Memcache内存分配原理介绍
1 Memcached简介
1.1 什么是Memcached
Memcached是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
Memcached是免费并且开源的。
1.2 Memcached主页
http://memcached.org/
1.3 Memcached版本
最新版本为V1.4.15
2013-09-03 发布
1.4 Memcached License
BSD license
1.5 Memcached用户
LiveJournal
Wikipedia
Flickr
Bebo
Typepad
Yellowbot
Youtube
Digg
WordPress.com
Craigslist
Mixi
2 memcached的特征
memcached作为高速运行的分布式缓存服务器,具有以下的特点。
- 协议简单
- 基于libevent的事件处理
- 内置内存存储方式
- memcached不互相通信的分布式
2.1 协议简单
memcached的服务器客户端通信并不使用复杂的XML等格式, 而使用简单的基于文本行的协议。因此,通过telnet 也能在memcached上保存数据、取得数据。下面是例子。
$ telnet localhost 11211
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
set foo 0 0 3 (保存命令)
bar (数据)
STORED (结果)
get foo (取得命令)
VALUE foo 0 3 (数据)
bar (数据)
2.2 基于libevent的事件处理
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能 封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。 memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。 关于事件处理这里就不再详细介绍,可以参考Dan Kegel的The C10K Problem。
2.3 内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。 由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。 另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。 memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。 关于内存存储的详细信息,本连载的第二讲以后前坂会进行介绍,请届时参考。
2.4 memcached不互相通信的分布式
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。 各个memcached不会互相通信以共享信息。那么,怎样进行分布式呢? 这完全取决于客户端的实现。本连载也将介绍memcached的分布式。
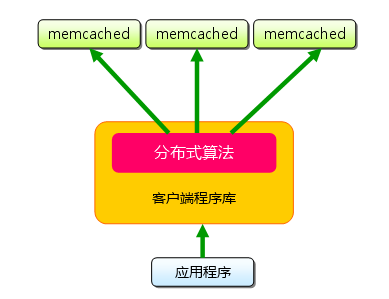
3 Memcached内存分配
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。 在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。 但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下, 会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
3.1 Slab Allocation的术语
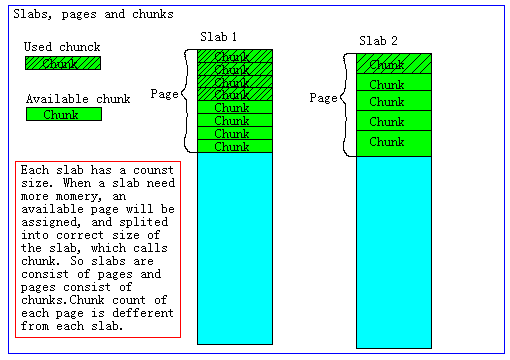
Page
分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Ø Chunk
用于缓存记录的内存空间。
Ø Slab (Slab Class)
特定大小的chunk的组。
3.2 Slab Allocation机制
Slab Allocation的原理相当简单。 将分配的内存(page)分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(Slab,即chunk的集合)
Memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。
这里有几个特点要注意,
1). Memcached分配出去的page不会被回收或者重新分配
2). Memcached申请的内存不会被释放
3). slab空闲的chunk不会借给任何其他slab使用
3.2.1 Page为内存分配的最小单位
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配(page ressign已经从1.2.8版移除了)
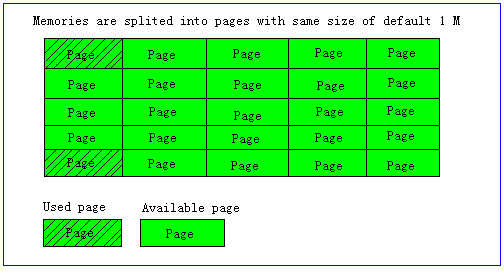
3.2.2 Slabs划分数据空间
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。如下图,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:slab 3只存储大小介于137 到 224 bytes的数据。如果一个数据大小为230byte将被分配到slab 4中。从下图可以看出,每个slab负责的空间其实是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长比例。

Slab Class 示意图:
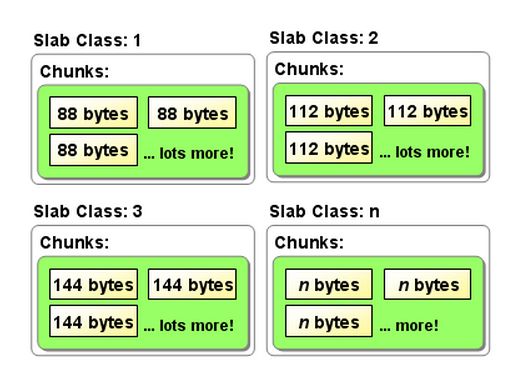
3.2.3 Chunk 才是存储数据的单位
Chunk是一系列固定的内存空间,这个大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached实际存放缓存数据的地方,因为chunk的大小固定为slab能够存放的最大值,所以所有分配给当前slab的数据都可以被chunk存下。如果时间的数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。
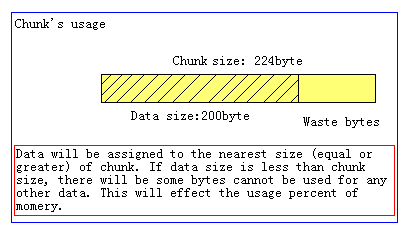
3.2.4 Page Slab Chunk 三者的关系
3.3 Slab中缓存记录的原理
下面说明memcached如何针对客户端发送的数据选择slab并缓存到chunk中。
memcached根据收到的数据的大小,选择最适合数据大小的slab(图2)。 memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。

