golang之基本数据类型(字符串/字符操作)、类型转换
Go语言中有丰富的数据类型,除了基本的整型、浮点型、布尔型、字符串外,还有数组、切片、结构体、函数、map、通道(channel)等。
一、整型
# 整型分为以下两个大类: 按长度分为:int8、int16、int32、int64
# 对应的无符号整型:uint8、uint16、uint32、uint64
# 其中,uint8就是我们熟知的byte型,
# int16对应C语言中的short型,
# int64对应C语言中的long型。
| 类型 | 描述 |
|---|---|
| uint8 | 无符号 8位整型 (0 到 255) |
| uint16 | 无符号 16位整型 (0 到 65535) |
| uint32 | 无符号 32位整型 (0 到 4294967295) |
| uint64 | 无符号 64位整型 (0 到 18446744073709551615) |
| int8 | 有符号 8位整型 (-128 到 127) |
| int16 | 有符号 16位整型 (-32768 到 32767) |
| int32 | 有符号 32位整型 (-2147483648 到 2147483647) |
| int64 | 有符号 64位整型 (-9223372036854775808 到 9223372036854775807) |
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
注意: 在使用int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。
八进制&十六进制
package main
import "fmt"
func main() {
var a int = 10
var b int = 077 //8进制
var c int = 0xff //16进制
fmt.Println(a, b) // 10, 63
fmt.Printf("%b", a) // 二进制:1010
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
//变量的内存地址
fmt.Printf("%p \n", &c) //占位符%p表示十六进制的内存地址
}
二、浮点型
float32可以显示8位,精确到7位
var a float32 = 123456.785
fmt.Println(a) ---------> 结果:123456.78
var a float32 = 1.23456785
fmt.Println(a) ---------> 结果:1.2345679
float64,可以显示17位,精确到16位(含整数位)
// 任何编程语言的浮点型都是不精确的,如果涉及到金融类业务,应该使用字符串类型存数据
// Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准:
// float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64
// 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
// 打印浮点数时,可以使用fmt包配合动词%f,代码如下:
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi) //3.141593
fmt.Printf("%.2f\n", math.Pi) //3.14,保留两位小数
}
三、布尔值
// Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
// 注意:
1、布尔类型变量的默认值为false。
2、Go语言中不允许将整型强制转换为布尔型.
3、布尔型无法参与数值运算,也无法与其他类型进行转换。
true || false ----> true
true && true ----> true
!true ----> false
四、字符串
1、Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。
2、Go 语言里的字符串的内部实现使用UTF-8编码。
3、字符串的值为双引号("")中的内容,可以在Go语言的源码中直接添加非ASCII码字符,
// 1、Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、
// float32、float64 等)一样。
// 2、Go 语言里的字符串的内部实现使用UTF-8编码。
// 3、字符串的值为双引号("")中的内容,可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"
// 举例 : 打印一个windows平台的路径
package main
import (
"fmt"
)
func main() {
fmt.Println("str := \"c:\\Code\\lesson1\\go.exe\"")
}
// 多行字符串:go语言中要定义一个多行字符串时,就必须使用反引号字符
func main() {
s1 := `
这是
多行
文本
`
} // 反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
4.1、字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
package main
import (
"fmt"
"strings"
)
func main() {
var s string = "言念君子,温其如玉"
