联表查询JOIN介绍
大家好,因为最近项目里面涉及多张表,会使用到很多联表查询,所以今天给大家分享一下联表查询里面的JOIN的相关知识。
一、背景介绍
MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
关系型数据库三范式:
第一范式(1NF):字段值具有原子性,不能再分(所有关系型数据库系统都满足第一范式);
例如:姓名字段,其中姓和名是一个整体,如果区分姓和名那么必须设立两个独立字段;
第二范式(2NF):一个表必须有主键,即每行数据都能被唯一的区分;
备注:必须先满足第一范式;主键可以将表格变为一个聚集索引
第三范式(3NF):一个表中不能包涵其他相关表中非关键字段的信息,即数据表不能有沉余字段;
备注:必须先满足第二范式;往往我们在设计表中不能遵守第三范式,因为合理的沉余字段将会给我们减少join的查询;典型的以空间换时间思想
例如:相册表中会添加图片的点击数字段,在相册图片表中也会添加图片的点击数字段;
因为第三范式和关系型数据库的原因,所以,我们在查询一张表时往往不能得到所有我们需要的数据,这时候,就需要使用联查。
当然,你说我不想用联查,也没关系,可以分步单表查询,如果事先知道关系字段的值,可以直接两步就查询到结果,如果不知道的话,就需要先查出来,再用循环来查询第二张表,就会很麻烦
但是,Mysql可以直接帮我们联查两张表,只需要你知道两张表的共同字段是什么。
二、知识刨析
JOIN:select语句的条件之一,可以根据某些连接条件从其他表中获取数据。
JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。
当然你也可以连接三张表四张表,但是这将大大降低数据库性能,为什么这么说呢?
这是因为所有的连接在筛选之前都会先计算所有表的笛卡尔积
笛卡尔积,也叫交叉连接:CROSS JOIN
要理解各种JOIN首先要理解笛卡尔积。笛卡尔积就是将A表的每一条记录与B表的每一条记录强行拼在一起。所以,如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录。
下面的例子,book有10条记录,book_type有5条记录,所有他们俩的笛卡尔积有50条记录。
首先我们看一下这两张表的数据
第一张book表

第二张book_type表
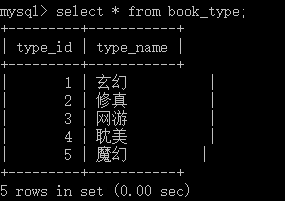
孔乙己曾说过:茴香豆的茴有四种写法,我们的笛卡尔积也有四种方法得到,分别是:
SELECT * FROM book CROSS JOIN book_type;
SELECT * FROM book INNER JOIN book_type;
SELECT * FROM book,book_type;
SELECT * FROM t_blog NATURE JOIN book_type;此时,四种语句都可以得到相同的结果,如下
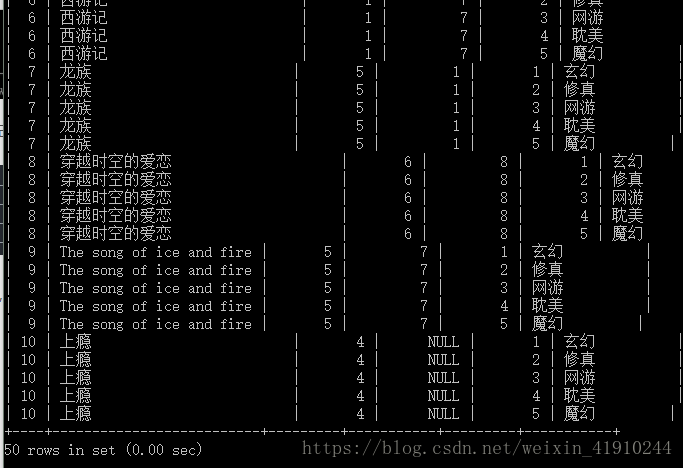
可以看到这四种方法都会产生同样的结果,如果此时我用数学上的一个圆表示一张表,圆相交的部分标识两张表重合数据的话,其结果就如下韦恩图所示
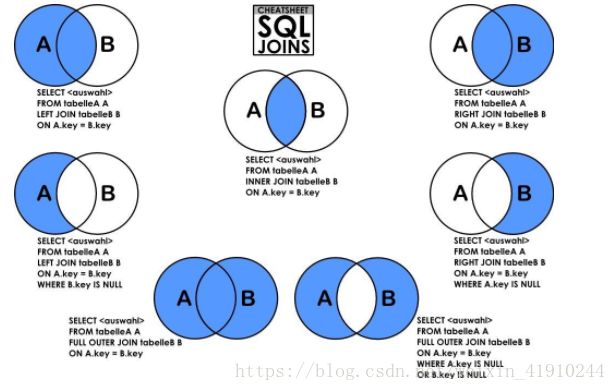
那么笛卡尔积cross join就是上图中的第?张图,其实都不是,上图中并没有corss join适合的图
但是事实上我们一般不会直接来求这个,因为当两张表数据量都很大的情况下,直接求这个数据量就非常惊人了。
接下来,就是我们最常用的内连接
内连接:INNER JOIN
内连接INNER JOIN是最常用的连接操作。从数学的角度讲就是求两个表的交集,从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录。有INNER JOIN,WHERE(等值连接),STRAIGHT_JOIN,JOIN(省略INNER)四种写法。