3.4 Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。

对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。
3.5 使用Growth Factor进行调优
memcached在启动时指定 Growth Factor因子(通过-f选项),就可以在某种程度上控制slab之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
让我们用以前的设置,以verbose模式启动memcached试试看:
$ memcached -f 2 -vv
下面是启动后的verbose输出:
slab class 1: chunk size 128 perslab 8192 slab class 2: chunk size 256 perslab 4096 slab class 3: chunk size 512 perslab 2048 slab class 4: chunk size 1024 perslab 1024 slab class 5: chunk size 2048 perslab 512 slab class 6: chunk size 4096 perslab 256 slab class 7: chunk size 8192 perslab 128 slab class 8: chunk size 16384 perslab 64 slab class 9: chunk size 32768 perslab 32 slab class 10: chunk size 65536 perslab 16 slab class 11: chunk size 131072 perslab 8 slab class 12: chunk size 262144 perslab 4 slab class 13: chunk size 524288 perslab 2
可见,从128字节的组开始,组的大小依次增大为原来的2倍。这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,两年前追加了growth factor这个选项。
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10组):
slab class 1: chunk size 88 perslab 11915 slab class 2: chunk size 112 perslab 9362 slab class 3: chunk size 144 perslab 7281 slab class 4: chunk size 184 perslab 5698 slab class 5: chunk size 232 perslab 4519 slab class 6: chunk size 296 perslab 3542 slab class 7: chunk size 376 perslab 2788 slab class 8: chunk size 472 perslab 2221 slab class 9: chunk size 592 perslab 1771 slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。
将memcached引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
接下来介绍一下如何使用memcached的stats命令查看slabs的利用率等各种各样的信息。
3.6 查看memcached的内部状态
memcached有个名为stats的命令,使用它可以获得各种各样的信息。执行命令的方法很多,用telnet最为简单:
$ telnet 主机名 端口号
连接到memcached之后,输入stats再按回车,即可获得包括资源利用率在内的各种信息。 此外,输入"stats slabs"或"stats items"还可以获得关于缓存记录的信息。 结束程序请输入quit。
这些命令的详细信息可以参考memcached软件包内的protocol.txt文档。

各项参数的解释:
pid memcache服务器的进程ID
uptime 服务器已经运行的秒数
time 服务器当前的unix时间戳
version memcache版本
pointer_size 当前OS的指针大小(32位系统一般是32bit)
rusage_user 进程的累计用户时间
rusage_system 进程的累计系统时间
curr_items 服务器当前存储的items数量
total_items 从服务器启动以后存储的items总数量
bytes 当前服务器存储items占用的字节数
curr_connections 当前打开着的连接数
total_connections 从服务器启动以后曾经打开过的连接数
connection_structures 服务器分配的连接构造数
cmd_get get命令(获取)总请求次数
cmd_set set命令(保存)总请求次数
get_hits 总命中次数
get_misses 总未命中次数
evictions 为获取空闲内存而删除的items数(分配给memcache的空间用满后需要删除旧的items来得到空间分配给新的items)
bytes_read 总读取字节数(请求字节数)
bytes_written 总发送字节数(结果字节数)
limit_maxbytes 分配给memcache的内存大小(字节)
threads 当前线程数
3.7 查看slabs的使用状况
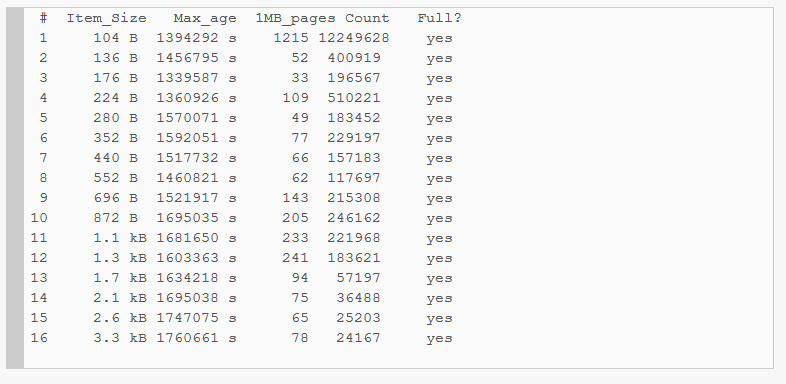
| 列 | 含义 |
| # | slab class编号 |
| Item_Size | Chunk大小 |
| Max_age | LRU内最旧的记录的生存时间 |
| 1MB_pages | 分配给Slab的页数 |
| Count | Slab内的记录数 |
| Full? | Slab内是否含有空闲chunk |
4 Memcached内存复用
4.1 数据不会真正从memcached中消失
memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible,透明),其存储空间即可重复使用。
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。 顾名思义,这是删除“最近最少使用”的记录的机制。 因此,当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。 从缓存的实用角度来看,该模型十分理想。
但如果在监控Memcached发现,evictions 不为0的时候,说明LRU已经开始显现作用了,已经有部分item被重写掉了。如果大量信息被重写掉了,需要看一下是否设置的memcached的内存太小!
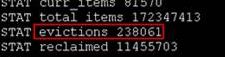
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“-M”参数可以禁止LRU,如下所示:
$ memcached -M -m 1024
启动时必须注意的是,小写的“-m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值64MB。
指定“-M”参数启动后,内存用尽时memcached会返回错误。但memcached毕竟不是存储器,而是缓存,所以推荐使用LRU。