null)
this.formatString = BuiltinFormats
.getBuiltinFormat(this.formatIndex);
}
}
}
/**
* 取值
*
* @param str
* @return
*/
public String checkNumber(String str) {
str = str.trim();
String str2 = "";
if (str != null && !"".equals(str)) {
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) >= 48 && str.charAt(i) <= 57) {
str2 += str.charAt(i);
}
}
}
return str2.trim();
}
/*
* (non-Javadoc)
*
* @see org.xml.sax.helpers.DefaultHandler#endElement(java.lang.String,
* java.lang.String, java.lang.String)
*/
public void endElement(String uri, String localName, String name)
throws SAXException {
String thisStr = null;
// System.out.println("endElement----->" + name);
// v => contents of a cell
if ("v".equals(name)) {
// Process the value contents as required.
// Do now, as characters() may be called more than once
switch (nextDataType) {
case BOOL:
char first = value.charAt(0);
thisStr = first == '0' ? "FALSE" : "TRUE";
break;
case ERROR:
thisStr = "\"ERROR:" + value.toString() + '"';
break;
case FORMULA:
// A formula could result in a string value,
// so always add double-quote characters.
thisStr = '"' + value.toString() + '"';
break;
case INLINESTR:
// TODO: have seen an example of this, so it's untested.
XSSFRichTextString rtsi = new XSSFRichTextString(
value.toString());
if (rtsi != null) {
thisStr = rtsi.toString().trim();
thisStr = thisStr.substring(1, thisStr.length() - 1);
}
break;
case SSTINDEX:
String sstIndex = value.toString();
try {
int idx = Integer.parseInt(sstIndex);
XSSFRichTextString rtss = new XSSFRichTextString(
sharedStringsTable.getEntryAt(idx));
if (rtss != null) {
/*
* thisStr = rtss.toString().trim()
* .replaceAll("\\s*", "");
*/
thisStr = checkNumber(rtss.toString().trim());
/*
* thisStr = thisStr .substring(1, thisStr.length()
* - 1);
*/
}
} catch (NumberFormatException ex) {
logger.error("Failed to parse SST index '" + sstIndex
+ "': " + ex.toString(), ex);
}
break;
case NUMBER:
String n = value.toString();
if (this.formatString != null)
thisStr = formatter.formatRawCellContents(
Double.parseDouble(n), this.formatIndex,
this.formatString);
else
thisStr = n;
break;
default:
thisStr = "(TODO: Unexpected type: " + nextDataType + ")";
break;
}
// Output after we've seen the string contents
// Emit commas for any fields that were missing on this row
if (lastColumnNumber == -1) {
lastColumnNumber = 0;
}
// for (int i = lastColumnNumber; i < thisColumn; ++i) {
// System.out.print(" col: " + i + " ");
// }
// Might be the empty string.
// output.print(thisStr);
// System.out.println(thisStr);
// System.out.println("thisRow...." + thisRow);
if (thisRow > 0 && thisStr != null
&& thisStr.trim().length() > 0) {
// logger.info("dataMap.put()");
dataMap.put(String.valueOf(thisColumn), thisStr);
}
// Update column
if (thisColumn > -1)
lastColumnNumber = thisColumn;
} else if ("row".equals(name)) {
try {
if (dataMap.keySet().size() > 0) {
dataMap = MapUtil.sortByValue(dataMap);
if (toQueue) {
queue.put(dataMap);
}
}
} catch (Exception e) {
logger.error(
"put data into queue error: " + e.getMessage(), e);
}
thisRow++;
dataMap = new HashMap();
lastColumnNumber = -1;
}
}
/**
* Captures characters only if a suitable element is open. Originally
* was just "v"; extended for inlineStr also.
*/
public void characters(char[] ch, int start, int length)
throws SAXException {
if (vIsOpen)
value.append(ch, start, length);
}
/**
* Converts an Excel column name like "C" to a zero-based index.
