Redis数据类型及数据结构
文章目录
- 1 Redis数据类型
- 1.1 五大基本数据类型
- 1.1.1 String类型
- 1.1.2 List类型
- 1.1.3 Set类型
- 1.1.4 Zset类型
- 1.1.5 Hash类型
- 1.2 三种特殊类型
- 1.2.1 geospatial 地理位置
- 1.2.2 Hyperloglog基数统计
- 1.2.3 bitmap位图
- 2 Redis数据结构
- 2.1 String数据结构
- 2.2 List数据结构
- 2.3 Set数据结构
- 2.3.1 intset
- 2.3.2 Hashtable
- 2.4 Zset
- 2.4.1 skiplist数据结构
1 Redis数据类型
Redis包含五大基本数据类型和三个特殊类型,下面介绍数据类型的基本使用。
1.1 五大基本数据类型
1.1.1 String类型
String类型可以存数字、存字符串、存序列化的对象等
存数字时,可以执行加减操作
27.0.0.1:2222> set value 10
OK
127.0.0.1:2222> get value
"10"
127.0.0.1:2222> decr value # 减一操作
(integer) 9
127.0.0.1:2222> incrby value 5 # 执行加5
(integer) 14
存字符串
127.0.0.1:6379[2]> APPEND key1 abcd #在字符串中追加字符串
(integer) 6
127.0.0.1:6379[2]> strlen key1 #获取字符串的长度
(integer) 6
127.0.0.1:6379[2]> GETRANGE key1 0 3 #截取范围字符串(双闭区间)
"v2ab"
127.0.0.1:6379[2]> mset k1 v1 k2 v2 k3 v3 #同时存入多个值
OK
存对象
存对象时,其实也是将对象序列化成字符串进行存储。
1.1.2 List类型
list集合类型,在redis中可以头插入/删除、尾插入/删除;可以尾插入尾删除实现栈,尾插入头删除实现队列,也可以单纯的存可重复的集合元素。
lpush/rpush/lpop/rpop #左右插入 左右删除
lindex list 1 #根据下标获取值
lrange list 0 1 lrange list 0 -1 #下标范围获取值
llen list #获取list的长度
lrem list 1 one #删除list中one,若有多个只移除一个
ltrim list 1 2 #通过下标截取list,list将会被改变
lset list 0 item #将list的0号元素更新为item
linsert list before one zone #将one的前面插入zone
1.1.3 Set类型
存储不重复的集合元素,比如在商品秒杀中存储某商品已经秒杀的用户ID,防止重复秒杀。
Redis中还可以返回两个集合的并集、交集等实现多元功能,比如两个用户的共同好友。
sadd myset hello # 添加值
smembers myset #查看所有值
sismember myset hello #是否有hello
scard myset #获取set集合中的元素个数
srem myset hello #删除元素
srandmember myset #随机的获取其中一个值
spop myset #随机的删除其中一个值
sdiff set1 set2 #返回两个集合的差集
sinter set1 set2 #返回两个集合的交集(共同好友)
1.1.4 Zset类型
在set的基础上增加一个score用于排序。比如在博客文章阅读排行榜中,可以返回阅读量从高到低的排行。
zadd myset 1 one #1为score,用于排序
zrangebyscore myset -inf +inf #按照score升序排列。-inf +inf代表负无穷和正无穷
zrangebyscore myset -inf 100 #按照score升序排列,并输出score在[-inf, 100]之间的value
zrange myset 0 -1 #默认升序输出全部
zrevrange myset 0 -1 #降序输出全部
ZREVRANGEBYSCORE zset1 10 -10 #按score降序排列,并输出score在[-10, 10] 之间的value
zrem salary zhangsan #删除zhangsan
zcard salary #获取salary有序集合中元素个数
zcount salary 100 1000 #获取指定区间的元素个数
1.1.5 Hash类型
存入键值对
hset myhash k1 v1 #向myhash添加键值对k1-v1
hmset myhash k2 v2 k3 v3 #向myhash添加键值对
hget myhash k1
hmget myhash k2 k3
127.0.0.1:6379[2]> hgetall myhash #获取所有的键值
1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
hkeys myhash #获取所有的key
hvals myhash #获取所有的value
hexists myhash k1 #判断字段是否存在
1.2 三种特殊类型
1.2.1 geospatial 地理位置
应用:朋友定位,附近的人,打车距离计算?
geoadd命令:添加地理位置
## 规则:两极无法添加,一般下载城市数据,直接java程序导入。
## 有效经度 -180~180 有效纬度 -85~85
## geoadd key value(经度 纬度 名称)
127.0.0.1:6379[2]> GEOADD china:city 116.40 39.90 beijing 121.44 31.21 shanghai
127.0.0.1:6379[2]> GEOADD china:city 104.07 30.67 chengdu 106.54 29.58 chongqing
127.0.0.1:6379[2]> GEOADD china:city 114.109 22.54 shenzhen 120.16 30.31 hangzhou
geopos命令:获取地理位置
127.0.0.1:6379[2]> geopos china:city chengdu
1) 1) "104.07000213861465454"
2) "30.67000055930392222"
geodist命令:返回两个位置之间的距离
单位: m km
127.0.0.1:6379[2]> geodist china:city chengdu beijing km 查看成都到北京的直线距离
"1516.1652"
georadius 以某个位置为中心,找出半径多少内的元素
附近的人功能实现?