fmt.Println(len(s)) // 27,汉字占3个字节长度
//字符串拼接
var s1 = "python"
var s2 = "go"
fmt.Println(s1 + s2) //pythongo
s3 := fmt.Sprintf("%s---%s", s1, s2)
fmt.Println(s3) //python---go
//分割字符串
res := strings.Split(s, ",")
fmt.Println(res) //[言念君子,温其如玉]
// 判断是否包含
res2 := strings.Contains(s1, "on")
fmt.Println(res2) // true
// 判断前缀后缀
res3 := strings.HasPrefix(s1, "py")
res4 := strings.HasSuffix(s1, "on")
fmt.Println(res3, res4) // true true
// 子串出现的位置
var s4 string= "applepen"
fmt.Println(strings.Index(s4, "p")) // 1
fmt.Println(strings.LastIndex(s4, "p")) // 5
// join()
a1 := []string{"python","php","go"}
fmt.Println(strings.Join(a1, "-")) // python-php-go
}
4.2、字符串输出格式化
通过使用fmt.Printf("")来实现字符串输出时的格式化,实现如下:
var a int = 520
fmt.Printf("xxx,%d",a) ----->结果:"xxx,520"
其中%d用来占位,a用来传值给%d
其它常用指令符如下:
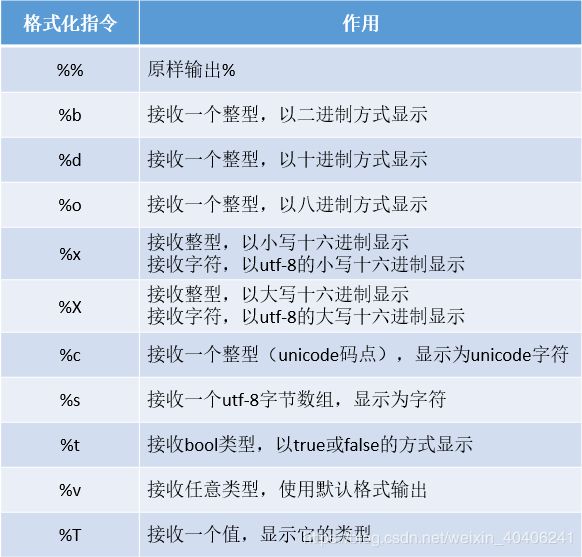
4.3、按索引访问字符串字节
字符串“wo我”,长度为5,即5个字节,“w“”o“分别占一个字节,”我“占3个字节。字符串会按照字节,从前到后依次用索引标记,第一个字节为0,第二个字节为1,以此类推。
我们可以通过索引访问到指定字节。如下:(得到的是utf-8的十进制表示)
var a = "wo我"
fmt.Println(a[0]) ---->结果是119,119是“w”的utf-8编码的十进制表示
fmt.Println(a[2]) ---->结果是230,“我”占3个字节,230是我的第一个字节
4.4、字符串切片操作
形如:字符串[起始字节索引:结束字节索引]。省略起始索引,默认就从0开始,省略结束索引,默认就以最后一个索引结束。这样我们可以得到一个新的字符串。
强调:1、索引是按字节标记的;
2、[起始索引:终止索引]是顾头不顾尾,或者说左闭右开。
var a = "我很帅"
var b = a[0:3]
fmt.Println(b) ---->结果:"我",[0:2]刚好切出了表示"我"的三个字节
var c = a[3:]
fmt.Println(c) ---->结果:"很帅",结束索引被省略,默认切到最后
var d = a[:3]
fmt.Println(d) ---->结果:"我",起始索引被省略,默认从头开始切
var e = a[:]
fmt.Println(e) ---->结果:"我很帅",都省略,默认从头切到最后
4.5、字符串的遍历
我们使用for i,v := range 字符串 {} 来遍历字符串
for i,v := range "我是haha" {
fmt.Println(i,v)
}
结果:0 25105 //从0开始计数,25105是unicode中“我”的序号(十进制)
3 26159 //因为“我”占3个字节,所以,“是”的索引就是从3开始
6 104 //“h”占一个字节
7 97
8 104
9 97
当然,学了printf格式化输出之后,unicode码点我们就可以用%c处理:
for i,v := range "我是haha"{
fmt.Printf("%d,%c\n",i,v)
}
结果:0,我
3,是
6,h
7,a
8,h
9,a
4.6、strings包
Go语言为了简化字符串的复杂操作,在标准库中提供了一个名为strings的包,里面集成了很多功能,我们直接调用就好,不需要再自己编写。
下面我们来学习strings包中的几个常用的功能:
①、是否以…开头:
strings.HasPrefix(str, “…”),使用如下:
var str1 = "我很帅"
fmt.Println(strings.HasPrefix(str1, "我")) ------> true
②、是否以…结尾:
strings.HasSuffix(str, “…”),使用如下:
var str1 = "我很帅"
fmt.Println(strings.HasSuffix(str1, "很帅")) ------> true
③、是否包含…
strings.Contains(str, “…”),使用如下:
var str1 = "我真的很帅"
fmt.Println(strings.Contains(str1, "真的")) ------> true
特别的:
var str1 = "我真的很帅"
fmt.Println(strings.Contains(str1, "")) ------> true
④、是否包含…中任意字符
strings.ContainsAny(str, “…”),使用如下:
var str1 = "我真的很帅"
fmt.Println(strings.ContainsAny(str1, "真帅")) ------> true
特别的:
var str1 = "我真的很帅"
