爬虫实战——爬取研招网院校招生信息
当今社会竞争激烈,很多学子选择考研,研招网就为考研学子提供了详细的相关考研信息,学子们在上面苦苦寻找适合自己的院校,择校就成了考研的第一道门槛,为了让选学校变得更加方便,今天我们使用python来爬取2020年考研网站的信息。
- 目标网站:https://yz.chsi.com.cn/sch/search.do?ssdm=&yxls
- 所要爬取的信息:特定的省份,特定的学校以及相关专业的院系所和研究方向,以及招生人数和考试科目。
- 使用的库:
import requests
from lxml import etree
import re
import csv
先来看看效果:
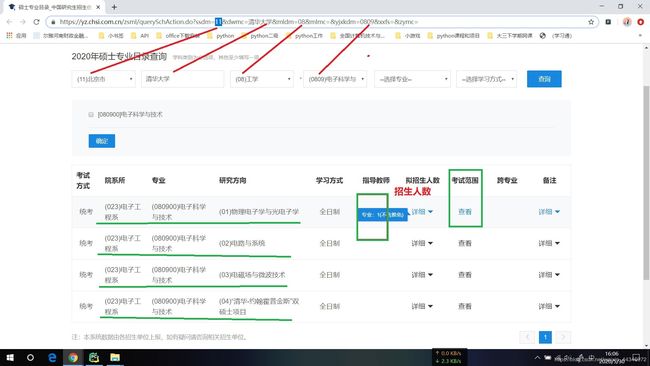
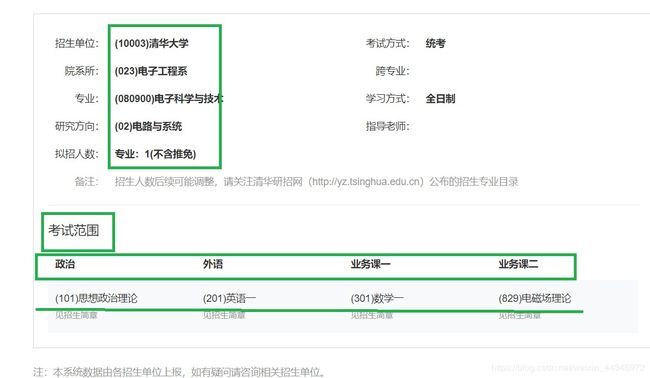
该代码是根据输入的省份、大学名字、学科门类和学科类别代码查询到的信息,上图查询了北京-北京大学-工学-(0812)计算机科学与技术的信息。信息包括:院系所、专业、研究方向、拟招人数以及考试范围。
废话不多说,开始写代码。
首先,我们要获取的是这样的信息:
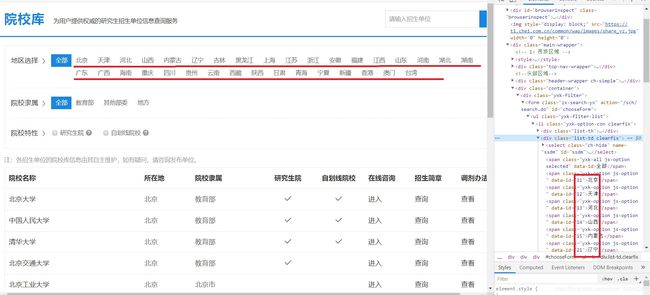
为了增强代码的通用性,我们查询的对象是全国,所以我们要获得全国所有省市的数字代码:
import requests
from lxml import etree
import re
import csv
class CollegeMessage():
def __init__(self):
self.headers = {
"Cookie":"JSESSIONID=C49D0535CFE3AFC95DAF3B7D7CB6439D; _ga=GA1.3.1713889609.1584199516; zg_did=%7B%22did%22%3A%20%22170d9a645f3110-0e03203b3d8ecf-366b420b-144000-170d9a645f411d%22%7D; acw_tc=2760829b15887435857595959ea5e12bae49d0a2e598ac9f4ea989a290ca11; aliyungf_tc=AQAAAKcJ0izdxQwA1kIIe4JabC1ii9gb; JSESSIONID=0C671E30554484285B9A3EFAB45D4C35; XSRF-CCKTOKEN=14c33c0930217319fb4cd08eb808755f; CHSICC_CLIENTFLAGYZ=80d9cc1d6fb6280a4041b60d0103f6e1; _gid=GA1.3.1370633235.1590377571; CHSICC_CLIENTFLAGZSML=fdc0c72e078135f955e18f6745458ca4; CHSICC_CLIENTFLAGSSWBGG=0b261e848dcc9512888b49d02619818f; zg_adfb574f9c54457db21741353c3b0aa7=%7B%22sid%22%3A%201590377617181%2C%22updated%22%3A%201590377641432%2C%22info%22%3A%201590377617186%2C%22superProperty%22%3A%20%22%7B%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22yz.chsi.com.cn%22%2C%22landHref%22%3A%20%22https%3A%2F%2Fyz.chsi.com.cn%2F%22%7D",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
def get_all_collage(self):
url = "https://yz.chsi.com.cn/sch/?start=0" # 目标网站
response = requests.get(url,headers=self.headers) # 为请求添加头部信息
res = response.content.decode() #获取网页信息
html_str = etree.HTML(res) # 用lxml方式来解析字符串格式的HTML文档对象
