阿里巴巴分布式缓存服务Tair的热点数据散列机制
作者丨刘欢(浅奕)

问题背景
分布式缓存一般被定义为一个数据集合,它将数据分布(或分区)于任意数目的集群节点上。集群中的一个具体节点负责缓存中的一部分数据,整体对外提供统一的访问接口 [1]。分布式缓存一般基于冗余备份机制实现数据高可用,又被称为内存数据网格(IMDG, in-memory data grid)。在云平台飞速发展的今天,作为提升应用性能的重要手段,分布式缓存技术在工业界得到了越来越广泛的关注和研发投入 [2]。弹性缓存平台 [3] 是分布式缓存集群在云计算场景下的新形态,其强调集群的动态扩展性与高可用性。动态扩展性表达了缓存平台可提供透明的服务扩展的能力,高可用性则表达了缓存平台可以容忍节点失效。
Tair 是阿里巴巴集团自研的弹性缓存 / 存储平台,在内部有着大量的部署和使用。Tair 的核心组件是一个高性能、可扩展、高可靠的 NoSQL 存储系统。目前支持 MDB、LDB、RDB 等存储引擎。其中 MDB 是类似 Memcached 的内存存储引擎,LDB 是使用 LSM Tree 的持久化磁盘 KV 存储引擎,RDB 是支持 Queue、Set、Maps 等数据结构的内存及持久化存储引擎。
Tair 的数据分片和路由算法采用了 Amazon 于 2007 年提出的一种改进的一致性哈希算法 [4]。该算法将整个哈希空间分为若干等大小的 Q 份数据分区(也称为虚拟节点,Q>>N,N 为缓存节点数),每个缓存节点依据其处理能力分配不同数量的数据分区。客户端请求的数据 Key 值经哈希函数映射至哈希环上的位置记为 token,token 值再次被哈希映射为某一分区标识。得到分区标识后,客户端从分区服务器映射表中查询存放该数据分区的缓存节点后进行数据访问。使用该算法对相同数据 Key 进行计算,其必然会被映射到固定的 DataServer 上,如图:
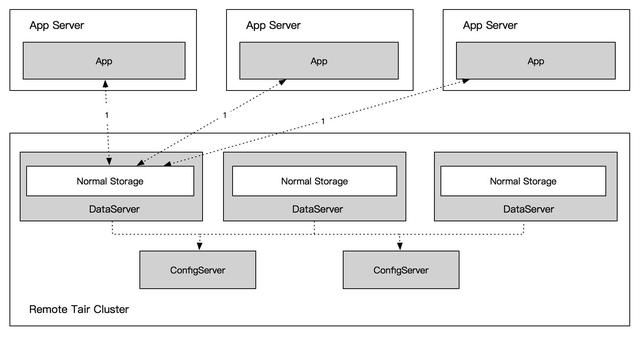
此时 DataServer 单节点的读写性能便成了单数据 Key 的读写性能瓶颈,且无法通过水平扩展节点的方式来解决。由于阿里巴巴集团内部电商系的促销活动天然的存在热点数据,所以要增强整个弹性缓存 / 存储平台的稳定性和服务能力,就必须提升热点数据的读写能力,使其能做到水平扩展。
本文基于 Tair 的存储和访问原理,对缓存的读写热点问题进行讨论,并给出一个满足现阶段需求的热点数据读写问题的解决方案。
解决方案
解决方案分为三部分:热点识别、读热点方案和写热点方案。其中读写热点方案都是以服务端能对热点访问进行精准的识别为前提的。另外对于可以提前预知热点 Key 的情况,也提供相应的客户端 API 以支持特定数据 Key 或者特定 Namespace 的所有数据 Key 预先标记为热点 Key 的能力。
DataServer 上的热点统计过程
DataServer 收到客户端的请求后,由每个具体处理请求的工作线程(Worker Thread)进行请求的统计。工作线程用来统计热点的数据结构均为 ThreadLocal 模式的数据结构,完全无锁化设计。热点识别算法使用精心设计的多级加权 LRU 链和 HashMap 组合的数据结构,在保证服务端请求处理效率的前提下进行请求的全统计,支持 QPS 热点和流量热点(即请求的 QPS 不大但是数据本身过大而造成的大流量所形成的热点)的精准识别。每个采样周期结束时,工作线程会将统计的数据结构转交到后台的统计线程池进行分析处理。统计工作异步在后台进行,不抢占正常的数据请求的处理资源。
读热点方案
服务端设计
原始 Tair 的数据访问方式是先进行 Hash(Key)%BucketCount 的计算,得出具体的数据存储 Bucket,再检索数据路由表找到该 Bucket 所在的 DataServer 后对其进行读写请求的。所以相同 Key 的读写请求必然落在固定的 DataServer 上,且无法通过水平扩展 DataServer 数量来解决。
本方案通过在 DataServer 上划分一块 HotZone 存储区域的方式来解决热点数据的访问。该区域存储当前产生的所有读热点的数据,由客户端配置的缓存访问逻辑来处理各级缓存的访问。多级缓存架构如下:

所有 DataServer 的 HotZone 存储区域之间没有权重关系,每个 HotZone 都存储相同的读热点数据。客户端对热点数据 Key 的请求会随机到任意一台 DataServer 的 HotZone 区域,这样单点的热点请求就被散列到多个节点乃至整个集群。
客户端设计
客户端逻辑
当客户端在第一次请求前初始化时,会获取整个 Tair 集群的节点信息以及完整的数据路由表,同时也会获取配置的热点散列机器数(即客户端访问的 HotZone 的节点范围)。随后客户端随机选择一个 HotZone 区域作为自身固定的读写 HotZone 区域。在 DataServer 数量和散列机器数配置未发生变化的情况下,不会改变选择。即每个客户端只访问唯一的 HotZone 区域。
客户端收到服务端反馈的热点 Key 信息后,至少在客户端生效 N 秒。在热点 Key 生效期间,当客户端访问到该 Key 时,热点的数据会首先尝试从 HotZone 节点进行访问,此时 HotZone 节点和源数据 DataServer 节点形成一个二级的 Cache 模型。客户端内部包含了两级 Cache 的处理逻辑,即对于热点数据,客户端首先请求 HotZone 节点,如果数据不存在,则继续请求源数据节点,获取数据后异步将数据存储到 HotZone 节点里。使用 Tair 客户端的应用常规调用获取数据的接口即可,整个热点的反馈、识别以及对多级缓存的访问对外部完全透明。HotZone 缓存数据的一致性由客户端初始化时设置的过期时间来保证,具体的时间由具体业务对缓存数据不一致的最大容忍时间来决定。
客户端存储于本地的热点反馈过期后,数据 Key 会到源 DataServer 节点读取。如果该 Key 依旧在服务端处于热点状态,客户端会再次收到热点反馈包。因为所有客户端存储于本地的热点反馈信息的失效节奏不同,所以不会出现同一瞬间所有的请求都回源的情况。即使所有请求回源,也仅需要回源读取一次即可,最大的读取次数仅为应用机器数。若回源后发现该 Key 已不是热点,客户端便回到常规的访问模式。
散列比和 QPS 偏差的关系

写热点方案
服务端设计
处理方式
对于写热点,因为一致性的问题,难以使用多级缓存的方式来解决。如果采用写本地 Cache,再异步更新源 DataServer 的方案。那么在 Cache 写入但尚未更新的时候,如果业务机器宕机,就会有已写数据丢失的问题。同时,本地 Cache 会导致进行数据更新的某应用机器当前更新周期内的修改对其他应用机器不可见,从而延长数据不一致的时间。故多级 Cache 的方案无法支持写热点。最终写热点采用在服务端进行请求合并的方式进行处理。
热点 Key 的写请求在 IO 线程被分发到专门的热点合并线程处理,该线程根据 Key 对写请求进行一定时间内的合并,随后由定时线程按照预设的合并周期将合并后的请求提交到引擎层。合并过程中请求结果暂时不返回给客户端,等请求合并写入引擎成功后统一返回。这样做不会有一致性的问题,不会出现写成功后却读到旧数据,也避免了 LDB 集群返回成功,数据并未落盘的情况(假写)。具体的合并周期在服务端可配置,并支持动态修改生效。
客户端设计
写热点的方案对客户端完全透明,不需要客户端做任何修改。
性能指标
LDB 集群实际压测效果为单 Key 合并能做到单 Key 百万的 QPS(1ms 合并,不限制合并次数),线上实际集群为了尽可能保证实时性,均采用了最大 0.1ms 以及单次最大合并次数为 100 次的限制。这样单 Key 在引擎层的最大落盘 QPS 就能控制在 10000 以下(而合并的 QPS 则取决于应用的访问频率)。Tair 服务端的包处理是完全异步化的,进行热点请求的合并操作并不阻塞对其他请求的处理。唯一的影响就是增大客户端对热点 key 的写请求的 RT. 按照现在的配置,最坏情况下,客户端的热点 key 的写操作会增大 0.1ms,这个影响是微乎其微的。
参考文献
[1] Oracle Coherence,http://www.oracle.com/technetwork/cn/middleware/coherence/distributed-caching-089211-zhs.html
[2] Qin XL, Zhang WB, Wei J, Wang W, Zhong H, Huang T. Progress and challenges of distributed caching techniques in cloud computing. Ruanjian Xuebao/Journal of Software, 2013,24(1):50−66 (in Chinese). http://www.jos.org.cn/1000-9825/4276.htm
[3] Gualtieri M, Rymer JR. The forrester wave: Elastic caching platforms.Q2, 2010. ftp://ftp.software.ibm.com/software/solutions/soa/pdfs/wave_elastic_caching_platforms_q2_2010.pdf
[4] Hastorun D, Jampani M, Kakulapati G, Pilchin A, Sivasubramanian S, Vosshall P, Vogels W. Dynamo: Amazon’s highly available key-value store.In: Proc. of the ACM Symp. on Operating Systems Principles (SOSP 2007). 2007. 205−220. [doi: 10.1145/1323293.1294281]