fmt.Println(strings.ContainsAny(str1, "")) ------> false
⑤、查找…第一次出现的索引
strings.Index(str, “…”)
若存在就返回指定字符串第一个字符的索引,若不存在,就返回-1,使用如下:
var str1 = "我真的真的很帅"
fmt.Println(strings.Index(str1, "真的")) -----> 3
var str1 = "我真的真的很帅"
fmt.Println(strings.Index(str1, "很丑")) -----> -1
⑥、查找…最后一次出现的索引
strings.LastIndex(str, “…”)
若存在就返回指定字符串第一个字符的索引,若不存在,就返回-1,使用如下:
var str1 = "我真的真的很帅"
fmt.Println(strings.LastIndex(str1, "真的")) -----> 9
⑦、字符串替换
strings.Replace(str, oldstr, newstr, n)
oldstr表示需要被替换的字符串,newstr表示替换内容,n表示匹配个数,n为-1表示匹配所有,使用如下:
var str1 = "我真的真的真的很帅"
fmt.Println(strings.Replace(str1, "真的", "非常", 2)) ---> 我非常非常真的很帅
var str1 = "我真的真的真的很帅"
fmt.Println(strings.Replace(str1, "真的", "非常", -1)) ---> 我非常非常非常很帅
⑧、频率统计
strings.Count(str, target)
target表示需要统计的字符串,返回总个数,使用如下:
var str1 = "我真的真的真的很帅"
fmt.Println(strings.Count(str1,"真的")) -----> 3
小技巧(统计字符数量):
var str1 = "我真的真的真的很帅"
var lenStr1 = strings.Count(str1,"") - 1
⑨、大小写转换
strings.ToLower(str),全部转成小写
strings.ToUpper(str),全部转成大写
var str = "老王是dSB"
fmt.Println(strings.ToLower(str)) ----> 老王是dsb
fmt.Println(strings.ToUpper(str)) ----> 老王是DSB
⑩、修剪
strings.Trim(str,target)
strings.TrimLeft(str,target)
strings.TrimRight(str,target)
target是被修剪的字符串,trim用来修剪首尾,TrimLeft用来修剪首部,TrimRight用来修剪尾部。
strings.TrimSpace(str),用来修剪首尾的空格换行
var str = "!!!golang!!!"
fmt.Println(strings.Trim(str,"!")) ---->golang
fmt.Println(strings.TrimLef(str,"!")) ---->golang!!!
fmt.Println(strings.TrimRight(str,"!")) ---->!!!golang
var str = "\n\tgolang\n\t"
fmt.Println(strings.TrimSpace(str)) ---->golang
⑪、分割
strings.Split(str, target)
target是用来分割字符串的字符串,结果是以target为分隔点得到的一个slice切片
var str = "a,b,c,d"
fmt.Println(strings.Split(str, ",")) --->[a b c d]
var str = "我很帅"
fmt.Println(strings.Split(str, "")) --->[我 很 帅]
⑫、插入
strings.Join(strslice, target)
strslice是一个切片类型的数据,如⑪中分割所得到的,target为需要插入的字符串,得到的结果是每一个slice切片中的元素拼上插入字符串得到的新字符串
var str = "a,b,c,d"
var strslice = strings.Split(str, ",") --->[a b c d]
fmt.Println(strings.Join(strslice, ",")) --->a,b,c,d
4.7、strconv包
这个包主要用于字符串与其它类型的转换,conv是convert的缩写,变换的意思
①、将bool值转成字符串
strconv.FormatBool(bool)
var strbool = strconv.FormatBool(true) --->类型:string,值:"true"
②、把字符串转成bool值
strconv.ParseBool(str),
str为"1",“t”,“T”,“TRUE”,“true”,“True”,时,返回值为bool类型的true
str为"0",“f”,“F”,“FALSE”,“false”,“False”,时,返回值为bool类型的false
str为其它值时,会转换错误,返回错误值。
因为转换可能出错,所以strconv.ParseBool(str)有两个返回值,一个接受转换值,一个接受错误
var istrue,err = strconv.ParseBool("1")
if err == nil { ---> nil表示空,即什么都没有的意思
fmt.Println(istrue) ---> err=nil,即没有错误,那就打印正确结果