127.0.0.1:6379[2]> GEORADIUS china:city 110 30 1000 km 距离110 30 直线距离小于1000km的城市
1) "chongqing"
2) "chengdu"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379[2]> GEORADIUS china:city 110 30 1000 km count 2 限制个数为2,只查询两个
1) "chongqing"
2) "chengdu"
georadiusByMember 通过名字来确定位置,找出半径多少内的元素
127.0.0.1:6379[2]> GEORADIUSbymember china:city chengdu 1000 km count 2
1) "chengdu"
2) "chongqing"
1.2.2 Hyperloglog基数统计
应用:统计网站访问的人数,不可重复计算。
传统方法:建立一个set保存用户id,访问一个用户就往set存入,最后返回set大小
Hyperloglog统计:将用户ID放入Hyperloglog即可
对比:放入Set的方法会占用较多内存,Hyperloglog利用位图减少内存开销,但是有一定误差
pfadd users a b c d e f g h i a c d a b #将userid放入
pfcount users #统计基数数量(排除重复元素)
1.2.3 bitmap位图
位图:按位存储,每位只能存储0或1,分别代表两种状态(多种状态也可以扩展多个位代表某个状态)
应用:统计用户一年每天登录状态
127.0.0.1:6379[2]> setbit sign 0 1 #设置第0位为1
127.0.0.1:6379[2]> setbit sign 1 1 #设置第1位为1....
127.0.0.1:6379[2]> GETBIT sign 0 #获取第0位
127.0.0.1:6379[2]> bitcount sign #获取为1的个数
127.0.0.1:6379[2]> bitcount sign 0 5 #获取在0-5之间为1的个数
2 Redis数据结构
2.1 String数据结构
String类型有三种储存方式:int、embstr、raw类型
int储存
当我们存入数字时,就会使用int编码储存,测试如下:
127.0.0.1:2222> set num 123456
OK
127.0.0.1:2222> OBJECT encoding num
"int"
那么如果数字范围大于Java的Integer范围呢?
127.0.0.1:2222> set num 2147483648 # 32位int最大范围是2147483647
OK
127.0.0.1:2222> OBJECT encoding num #输出还是int,猜测是使用64位存储
"int"
127.0.0.1:2222> set num 9223372036854775807
OK
127.0.0.1:2222> OBJECT encoding num
"int"
127.0.0.1:2222> set num 9223372036854775808
OK
127.0.0.1:2222> OBJECT encoding num # 大于64位int最大值后不再使用int储存。
"embstr"
# 本人使用的是64位机器,不知道32位机中C++中int是多少?
存入浮点数呢?
127.0.0.1:2222> set num 1.9
OK
127.0.0.1:2222> OBJECT encoding num
"embstr"
可见Redis中的数值类型只有一个64位int,没有浮点数。
embstr储存
在int测试中,大于64位的数值会用embstr存储。另外,在字符串或者浮点小于39字节的也会使用embstr存储。
raw储存
127.0.0.1:2222> set k aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:2222> OBJECT encoding k
"raw" # 当储存的字符串过长(大于39字节)就会使用raw类型
2.2 List数据结构
127.0.0.1:2222> LPUSH list 1 2 3 4 5
(integer) 5
127.0.0.1:2222> OBJECT encoding list
"quicklist"
quicklist简单理解(写着写着就把详解改成简单理解…)
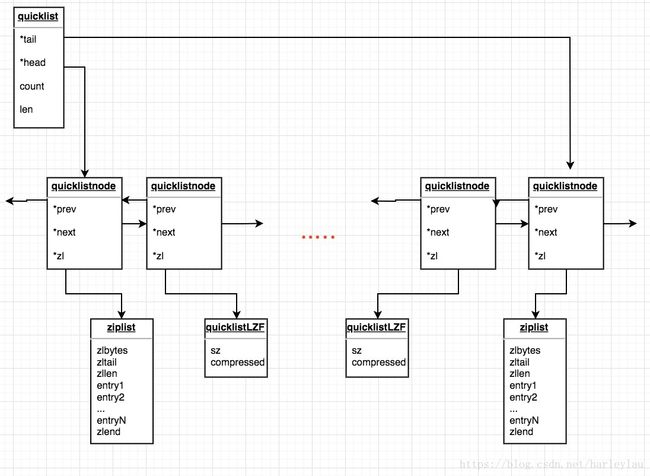
可以看到,List底层是使用一种叫quicklist的数据结构存储。在redis的安装目录的src下打开quicklist.h,看看quicklist的结构定义:
typedef struct quicklist {
quicklistNode *head; // 头结点指针。quicklistNode为结点的数据结构
quicklistNode *tail; // 尾结点
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
看到这只能理解头结点和尾结点。为什么会有count和len两个计数?注释的意思是count代表所有ziplist的entries数量,而len代表quicklistNodes的数量。
**问题一:**ziplist是什么结构,为什么存在?不是像普通双向链表一样在quicklistNodes里面存值么?
继续看quicklistNode的结构定义:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; // 这个是存的什么? zl=ziplist?