SELECT * FROM book INNER JOIN book_type ON book.type_id=book_type.type_id;
SELECT * FROM book,book_type WHERE book.type_id=book_type.type_id;
SELECT * FROM book STRAIGHT_JOIN book_type ON book.type_id=book_type.type_id; //注意STRIGHT_JOIN有个下划线
SELECT * FROM book JOIN book_type ON book.type_id=book_type.type_id;其得到结果如下
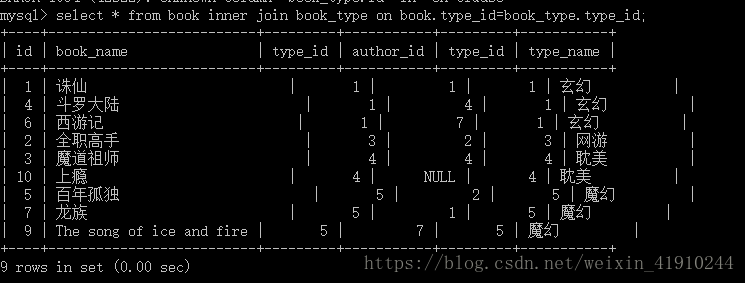
可以看到,其只筛选了9行数据,为什么呢?因为我的筛选条件是type_id相等,而book表中有一条数据的type_id是6,在book_type表中没有记录。其在韦恩图就是中间那幅。
左连接:LEFT JOIN
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据。依旧从笛卡尔积的角度讲,就是先从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录。
SELECT * FROM book LEFT JOIN book_type ON book.type_id=book_type.type_id;其结果如下

可以看到,相比之前的内连接,id=8的数据出来了,只不过后面的属性都是null,因为其找不到type_id相匹配的数据。左连接在韦恩图中就是第一幅
右连接:RIGHT JOIN
同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。再次从笛卡尔积的角度描述,右连接就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上右表中剩余的记录。
SELECT * FROM book RIGHT JOIN book_type ON book.type_id=book_type.type_id;其结果如下

可以看到,其也是产生10条数据,只不过和左连接不同的是其中有一条是左边数据为Null,其实在两表联查时可以用左连接的情况都可以使用右连接来代替,同理亦然,只不过将表的顺序换一下罢了。
外连接:OUTER JOIN
外连接就是求两个集合的并集。从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录,最后加上右表中剩余的记录。另外MySQL不支持OUTER JOIN,但是我们可以对左连接和右连接的结果做UNION操作来实现。
SELECT * FROM book LEFT JOIN book_type ON book.type_id=book_type.type_id
UNION
SELECT * FROM book RIGHT JOIN book_type ON book.type_id=book_type.type_id;结果如下
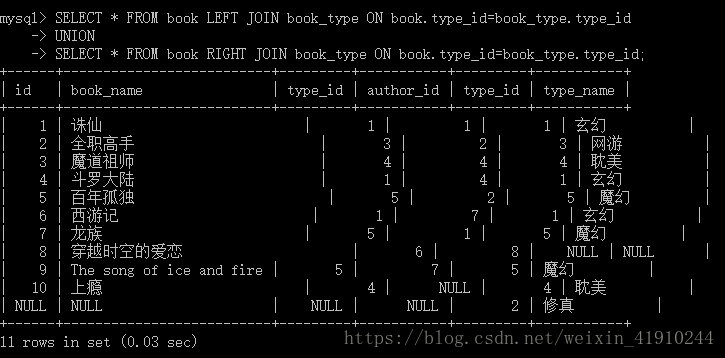
可以看到,这里产生了11条数据,因为公共部分是9条,左边剩余1,右边剩余1,那么全部加起来之后,就变成了11条数据,其相当于数学中的并集,区别于内连接的交集。
USING子句
MySQL中连接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name。当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。