}else{
fmt.Println(err) ---> 否则,打印错误信息
}
③、整型转成字符串
strconv.FormatInt(int64的整型,进制数)
这会把指定的int64的整型按照指定的进制数转成字符串
同理,还有strconv.FormatUint(uint64的整型,进制数)
var intstr1= strconv.FormatInt(0x123,8) --->16进制转8进制以字符串显示
var intstr1= strconv.FormatInt(123,10) --->10进制转10进制以字符串显示
④、字符串转整型
strconv.ParseInt(表示数字的字符串, 参数进制数, 参数大小)
表示数字的字符串:如16进制的“0x123”,8进制的“0123”,十进制“123”,不过,表示进制的“0x”“0”也不可以不写,由第二个参数指定
参数进制数:0,表示进制数由字符串决定,8,表示字符串是8进制,此时字符串中表示八进制的“0”不写
参数大小:这个值表示bit,用来描述字符串中数字的大小或者说范围,比如,int8的范围是-128127,那么当该参数设置为8的时候,字符串中的数字就不能超过-128127这个范围,不然就会报错。如果是0,那就是int。
得到的结果是两个值,一个是正确结果int64类型,一个是错误信息。
同理,还有strconv.ParseUint(表示数字的字符串, 参数进制数, 参数大小)
var v,err = strconv.ParseInt("0x123",0,0) ---> v:int64类型的291,err:nil
var v,err = strconv.ParseInt("123",16,0) ---> v:int64类型的291,err:nil
var v,err = strconv.ParseInt("123",0,0) ---> v:int64类型的123,err:nil
var v,err = strconv.ParseInt("128",0,8) ---> err:value out of range
⑤整型转10进制以字符串显示
strconv.Itoa(int类型整数),相当于strconv.FormatInt(int64的整型,10)的简写。
“itoa”里的i表示int,a表示algorism(十进制)
var a = strconv.Itoa(0x123) ---> "291"
var b = strconv.Itoa(123) ---> "123"
var c int8 = 123
var d = strconv.Itoa(c) ---> 报错
⑥、字符串表示的十进制转整型
strconv.Atoi(str),相当于strconv.ParseInt(str, 10, 0)
var v,err = strconv.Atoi("123") ---> v:123 err:nil
⑦、float64转字符串
strconv.FormatFloat(float64的小数, 显示格式, 保留位数, 精度)
显示格式:‘e’/‘E’:用科学计数法表示,如1.23e+2、1.23E+2
‘f’:正常显示,如3.14159265
’g‘/‘G’:由保留位数确定是用科学计数表示还是正常表示
保留位数:该参数设置为-1时,保留位数由第四个参数(32/64)的精度确定。
对于’e’/‘E’/‘f’,保留位数就是小数点后的保留位数,超过第四个参数(32/64)的精度限制之后就不准确了。
对于‘g’/‘G’,保留位数是整数和小数部分总和,但一定不能超过精度
精度:32或者64,相当于float32和float64,来控制显示精度
var a = strconv.FormatFloat(12.345678910,'f',5,32) ----> 12.34568
var b = strconv.FormatFloat(12.345678910,'g',1,32) ----> 1e+01
var c = strconv.FormatFloat(12.345678910,'g',4,32) ----> 12.35
//练习题:
//1 123.4567 显示为 科学计数1.2346e+2
fmt.Println(strconv.FormatFloat(123.4567,'e',4,64))
//2 123.4567 显示为 科学计数1.2346E+2
fmt.Println(strconv.FormatFloat(123.4567,'E',4,64))
//3 123.4567 显示为 科学计数1.2346700000e+2
fmt.Println(strconv.FormatFloat(123.4567,'e',10,64))
//4 123.4567 显示为 123.5
fmt.Println(strconv.FormatFloat(123.4567,'f',1,64))
//5 123.4567 显示为 123.4567000000
fmt.Println(strconv.FormatFloat(123.4567,'f',10,64))
//6 123.4567 动态显示 : 保留1位小数,显示为科学计数;保留5位小数为正常显示
fmt.Println(strconv.FormatFloat(123.4567,'g',2,64))
fmt.Println(strconv.FormatFloat(123.456784,'g',8,32))
fmt.Println(strconv.FormatFloat(123.456784,'e',5,32))
fmt.Println(strconv.FormatFloat(123.456784,'g',5,32))
⑧、字符串转float64
strconv.ParseFloat(小数字符串,类型)