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
放眼整个quicklistNode结构,能够存储数据的好像只有zl这个指针了。看来绕不过ziplist了…于是查看ziplist.h,并没有结构定义,而是在ziplist.c中定义宏,redis没有提供一个结构体来保存压缩列表的信息,而是提供了一组宏来定位每个成员的地址。(以下内容来源:https://blog.csdn.net/men_wen/article/details/70176753)
/* Utility macros */
// ziplist的成员宏定义
// (*((uint32_t*)(zl))) 先对char *类型的zl进行强制类型转换成uint32_t *类型,
// 然后在用*运算符进行取内容运算,此时zl能访问的内存大小为4个字节。
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
//将zl定位到前4个字节的bytes成员,记录这整个压缩列表的内存字节数
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
//将zl定位到4字节到8字节的tail_offset成员,记录着压缩列表尾节点距离列表的起始地址的偏移字节量
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
//将zl定位到8字节到10字节的length成员,记录着压缩列表的节点数量
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//压缩列表表头(以上三个属性)的大小10个字节
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
//返回压缩列表首节点的地址
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
//返回压缩列表尾节点的地址
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
//返回end成员的地址,一个字节。
ziplist是由*一系列特殊编码的连续内存块组成的顺序存储结构*,类似于数组,ziplist在内存中是连续存储的,但是不同于数组,为了节省内存 ziplist的每个元素所占的内存大小可以不同,每个节点可以用来存储一个整数或者一个字符串。
空间中的结构组成如下图所示:

- zlbytes:占4个字节,记录整个压缩列表占用的内存字节数。
- zltail_offset:占4个字节,记录压缩列表尾节点entryN距离压缩列表的起始地址的字节数。
- zllength:占2个字节,记录了压缩列表的节点数量。
- entry[1-N]:长度不定,保存数据。
- zlend:占1个字节,保存一个常数255(0xFF),标记压缩列表的末端。
entry结点的定义如下:

- prev_entry_len:记录前驱节点的长度。
- encoding:记录当前节点的value成员的数据类型以及长度。
- value:根据encoding来保存字节数组或整数。
云里雾里的理解了一下ziplist(没办法,C++知识不过关),回到quicklist,quicklist的quicklistNode中存储的数据是一个ziplist,所以问题一解决。
最后放一张抄过来的图,很清晰的表达了quicklist的结构,原文博客:https://blog.csdn.net/harleylau/article/details/80534159
2.3 Set数据结构
127.0.0.1:2222> SADD set 1 2 3 4
(integer) 4
127.0.0.1:2222> OBJECT encoding set
"intset"
127.0.0.1:2222> SADD set aa bb cc dd
(integer) 4
127.0.0.1:2222> OBJECT encoding set
"hashtable"
Set有两种实现:intset和hashtable。显然intset用于存储int类型的set,如果有非intset则用hashtable。
2.3.1 intset
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
数据结构非常简单,用数组存储int集合。数组查找效率低,所以猜测肯定是有序数组,看一下添加元素的函数:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) { //搜索元素是否存在
if (success) *success = 0;
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1); //扩容,数组大小加一
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value); //赋值
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
显然,使用数组来存储,在添加或删除元素时效率低下,中间涉及到数组扩容和元素移动。
2.3.2 Hashtable
(待续)
2.4 Zset
127.0.0.1:2222> ZADD zs 10 aaaa 22 fbbb 9 ffccc 7 abh 6 odd
(integer) 5
127.0.0.1:2222> OBJECT encoding zs
"ziplist"
可见Zset可以使用ziplist储存。
在配置文件中,有下面两个配置,分别代表zset使用ziplist存储的时候,最大限制存储entries的个数和每个节点最大存储字节数,只有破坏一个条件就会转成skiplist。
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
修改zset-max-ziplist-entries为5,重启redis,测试一下
127.0.0.1:2222> OBJECT encoding zs
"skiplist" # 变成skiplist
2.4.1 skiplist数据结构
skiplist可以理解成多层有序链表。数据结构如图
图片来源:https://blog.csdn.net/qianshangding0708/article/details/104935313?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase)


跳表相对于红黑树的优势:
- 范围查找简单,红黑树需要找到最小值后中序遍历
- 插入和删除元素更简单,而红黑树可能有子树的调整
- 实现更加简单,更少的指针。
参考链接:https://blog.csdn.net/men_wen/article/details/70176753
https://blog.csdn.net/harleylau/article/details/80534159