all_span = html_str.xpath("//div[@class='container']/div[@class='yxk-filter']/form/ul/li/div[@class='list-td clearfix']/span") # 提取省份信息
all_span = all_span[1:-4] # 去掉不需要的信息
dict_collage={} # 定义空字典
for span in all_span:
collage_name = span.xpath("text()")[0] # 省份名字
collage_code = span.xpath("@data-id")[0] # 省份数字代码
dict_collage[collage_name] = collage_code # 将名字和代码装入字典中
# print(collage_name,"代码="+collage_code,sep=" ")
for collage_i in dict_collage.keys():
print(collage_i,end=" ")
print("\n")
input_collage_name = input("请输入要查询大学所在的省份:")
input_collage_value = dict_collage[input_collage_name]
# print(input_collage_value)
return input_collage_value # 返回对应的数字代码
这样一来我们就拿到了所有相关省份的数字代码,接下来我们要输出特定省份的所有考研招生大学,以供我们选择。
下图是要获取的所有大学名字:

该过程代码如下:
def display_collage(self,collage_value_url,i_page_url): # 执行每一页的数据获取
url = "https://yz.chsi.com.cn/sch/search.do?ssdm={}&start={}".format(collage_value_url,i_page_url)
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
tr_collages = html_str.xpath("//div[@class='yxk-table']/table/tbody/tr")
for i_tr in tr_collages: # 输出该省市所有的大学名字
collage_name = i_tr.xpath("td[1]/a/text()")[0].strip()
print(collage_name) # 输出一个大学名字
def province_collage(self,collage_value): # 翻页获取所有的大学名字
url = "https://yz.chsi.com.cn/sch/search.do?ssdm={}&yxls=".format(collage_value) # 接收该省市数字代码为地址
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
collages_name = html_str.xpath("//div[@class='yxk-table']/div/div/form/ul/li/a") # 通过xpath语法锁定数据位置
number_max_collage = 0
for collage_i in collages_name:
# print(collage_i.xpath("text()"))
if collage_i.xpath("text()"): # 如果一个列表不为空的话(考虑到可能会有空的数据)
collage_i_number = int(collage_i.xpath("text()")[0])
if collage_i_number > number_max_collage:
number_max_collage = collage_i_number
# print(number_max_collage) # 找到最大的翻页
for i_page in range(number_max_collage):
i_page_url = str(i_page*20) # 每页的start值相差20
self.display_collage(collage_value,i_page_url)
以上仅仅是提示用户输入信息,具体数据的获取在下方:
def peoples_exam_data(self,end_url): # 获取该专业的拟招人数和考试范围信息
url = "https://yz.chsi.com.cn"+end_url