*
* @param name
* @return Index corresponding to the specified name
*/
private int nameToColumn(String name) {
int column = -1;
for (int i = 0; i < name.length(); ++i) {
int c = name.charAt(i);
column = (column + 1) * 26 + c - 'A';
}
return column;
}
}
// /////////////////////////////////////
private OPCPackage xlsxPackage;
private BlockingQueue
} else if ("row".equals(name)) {
try {
if (dataMap.keySet().size() > 0) {
dataMap = MapUtil.sortByValue(dataMap);
if (toQueue) {
queue.put(dataMap);
}
}
} catch (Exception e) {
logger.error(
"put data into queue error: " + e.getMessage(), e);
}
其它辅助类
UUID.java
package batchpoc;
public class UUID {
protected static int count = 0;
public static synchronized String getUUID() {
count++;
long time = System.currentTimeMillis();
String timePattern = Long.toHexString(time);
int leftBit = 14 - timePattern.length();
if (leftBit > 0) {
timePattern = "0000000000".substring(0, leftBit) + timePattern;
}
String uuid = timePattern
+ Long.toHexString(Double.doubleToLongBits(Math.random()))
+ Long.toHexString(Double.doubleToLongBits(Math.random()))
+ "000000000000000000";
uuid = uuid.substring(0, 32).toUpperCase();
return uuid;
}
}
GuidCreator.java
package batchpoc;
import java.net.*;
import java.util.*;
import java.security.*;
public class GuidCreator {
private String seedingString = "";
private String rawGUID = "";
private boolean bSecure = false;
private static Random myRand;
private static SecureRandom mySecureRand;
private static String s_id;
public static final int BeforeMD5 = 1;
public static final int AfterMD5 = 2;
public static final int FormatString = 3;
static {
mySecureRand = new SecureRandom();
long secureInitializer = mySecureRand.nextLong();
myRand = new Random(secureInitializer);
try {
s_id = InetAddress.getLocalHost().toString();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
public GuidCreator() {
}
/*
* Constructor with security option. Setting secure true enables each random
* number generated to be cryptographically strong. Secure false defaults to
* the standard Random function seeded with a single cryptographically
* strong random number.
*/
public GuidCreator(boolean secure) {
bSecure = secure;
}
/*
* Method to generate the random GUID
*/
private void getRandomGUID(boolean secure) {
MessageDigest md5 = null;
StringBuffer sbValueBeforeMD5 = new StringBuffer();
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
System.out.println("Error: " + e);
}
try {
long time = System.currentTimeMillis();
long rand = 0;
if (secure) {
rand = mySecureRand.nextLong();
} else {
rand = myRand.nextLong();
}
// This StringBuffer can be a long as you need; the MD5
// hash will always return 128 bits. You can change
// the seed to include anything you want here.
// You could even stream a file through the MD5 making
// the odds of guessing it at least as great as that
// of guessing the contents of the file!
sbValueBeforeMD5.append(s_id);
sbValueBeforeMD5.append(":");
sbValueBeforeMD5.append(Long.toString(time));
sbValueBeforeMD5.append(":");
sbValueBeforeMD5.append(Long.toString(rand));
seedingString = sbValueBeforeMD5.toString();
md5.update(seedingString.getBytes());
byte[] array = md5.digest();
StringBuffer sb = new StringBuffer();
for (int j = 0; j < array.length; ++j) {
int b = array[j] & 0xFF;
if (b < 0x10)
sb.append('0');
sb.append(Integer.toHexString(b));
}
rawGUID = sb.toString();
} catch (Exception e) {
System.out.println("Error:" + e);
}
}
public String createNewGuid(int nFormatType, boolean secure) {
getRandomGUID(secure);
String sGuid = "";
if (BeforeMD5 == nFormatType) {
sGuid = this.seedingString;
} else if (AfterMD5 == nFormatType) {
sGuid = this.rawGUID;
} else {
sGuid = this.toString();
}
return sGuid;
}
public String createNewGuid(int nFormatType) {
return this.createNewGuid(nFormatType, this.bSecure);
}
/*
* Convert to the standard format for GUID (Useful for SQL Server
* UniqueIdentifiers, etc.) Example: C2FEEEAC-CFCD-11D1-8B05-00600806D9B6
*/
public String toString() {
String raw = rawGUID.toUpperCase();
StringBuffer sb = new StringBuffer();