所以,USING的功能相当于ON,区别在于USING指定一个属性名用于连接两个表,而ON指定一个条件。另外,SELECT *时,USING会去除USING指定的列,而ON不会。
select * from book inner join book_type using(type_id);结果如下

可以看到,和内连接是一样的结果,只不过排序上有点区别。
自然连接:NATURAL JOIN
自然连接就是USING子句的简化版,它找出两个表中相同的列作为连接条件进行连接。有左自然连接,右自然连接和普通自然连接之分。
select * from book natural join book_type;
select * from book natural left join book_type;
select * from book natural right join book_type;就不展示结果了,但是除非你也像我一样把其中的一个id列换名字或者都换名字,否则尽量不要用自然连接。
补充
从之前的图我们可以看到还有三种情况我们没有讲到,分别是4.5.7
要怎么做才能达到筛选出图4.5.7的效果呢?
图4是使用where子句来在左连接的基础上筛选where book_type.type_id is null;
SELECT * FROM book LEFT JOIN book_type ON book.type_id=book_type.type_id where book_type.type_id is null;图5同理,只是在右连接基础上换一下就好
select * from book right join book_type on book.type_id=book_type.type_id where book.id is null;图7的话,使用union拼接上面两句即可
三、常见问题
1.join联表查询和单表查询,效率上究竟有多大差距?
2.怎么优化呢?
3.我们应该怎么选择?
四、解决方案
其实在数据量比较小的情况下,而且联表的数据都有索引的情况下,联表查询肯定是更快的,因为分表查询还要考虑网络开销,多次调用数据库等情况。
但是在数据量特别大的情况下,而且索引优化也做的不好的话,还是单表会快一点。
所以,总的来说,还是要综合考虑各种情况。然后需要注意的是sql内联时的一个顺序
1、执行FROM语句
2、执行ON过滤
3、添加外部行
4、执行where条件过滤
5、执行group by分组语句
6、执行having
7、select列表
8、执行distinct去重复数据
9、执行order by字句
10、执行limit字句
因为内联之后数据量是几何倍的增加,所以如果可以,有些分语句可以在单表的时候执行。
我们以后的重点其实还是在优化性能上,毕竟联表查询肯定是要方便很多的。
最后的最后,重复一遍,
不要连接三张以上的表!!!
每张表1000条数据,产生的连接数据就是1000000000条!
五、更多讨论
1.为什么说不要用or?
如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,但是使用union的话即使一个没有也不会影响整体
2.对于多表联查是先分页再查询还是先查询再分页好?
要先分页再JOIN,否则逻辑读会很高,性能很差。
3.select count(*) from table为什么不能使用,不是只是统计数量吗?
这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的
六、参考文献
https://www.cnblogs.com/fudashi/p/7491039.html
https://blog.csdn.net/Tim_phper/article/details/78344444?locationNum=9&fps=1
今天的分享就到这了,大家有什么问题可以评论里留言,觉得不错也可以点个赞哦~
大家有什么自己独到的SQL优化经验也可以在评论里分享一下哦