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
peoples = html_str.xpath("//table[@class='zsml-condition']/tbody/tr[5]/td[2]/text()") # 提起拟招人数信息
people = re.findall('\d+',peoples[0])[0]
exam_subjects = html_str.xpath("//div[@class='zsml-result']/table/tbody/tr/td") # 提取考试范围信息
examSubject = ""
count_i =1
for one_exam in exam_subjects:
if count_i % 5 ==0: # 假如出现多项选择的话:
examSubject = examSubject + "或者:"
else:
examSubject = examSubject + one_exam.xpath("text()")[0].strip() + ","
count_i += 1
examSubject = examSubject[:-1] # 去掉最后一个逗号
# print(people,examSubject)
return people,examSubject
def get_xuekeleibie_number(self,number):
if number == 0:
return "zyxw"
elif number < 10:
return "0"+str(number)
else:
return str(number)
def get_url(self,csv_name,province_value,universe_url,menlei_url,xuekelb_url):
url = "https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={}&dwmc={}&mldm={}&yjxkdm={}&xxfs=&zymc="
# https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm=22&dwmc=长春大学&mldm=02&yjxkdm=0202&xxfs=&zymc=
response = requests.get(url.format(province_value,universe_url,menlei_url,xuekelb_url))
res = response.content.decode()
# print(res)
html_str = etree.HTML(res)
tr_message = html_str.xpath("//table[@class='ch-table']/tbody/tr")
if tr_message:# 当该校设有此专业信息时
page_message = []
# print("hello world")
for one_tr in tr_message:
YuanXiSuo = one_tr[1].xpath("text()")[0] # 获取院系所信息
ZhuanYe = one_tr[2].xpath("text()")[0] # 获取专业信息
YanJiuFangXiang = one_tr[3].xpath("text()")[0] # 获取研究方向信息
# print(YuanXiSuo,ZhuanYe,YanJiuFangXiang)
number_strs = one_tr[7].xpath("a/@href")[0] # 获取具体信息链接
# print(number_strs)
people,exam_subject = self.peoples_exam_data(number_strs) # 返回两个字符串
one_message = {
"YuanXiSuo":YuanXiSuo, # Department
"ZhuanYe":ZhuanYe, # SpecialField
"YanJiuFangXiang":YanJiuFangXiang, # ResearchFields
"number_of_people":people,
"exam_subject":exam_subject
}
page_message.append(one_message)
for one_i in page_message:
print(one_i)