sb.append(raw.substring(0, 8));
sb.append("-");
sb.append(raw.substring(8, 12));
sb.append("-");
sb.append(raw.substring(12, 16));
sb.append("-");
sb.append(raw.substring(16, 20));
sb.append("-");
sb.append(raw.substring(20));
return sb.toString();
}
public static void main(String args[]) {
GuidCreator myGUID = new GuidCreator();
// System.out.println("Seeding String="
// + myGUID.createNewGuid(GuidCreator.BeforeMD5));
// System.out.println("rawGUID="
// + myGUID.createNewGuid(GuidCreator.AfterMD5));
System.out.println("RandomGUID="
+ myGUID.createNewGuid(GuidCreator.AfterMD5));
}
}
GuidByRandom.java
package batchpoc;
import java.text.SimpleDateFormat;
public class GuidByRandom {
private static int cnt = 0;
public static synchronized String getGUID() throws Exception {
StringBuffer code = new StringBuffer();
try {
java.util.Date dt = new java.util.Date(System.currentTimeMillis());
SimpleDateFormat fmt = new SimpleDateFormat("yyyyMMddHHmmssSSS");//format system time
String randomCode = fmt.format(dt);
cnt = (cnt + 1) % 10000; // You are free the set %100 to
// 1000,100000
code.append(randomCode).append(cnt);
return code.toString();
} catch (Exception e) {
throw new Exception("createFileName error:" + e.getMessage(), e);
}
}
public static void main(String[] args) throws Exception {
System.out.println(getGUID());
}
}
Constants.java
package util;
public class Constants {
public final static String ENUMERATION_EXCEL_TASK = "excel";
public final static String ENUMERATION_TXT_TASK = "txt";
}
StringUtil.java
package util;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.Calendar;
import java.util.Date;
import java.sql.Blob;
import java.text.*;
import java.util.regex.Pattern;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class StringUtil {
protected final static Logger logger = LoggerFactory
.getLogger(StringUtil.class);
public static Object unserializeObj(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
// 反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
logger.error("unserializeObj error:" + e.getMessage(), e);
}
return null;
}
public static byte[] serializeObj(Object obj) {
ByteArrayOutputStream bout = null;
ObjectOutputStream out = null;
byte[] bytes = null;
try {
bout = new ByteArrayOutputStream();
out = new ObjectOutputStream(bout);
out.writeObject(obj);
out.flush();
bytes = bout.toByteArray();
} catch (Exception e) {
logger.error("serializeObject error:" + e.getMessage(), e);
} finally {
try {
if (out != null) {
out.close();
out = null;
}
} catch (Exception e) {
}
try {
if (bout != null) {
bout.close();
bout = null;
}
} catch (Exception e) {
}
}
return bytes;
}
public static String escpaeCharacters(String s) {
String val = "";
try {
if (s == null || s.length() < 1) {
return s;
}
StringBuilder sb = new StringBuilder(s.length() + 16);
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
switch (c) {
case '\'':
sb.append("′");// ´");
break;
case '′':
sb.append("′");// ´");
break;
case '\"':
sb.append(""");
break;
case '"':
sb.append(""");
break;
case '&':
sb.append("&");
break;
case '#':
sb.append("#");
break;
case '\\':
sb.append('¥');
break;
case '>':
sb.append('>');
break;
case '<':
sb.append('<');
break;
default:
sb.append(c);
break;
}
}
val = sb.toString();
return val;
} catch (Exception e) {
logger.error("sanitized characters error: " + e.getMessage(), e);
return s;
}
}
public static boolean isNotNullOrEmpty(String str) {
return str != null && str.trim().length() > 0;
}
public static boolean isNull(Object... params) {
if (params == null) {
return true;
}
for (Object obj : params) {
if (obj == null) {
return true;
}
}
return false;
}
public static String getString(Object val) {
String rtnVal = "";
try {
rtnVal = (String) val;
rtnVal = rtnVal.trim();
} catch (Exception e) {
rtnVal = "";
}
return rtnVal;
}
public static String nullToStr(Object val) {
return ((val == null) ? "" : String.valueOf(val).trim());
}
public static int getInt(Object val) {
int rtnVal = -1;
String rtnValStr = "-1";
try {
rtnValStr = (String) val;
rtnValStr = rtnValStr.trim();