类型:32/64 , 32表示按照float32的精度去处理字符串,64表示按照float64的精度去处理字符串。需要注意的是,它的结果是float64,按照float32的精度去处理后,会按照float64去显示,这会带来一些问题,我们都知道float32可以显示8位,精确到7位,但是在这里转换后,会按照float64去显示结果,这就造成第8位后出现一堆乱七八糟的数字,以至于我们无法用于判断。所以,正常情况,我们最好使用64
var v,err = strconv.ParseFloat("12345.67891234567891",64)
fmt.Println(v,err) ---> v:12345.678912345678 err:nil
4.8、字符:
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来。
// Go 语言的字符有以下两种:
1、uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。
2、rune类型,代表一个 UTF-8字符。
// 当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
// 遍历字符串
func traversalString() {
s := "hello沙河" //len(s)==11,一个汉字占3位
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
//for range 循环是按rune类型去遍历的
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
//输出
104(h) 101(e) 108(l) 108(l) 111(o) 230(æ) 178(²) 153() 230(æ) 178(²) 179(³)
104(h) 101(e) 108(l) 108(l) 111(o) 27801(沙) 27827(河)
//因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含
//中文的字符串,否则就会出现上面输出中前两行的结果。
4.9、修改字符串
//要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,
//都会重新分配内存,并复制字节数组。
func changeString() {
s1 := "big"
// 将字符串强制转换为字节数组
byteS1 := []byte(s1)
byteS1[0] = 'p'
// 将字节数组强制转回字符串类型
s1 = string(byteS1)
fmt.Println(s1)
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2))
}
五、类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换的基本语法如下:
T(表达式)
// T表示要转换的类型。表达式包括变量、复杂算子和函数返回值等.
比如计算直角三角形的斜边长时使用math包的Sqrt()函数,该函数接收的是float64类型的参数,而变量a和b都是int类型的,这个时候就需要将a和b强制类型转换为float64类型。
func sqrtDemo() {
var a, b = 3, 4
var c int
// math.Sqrt()接收的参数是float64类型,需要强制转换
c = int(math.Sqrt(float64(a*a + b*b)))
fmt.Println(c)
}
练习:
“hello” --> “olleh”
package main
import "fmt"
//字符串反转操作
func main(){
s1 := "hello" //go语言中字符串是不可变类型的变量
// 方法一
byteArray := []byte(s1) //[h e l l o]
s2 := ""
for i:=len(byteArray)-1;i>=0;i-- {
// i是 4 3 2 1 0
// byteArray[i]就是 o l l e h(字符)
s2 += string(byteArray[i]) //把字节数组转回字符串
}
fmt.Println(s2) // olleh
// 方法二
length := len(byteArray)
for i:=0;i<length/2;i++ {
byteArray[i], byteArray[length-1-i] = byteArray[length-1-i], byteArray[i] // 变量交叉赋值
}
fmt.Println(string(byteArray))
}
h.Sqrt(float64(aa + bb)))
fmt.Println©
}
#### 练习:
"hello" --> "olleh"
```go
package main
import "fmt"
//字符串反转操作
func main(){
s1 := "hello" //go语言中字符串是不可变类型的变量
// 方法一
byteArray := []byte(s1) //[h e l l o]
s2 := ""
for i:=len(byteArray)-1;i>=0;i-- {
// i是 4 3 2 1 0
// byteArray[i]就是 o l l e h(字符)
s2 += string(byteArray[i]) //把字节数组转回字符串
}
fmt.Println(s2) // olleh
// 方法二
length := len(byteArray)
for i:=0;i