"""
将字典数据写入csv表格中
(1)头部信息header要和字典中的key值相对应
(2)文件名字采用csv_name
(3)以追加“a”的方式写入
(4)newline是数据之间不加空行
(5)encoding='utf-8'表示编码格式为utf-8,如果不希望在excel中打开csv文件出现中文乱码的话,将其去掉不写也行。
"""
header=['YuanXiSuo','ZhuanYe','YanJiuFangXiang','number_of_people','exam_subject']
with open('{}.csv'.format(csv_name),'a',newline='',encoding='utf-8') as f:
writer = csv.DictWriter(f,fieldnames=header)# 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writeheader()# 写入列名
writer.writerows(page_message)# 写入数据
else:
print("----无信息----")
def get_collage_message(self,province_value): # 接收一个省份的数字代码
# 学科门类信息
XueKML = {
"专业学位":0,"哲学":1,"经济学":2,"法学":3,"教育学":4,"文学":5,"历史学":6,"理学":7,"工学":8,"农学":9,"医学":10,"军事学":11,"管理学":12,"艺术学":13
}
# 专业类别信息
ZhuanYLY = [
["(0251)金融","(0252)应用统计","(0253)税务","(0254)国际商务","(0255)保险","(0256)资产评估","(0257)审计","(0351)法律","(0352)社会工作","(0353)警务","(0451)教育","(0452)体育","(0453)汉语国际教育","(0454)应用心理","(0551)翻译","(0552)新闻与传播","(0553)出版","(0651)文物与博物馆","(0851)建筑学","(0853)城市规划","(0854)电子信息","(0855)机械","(0856)材料与化工","(0857)资源与环境","(0858)能源动力","(0859)土木水利","(0860)生物与医药","(0861)交通运输","(0951)农业","(0952)兽医","(0953)风景园林","(0954)林业","(1051)临床医学","(1052)口腔医学","(1053)公共卫生","(1054)护理","(1055)药学","(1056)中药学","(1057)中医","(1151)军事","(1251)工商管理","(1252)公共管理","(1253)会计","(1254)旅游管理","(1255)图书情报","(1256)工程管理","(1351)艺术"],
["(0101)哲学"],
["(0201)理论经济学","(0202)应用经济学","(0270)统计学"],
["(0301)法学","(0302)政治学","(0303)社会学","(0304)民族学","(0305)马克思主义理论","(0306)公安学"],
["(0401)教育学","(0402)心理学","(0403)体育学","(0471)"],
["(0501)中国语言文学","(0502)外国语言文学","(0503)新闻传播学"],
["(0601)考古学","(0602)中国史","(0603)世界史"],
["(0701)数学","(0702)物理学","(0703)化学","(0704)天文学","(0705)地理学","(0706)大气科学","(0707)海洋科学","(0708)地球物理学","(0709)地质学","(0710)生物学","(0711)系统科学","(0712)科学技术史","(0713)生态学","(0714)统计学","(0771)心理学","(0772)力学","(0773)材料科学与工程","(0774)电子科学与技术","(0775)计算机科学与技术","(0776)环境科学与工程","(0777)生物医学工程","(0778)基础医学","(0779)公共卫生与预防医学","(0780)药学","(0781)中药学","(0782)医学技术","(0783)护理学","(0784)","(0785)","(0786)"],
