SQL 的简单教程(Mac 下 PostgreSQL 的安装与使用)(1)
〇、PostgerSql 的安装以及基本命令
1. 安装 PostgreSQL:
brew install postgresql -v # 非管理员身份运行
2. 初始配置 PostgreSQL:
initdb /usr/local/var/postgres -E utf8
3. 设置开机启动 PostgreSQL:
ln -sfv /usr/local/opt/postgresql/*.plist ~/Library/LaunchAgents
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.postgresql.plist
4. 启动 PostgreSQL:
pg_ctl -D /usr/local/var/postgres -l /usr/local/var/postgres/server.log start
5. 关闭 PostgreSQL:
pg_ctl -D /usr/local/var/postgres stop -s -m fast
6. 创建一个 PostgerSql 用户:
createuser username -P # username 为你想创建的用户名
7. 连接数据库
psql -U username -d dbname -h 127.0.0.1 # username 为连接数据库名为 dbname 的 用户名
8. 显示已创建的数据库
\l

9. 在不连接 PostgerSql 数据库的情况下,也可以在终端上查看显示已创建的数据库:
psql -l
10. 切换数据库
\c dbname
11. 显示数据库表
\d
12. 在终端删除数据库
dropdb -U user dbname
13. 对于版本的数据升级问题,PostgreSQL 提供了 pg_upgrade 来做版本后的数据迁移,用法如下:
pg_upgrade -b 旧版本的bin目录 -B 新版本的bin目录 -d 旧版本的数据目录 -D 新版本的数据目录 [其他选项...]
14. 利用 pg_ctl 关闭 postmaster
pg_ctl -D /usr/local/var/postgres stop
15. Mac 下这样关闭:
launchctl unload ~/Library/LaunchAgents/homebrew.mxcl.postgresql.plist
16. 备份数据(默认是在 /usr/local/var/postgres 目录):
mv /usr/local/var/postgres /usr/local/var/postgres.old
17. 退出数据库
\q

一、数据库与 SQL
1.1 数据库是什么
DBMS 与 DB 的关系:
DB:
将大量数据保存起来,通过计算机加工而成的可以进行高效进行访问的数据集合成为数据库(Database ,DB)
DBMS:
用来管理数据库的计算机系统成为数据库管理系统(Database Management System,DBMS).
DBMS 的种类
1. 层次数据库(HDB)
将数据通过层次结构(树形结构)的方式表现出来,曾经的主流,现在使用的很少.
2. 关系数据库(RDB)
5 种代表:
Oracle Database:甲骨文
SQL Server:微软公司
DB2: IBM
PostgerSql:开源
Mysql:甲骨文--开源
3. 面向对象数据库(OODB)
保存对象的数据库
4. XML 数据库
对 XML 形式的大量数据可以进行高速的处理
5. 键值存储系统(KVS)
redis mongodb 等
1.2 数据的结构
RDBMS 数据库常见的系统结构
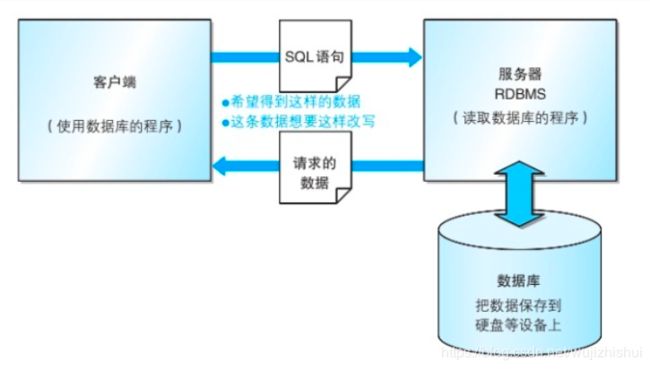
通过网络可以实现多个客户端访问同一个数据库