rtnVal = Integer.parseInt(rtnValStr);
} catch (Exception e) {
rtnVal = -1;
}
return rtnVal;
}
public static String convertDateToStr(Date dt) {
String dateStr = "";
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
if (dt != null) {
dateStr = format.format(dt);
}
return dateStr;
}
public static String convertDateToStr(Date dt, String formatter) {
String dateStr = "";
DateFormat format = new SimpleDateFormat(formatter);
if (dt != null) {
dateStr = format.format(dt);
}
return dateStr;
}
public static Date convertStrToDateByFormat(String dateStr) {
String inputDateStr = "";
SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd");
Date date = null;
try {
inputDateStr = dateStr;
if (dateStr == null || dateStr.trim().length() < 1) {
inputDateStr = "1900-01-01";
}
java.util.Date d = sf.parse(inputDateStr.toString().trim());
date = new Date(d.getTime());
} catch (Exception e) {
logger.error(
"convertStrToDateByFormat(" + dateStr + ") error:"
+ e.getMessage(), e);
}
return date;
}
public static Date convertStrToDateByFormat(String dateStr, String formatter) {
String inputDateStr = "";
SimpleDateFormat sf = new SimpleDateFormat(formatter);
Date date = null;
try {
inputDateStr = dateStr;
if (dateStr == null || dateStr.trim().length() < 1) {
inputDateStr = "1900-01-01 01:01:01";
}
java.util.Date d = sf.parse(inputDateStr.toString().trim());
date = new Date(d.getTime());
} catch (Exception e) {
logger.error(
"convertStrToDateByFormat(" + dateStr + ") error:"
+ e.getMessage(), e);
}
return date;
}
public static Object deepcopy(Object src) throws Exception {
ByteArrayOutputStream byteout = null;
ObjectOutputStream out = null;
ByteArrayInputStream bytein = null;
ObjectInputStream in = null;
Object dest = null;
try {
byteout = new ByteArrayOutputStream();
out = new ObjectOutputStream(byteout);
out.writeObject(src);
bytein = new ByteArrayInputStream(byteout.toByteArray());
in = new ObjectInputStream(bytein);
dest = (Object) in.readObject();
} catch (Exception e) {
throw new Exception("deep copy object[" + src
+ "] error cause by: " + e.getMessage(), e);
} finally {
try {
if (in != null) {
in.close();
in = null;
}
} catch (Exception e) {
}
try {
if (bytein != null) {
bytein.close();
bytein = null;
}
} catch (Exception e) {
}
try {
if (out != null) {
out.close();
out = null;
}
} catch (Exception e) {
}
try {
if (byteout != null) {
byteout.close();
byteout = null;
}
} catch (Exception e) {
}
}
return dest;
}
public static Object blobToObject(Blob blob) throws Exception {
Object obj = null;
ObjectInputStream in = null;
try {
in = new ObjectInputStream(blob.getBinaryStream());
obj = in.readObject();
return obj;
} catch (Exception e) {
throw new Exception(e);
} finally {
try {
if (in != null) {
in.close();
in = null;
}
} catch (Exception e) {
}
}
}
public static long dateSub(String dateStr) throws ParseException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd");
java.util.Date d = sdf.parse(dateStr);
Calendar calendar = Calendar.getInstance();
calendar.setTime(new Date());
long currentTime = calendar.getTimeInMillis();
calendar.setTime(d);
long timeEnd = calendar.getTimeInMillis();
long theDay = (timeEnd - currentTime) / (1000 * 60 * 60 * 24);
return theDay;
}
public static boolean isNumeric(String str) {
Pattern pattern = Pattern.compile("[0-9]*");
return pattern.matcher(str).matches();
}
}
1. 创建一个maven项目
2. 创建com.CoberturaStart.java
package com;
public class CoberturaStart {
public void helloEveryone(){
System.out.println("=================================================
我并不知道出现这个问题的实际原理,只是通过其他朋友的博客,文章得知的一个解决方案,目前先记录一个解决方法,未来要是真了解以后,还会继续补全.
在mysql5中有一个safe update mode,这个模式让sql操作更加安全,据说要求有where条件,防止全表更新操作.如果必须要进行全表操作,我们可以执行
SET
public class DeleteSpecificChars {
/**
* Q 63 在字符串中删除特定的字符
* 输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。
* 例如,输入”They are students.”和”aeiou”,则删除之后的第一个字符串变成”Thy r stdnts.”
*/
public static voi
File descriptors are represented by the C int type. Not using a special type is often considered odd, but is, historically, the Unix way. Each Linux process has a maximum number of files th