["(0801)力学","(0802)机械工程","(0803)光学工程","(0804)仪器科学与技术","(0805)材料科学与工程","(0806)冶金工程","(0807)动力工程及工程热物理","(0808)电气工程","(0809)电子科学与技术","(0810)信息与通信工程","(0811)控制科学与工程","(0812)计算机科学与技术","(0813)建筑学","(0814)土木工程","(0815)水利工程","(0816)测绘科学与技术","(0817)化学工程与技术","(0818)地质资源与地质工程","(0819)矿业工程","(0820)石油与天然气工程","(0821)纺织科学与工程","(0822)轻工技术与工程","(0823)交通运输工程","(0824)船舶与海洋工程","(0825)航空宇航科学与技术","(0826)兵器科学与技术","(0827)核科学与技术","(0828)农业工程","(0829)林业工程","(0830)环境科学与工程","(0831)生物医学工程","(0832)食品科学与工程","(0833)城乡规划学","(0834)风景园林学","(0835)软件工程","(0836)生物工程","(0837)安全科学与工程","(0838)公安技术","(0839)网络空间安全","(0870)科学技术史","(0871)管理科学与工程","(0872)设计学"],
["(0901)作物学","(0902)园艺学","(0903)农业资源与环境","(0904)植物保护","(0905)畜牧学","(0906)兽医学","(0907)林学","(0908)水产","(0909)草学","(0970)科学技术史","(0971)环境科学与工程","(0972)食品科学与工程","(0973)风景园林学"],
["(1001)基础医学","(1002)临床医学","(1003)口腔医学","(1004)公共卫生与预防医学","(1005)中医学","(1006)中西医结合","(1007)药学","(1008)中药学","(1009)特种医学","(1010)医学技术","(1011)护理学","(1071)科学技术史","(1072)生物医学工程","(1073)","(1074)"],
["(1101)军事思想及军事历史","(1102)战略学","(1103)战役学","(1104)战术学","(1105)军队指挥学","(1106)军事管理学","(1107)军队政治工作学","(1108)军事后勤学","(1109)军事装备学","(1110)军事训练学"],
["(1201)管理科学与工程","(1202)工商管理","(1203)农林经济管理","(1204)公共管理","(1205)图书情报与档案管理"],
["(1301)艺术学理论","(1302)音乐与舞蹈学","(1303)戏剧与影视学","(1304)美术学","(1305)设计学"]
]
print("\n")
university_url = input("请输入要查询的大学:")
for i_key in XueKML.keys():
print(i_key,end=",")
print("\n")
xue_key = input("请根据以上信息输入学科门类:")
menlei_url = self.get_xuekeleibie_number(XueKML[xue_key])
for i_zhuanyly in ZhuanYLY[XueKML[xue_key]]:
print(i_zhuanyly)
xuekelb_url = input("请根据以上信息输入相应学科类别左边的代码:")
csv_name = university_url+"_"+xue_key+"_"+xuekelb_url
# 传参:csv_name是生成数据表格需要的名字,province_value是省市数字代码,university_url是大学名字,menlei_url是学科门类的数字地址代码,xuekelb_url是学科类别的数字地址代码
self.get_url(csv_name,province_value,university_url,menlei_url,xuekelb_url)
根据提示的信息正确输入,就可以得到我们想要的数据了
结果截图:
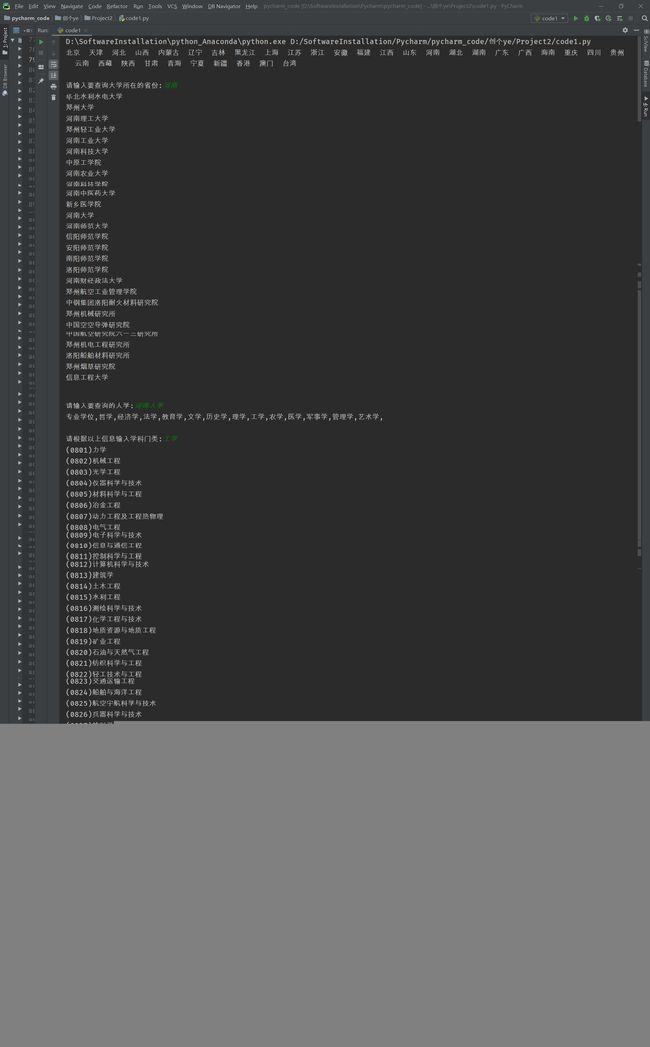
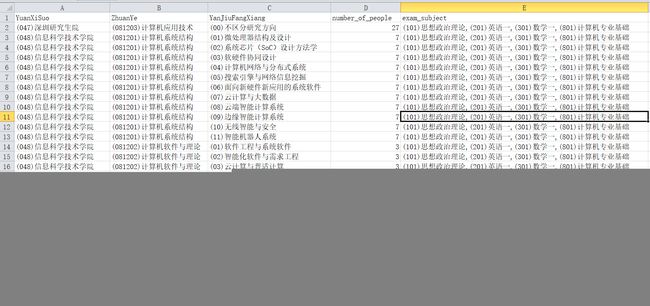
文件数据截图:

爬取任务就大功告成了!!!
附源码:
import requests
from lxml import etree
import re
import csv
class CollegeMessage():
def __init__(self):
self.headers = {
"Cookie":"JSESSIONID=C49D0535CFE3AFC95DAF3B7D7CB6439D; _ga=GA1.3.1713889609.1584199516; zg_did=%7B%22did%22%3A%20%22170d9a645f3110-0e03203b3d8ecf-366b420b-144000-170d9a645f411d%22%7D; acw_tc=2760829b15887435857595959ea5e12bae49d0a2e598ac9f4ea989a290ca11; aliyungf_tc=AQAAAKcJ0izdxQwA1kIIe4JabC1ii9gb; JSESSIONID=0C671E30554484285B9A3EFAB45D4C35; XSRF-CCKTOKEN=14c33c0930217319fb4cd08eb808755f; CHSICC_CLIENTFLAGYZ=80d9cc1d6fb6280a4041b60d0103f6e1; _gid=GA1.3.1370633235.1590377571; CHSICC_CLIENTFLAGZSML=fdc0c72e078135f955e18f6745458ca4; CHSICC_CLIENTFLAGSSWBGG=0b261e848dcc9512888b49d02619818f; zg_adfb574f9c54457db21741353c3b0aa7=%7B%22sid%22%3A%201590377617181%2C%22updated%22%3A%201590377641432%2C%22info%22%3A%201590377617186%2C%22superProperty%22%3A%20%22%7B%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22yz.chsi.com.cn%22%2C%22landHref%22%3A%20%22https%3A%2F%2Fyz.chsi.com.cn%2F%22%7D",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
def peoples_exam_data(self,end_url): # 获取该专业的拟招人数和考试范围信息
url = "https://yz.chsi.com.cn"+end_url
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
peoples = html_str.xpath("//table[@class='zsml-condition']/tbody/tr[5]/td[2]/text()") # 提起拟招人数信息
people = re.findall('\d+',peoples[0])[0]
exam_subjects = html_str.xpath("//div[@class='zsml-result']/table/tbody/tr/td") # 提取考试范围信息
examSubject = ""
count_i =1
for one_exam in exam_subjects:
if count_i % 5 ==0: # 假如出现多项选择的话:
examSubject = examSubject + "或者:"
else:
examSubject = examSubject + one_exam.xpath("text()")[0].strip() + ","
count_i += 1
examSubject = examSubject[:-1] # 去掉最后一个逗号
# print(people,examSubject)
return people,examSubject
def get_xuekeleibie_number(self,number):
if number == 0:
return "zyxw"
elif number < 10:
return "0"+str(number)
else:
return str(number)
def get_url(self,csv_name,province_value,universe_url,menlei_url,xuekelb_url):
url = "https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm={}&dwmc={}&mldm={}&yjxkdm={}&xxfs=&zymc="
# https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm=22&dwmc=长春大学&mldm=02&yjxkdm=0202&xxfs=&zymc=
response = requests.get(url.format(province_value,universe_url,menlei_url,xuekelb_url))
res = response.content.decode()
# print(res)
html_str = etree.HTML(res)
tr_message = html_str.xpath("//table[@class='ch-table']/tbody/tr")
if tr_message:
page_message = []
# print("hello world")
for one_tr in tr_message:
YuanXiSuo = one_tr[1].xpath("text()")[0] # 获取院系所信息
ZhuanYe = one_tr[2].xpath("text()")[0] # 获取专业信息
YanJiuFangXiang = one_tr[3].xpath("text()")[0] # 获取研究方向信息
# print(YuanXiSuo,ZhuanYe,YanJiuFangXiang)
number_strs = one_tr[7].xpath("a/@href")[0] # 获取具体信息链接
# print(number_strs)
people,exam_subject = self.peoples_exam_data(number_strs) # 返回两个字符串
one_message = {
"YuanXiSuo":YuanXiSuo, # Department
"ZhuanYe":ZhuanYe, # SpecialField
"YanJiuFangXiang":YanJiuFangXiang, # ResearchFields
"number_of_people":people,
"exam_subject":exam_subject
}
page_message.append(one_message)
for one_i in page_message:
print(one_i)
"""
将字典数据写入csv表格中
(1)头部信息header要和字典中的key值相对应
(2)文件名字采用csv_name
(3)以追加“a”的方式写入
(4)newline是数据之间不加空行
(5)encoding='utf-8'表示编码格式为utf-8,如果不希望在excel中打开csv文件出现中文乱码的话,将其去掉不写也行。
"""
header=['YuanXiSuo','ZhuanYe','YanJiuFangXiang','number_of_people','exam_subject']
with open('{}.csv'.format(csv_name),'a',newline='',encoding='utf-8') as f:
writer = csv.DictWriter(f,fieldnames=header)# 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writeheader()# 写入列名
writer.writerows(page_message)# 写入数据
else:
print("----无信息----")
def get_collage_message(self,province_value): # 接收一个省份的数字代码
XueKML = {
"专业学位":0,"哲学":1,"经济学":2,"法学":3,"教育学":4,"文学":5,"历史学":6,"理学":7,"工学":8,"农学":9,"医学":10,"军事学":11,"管理学":12,"艺术学":13
}
ZhuanYLY = [
["(0251)金融","(0252)应用统计","(0253)税务","(0254)国际商务","(0255)保险","(0256)资产评估","(0257)审计","(0351)法律","(0352)社会工作","(0353)警务","(0451)教育","(0452)体育","(0453)汉语国际教育","(0454)应用心理","(0551)翻译","(0552)新闻与传播","(0553)出版","(0651)文物与博物馆","(0851)建筑学","(0853)城市规划","(0854)电子信息","(0855)机械","(0856)材料与化工","(0857)资源与环境","(0858)能源动力","(0859)土木水利","(0860)生物与医药","(0861)交通运输","(0951)农业","(0952)兽医","(0953)风景园林","(0954)林业","(1051)临床医学","(1052)口腔医学","(1053)公共卫生","(1054)护理","(1055)药学","(1056)中药学","(1057)中医","(1151)军事","(1251)工商管理","(1252)公共管理","(1253)会计","(1254)旅游管理","(1255)图书情报","(1256)工程管理","(1351)艺术"],
["(0101)哲学"],
["(0201)理论经济学","(0202)应用经济学","(0270)统计学"],
["(0301)法学","(0302)政治学","(0303)社会学","(0304)民族学","(0305)马克思主义理论","(0306)公安学"],
["(0401)教育学","(0402)心理学","(0403)体育学","(0471)"],
["(0501)中国语言文学","(0502)外国语言文学","(0503)新闻传播学"],
["(0601)考古学","(0602)中国史","(0603)世界史"],
["(0701)数学","(0702)物理学","(0703)化学","(0704)天文学","(0705)地理学","(0706)大气科学","(0707)海洋科学","(0708)地球物理学","(0709)地质学","(0710)生物学","(0711)系统科学","(0712)科学技术史","(0713)生态学","(0714)统计学","(0771)心理学","(0772)力学","(0773)材料科学与工程","(0774)电子科学与技术","(0775)计算机科学与技术","(0776)环境科学与工程","(0777)生物医学工程","(0778)基础医学","(0779)公共卫生与预防医学","(0780)药学","(0781)中药学","(0782)医学技术","(0783)护理学","(0784)","(0785)","(0786)"],
["(0801)力学","(0802)机械工程","(0803)光学工程","(0804)仪器科学与技术","(0805)材料科学与工程","(0806)冶金工程","(0807)动力工程及工程热物理","(0808)电气工程","(0809)电子科学与技术","(0810)信息与通信工程","(0811)控制科学与工程","(0812)计算机科学与技术","(0813)建筑学","(0814)土木工程","(0815)水利工程","(0816)测绘科学与技术","(0817)化学工程与技术","(0818)地质资源与地质工程","(0819)矿业工程","(0820)石油与天然气工程","(0821)纺织科学与工程","(0822)轻工技术与工程","(0823)交通运输工程","(0824)船舶与海洋工程","(0825)航空宇航科学与技术","(0826)兵器科学与技术","(0827)核科学与技术","(0828)农业工程","(0829)林业工程","(0830)环境科学与工程","(0831)生物医学工程","(0832)食品科学与工程","(0833)城乡规划学","(0834)风景园林学","(0835)软件工程","(0836)生物工程","(0837)安全科学与工程","(0838)公安技术","(0839)网络空间安全","(0870)科学技术史","(0871)管理科学与工程","(0872)设计学"],
["(0901)作物学","(0902)园艺学","(0903)农业资源与环境","(0904)植物保护","(0905)畜牧学","(0906)兽医学","(0907)林学","(0908)水产","(0909)草学","(0970)科学技术史","(0971)环境科学与工程","(0972)食品科学与工程","(0973)风景园林学"],
["(1001)基础医学","(1002)临床医学","(1003)口腔医学","(1004)公共卫生与预防医学","(1005)中医学","(1006)中西医结合","(1007)药学","(1008)中药学","(1009)特种医学","(1010)医学技术","(1011)护理学","(1071)科学技术史","(1072)生物医学工程","(1073)","(1074)"],
["(1101)军事思想及军事历史","(1102)战略学","(1103)战役学","(1104)战术学","(1105)军队指挥学","(1106)军事管理学","(1107)军队政治工作学","(1108)军事后勤学","(1109)军事装备学","(1110)军事训练学"],
["(1201)管理科学与工程","(1202)工商管理","(1203)农林经济管理","(1204)公共管理","(1205)图书情报与档案管理"],
["(1301)艺术学理论","(1302)音乐与舞蹈学","(1303)戏剧与影视学","(1304)美术学","(1305)设计学"]
]
print("\n")
university_url = input("请输入要查询的大学:")
for i_key in XueKML.keys():
print(i_key,end=",")
print("\n")
xue_key = input("请根据以上信息输入学科门类:")
menlei_url = self.get_xuekeleibie_number(XueKML[xue_key])
for i_zhuanyly in ZhuanYLY[XueKML[xue_key]]:
print(i_zhuanyly)
xuekelb_url = input("请根据以上信息输入相应学科类别左边的代码:")
csv_name = university_url+"_"+xue_key+"_"+xuekelb_url
self.get_url(csv_name,province_value,university_url,menlei_url,xuekelb_url)
def get_all_collage(self):
url = "https://yz.chsi.com.cn/sch/?start=0" # 目标网站
response = requests.get(url,headers=self.headers) # 为请求添加头部信息
res = response.content.decode() #获取网页信息
html_str = etree.HTML(res) # 用lxml方式来解析字符串格式的HTML文档对象
all_span = html_str.xpath("//div[@class='container']/div[@class='yxk-filter']/form/ul/li/div[@class='list-td clearfix']/span")
all_span = all_span[1:-4] # 去掉不需要的信息
dict_collage={}# 定义空字典
for span in all_span:
collage_name = span.xpath("text()")[0] # 省份名字
collage_code = span.xpath("@data-id")[0] # 省份数字代码
dict_collage[collage_name] = collage_code # 将名字和代码装入字典中
# print(collage_name,"代码="+collage_code,sep=" ")
for collage_i in dict_collage.keys():
print(collage_i,end=" ")
print("\n")
input_collage_name = input("请输入要查询大学所在的省份:")
input_collage_value = dict_collage[input_collage_name]
# print(input_collage_value)
return input_collage_value # 返回对应的数字代码
def display_collage(self,collage_value_url,i_page_url):# 执行每一页的数据获取
url = "https://yz.chsi.com.cn/sch/search.do?ssdm={}&start={}".format(collage_value_url,i_page_url)
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
tr_collages = html_str.xpath("//div[@class='yxk-table']/table/tbody/tr")
for i_tr in tr_collages: # 输出该省市所有的大学名字
collage_name = i_tr.xpath("td[1]/a/text()")[0].strip()
print(collage_name) # 输出一个大学名字
def province_collage(self,collage_value): # 翻页获取所有的大学名字
url = "https://yz.chsi.com.cn/sch/search.do?ssdm={}&yxls=".format(collage_value) # 接收该省市数字代码为地址
response = requests.get(url,headers=self.headers)
res = response.content.decode()
html_str = etree.HTML(res)
collages_name = html_str.xpath("//div[@class='yxk-table']/div/div/form/ul/li/a") # 通过xpath语法锁定数据位置
number_max_collage = 0
for collage_i in collages_name:
# print(collage_i.xpath("text()"))
if collage_i.xpath("text()"): # 如果一个列表不为空的话(考虑到可能会有空的数据)
collage_i_number = int(collage_i.xpath("text()")[0])
if collage_i_number > number_max_collage:
number_max_collage = collage_i_number
# print(number_max_collage) # 找到最大的翻页
for i_page in range(number_max_collage):
i_page_url = str(i_page*20) # 每页的start值相差20
self.display_collage(collage_value,i_page_url)
def run(self):
province_value = self.get_all_collage() # 获取省份代码
self.province_collage(province_value) # 显示此省份所有招研究生的学校
self.get_collage_message(province_value)
if __name__ == '__main__':
cm = CollegeMessage()
cm.run()
关注微信公众号:Code启示录,还有更多精彩内容!
趁年轻,多敲点代码。多动手,多实践,我们共同加油!!!