表的结构

1.3 SQL 概要
1.3.1 SQL 语句及其种类
SQL 根据操作目的可以分为 DDL,DML和 DCL

1.3.2 SQL 基本书写规范
已分号(;)结尾
不区分大小写
字符串和日期常熟需要使用单引号( ' )括起来,而数字常数可以直接书写
单词需要用半角空格或者换行来分割
1.4 表的创建
数据库的创建
CREATE DATABASE <数据库名称>
表的创建
CREATE TABLE <表名>
<列名> <数据类型> <该列所需约束>
...
<该表的约束1> <该表的约束2> ...
CREATE TABLE product
(
"product_id" int4 NOT NULL,
"product_name" varchar(100) COLLATE "pg_catalog"."default" NOT NULL DEFAULT ''::character varying,
"product_type" varchar(32) COLLATE "pg_catalog"."default" NOT NULL DEFAULT ''::character varying,
"sale_price" numeric(10,2) NOT NULL DEFAULT 0,
"purchase_price" numeric(10,2) DEFAULT NULL::numeric,
"regist_date" date,
PRIMARY KEY ("product_id")
);
ALTER TABLE "public"."product" OWNER TO "psql";
COMMENT ON COLUMN "public"."product"."product_id" IS '商品 id';
COMMENT ON COLUMN "public"."product"."product_name" IS '商品名称';
COMMENT ON COLUMN "public"."product"."product_type" IS '商品种类';
COMMENT ON COLUMN "public"."product"."sale_price" IS '商品销售价格';
COMMENT ON COLUMN "public"."product"."purchase_price" IS '进货价';
COMMENT ON COLUMN "public"."product"."regist_date" IS '登记日期';
命名规则
标准 SQL: 只能使用 半角英文字母, 数字, 下划线(_) 作为数据库,表和列的名称
1.5 表的删除
表的删除
DROP TABLE <表名>;
表定义的更新
新增字段:
ALTER TABLE <表名> ADD COLUM <列的定义>;
DB2 PostgreSQL MySQL
ALTER TABLE Product ADD COLUMN product_name_pinyin VARCHAR(100);
Oracle
ALTER TABLE Product ADD (product_name_pinyin VARCHAR2(100));
SQL Server
ALTER TABLE Product ADD product_name_pinyin VARCHAR(100);
删除字段:
ALTER TABLE <表名> DROP COLUM <列名>;
SQL Server DB2 PostgreSQL MySQL
ALTER TABLE Product DROP COLUMN product_name_pinyin;
Oracle
ALTER TABLE Product DROP (product_name_pinyin);
插入数据
SQL Server PostgreSQL
-- DML:插入数据
BEGIN TRANSACTION;
INSERT INTO Product VALUES ('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');
INSERT INTO Product VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Product VALUES ('0003', '运动T恤','衣服',4000, 2800, '');
INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具',3000, 2800, '2009-09-20');
INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具',6800, 5000, '2009-01-15');
INSERT INTO Product VALUES ('0006', '叉子', '厨房用具',500, 0, '2009-09-20');
INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具',880, 790, '2008-04-28');
INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品',100, 0,'2009-11-11');
COMMIT;
变更表名
Oracle PostgreSQL
ALTER TABLE Poduct RENAME TO Product;
DB2
RENAME TABLE Poduct TO Product;
SQL Server
sp_rename 'Poduct', 'Product';
MySQL
RENAME TABLE Poduct to Product;
二、查询基础
2-1 SELECT 语句基础
列的查询
SELECT <列名>,...... FROM <表名>;
查询出表中所有的列
SELECT * FROM <表名>;
为列设定别名
SELECT
product_id AS id,
product_name AS name,
purchase_price AS price
FROM Product;
# 别名可以使用中文,使用中文时需要用双引号(")括起来 A。请注意 不是单引号(')
SELECT
product_id AS '商品编号',
product_name AS "商品名称",
purchase_price AS "进货单价"
FROM Product;
常数的查询
SELECT
'商品' AS string,
38 AS number,
'2009-02-24' AS date,
product_id,
product_name
FROM Product;
从结果中删除重复行
SELECT
DISTINCT product_type as type
FROM Product;
# 在多列之前使用 DISTINCT(此时,会 将多个列的数据进行组合,将重复的数据合并为一条)
SELECT
DISTINCT product_type, regist_date
FROM Product;
# DISTINCT 关键字只能用在第一个列名之前。因此,请大家注意不 能写成 regist_date, DISTINCT product_type。
根据 WHERE 语句来选择记录
SELECT <列名>, ......
FROM <表名>
WHERE <条件表达式>;
SELECT product_name, product_type
FROM Product
WHERE product_type = '衣服';
注释的书写方法

2-2 算术运算符和比较运算符
算术运算符
SELECT
product_name, sale_price, sale_price * 2 AS "sale_price_x2"
FROM Product;
需要注意 NULL
5+NULL
10 - NULL
1*NULL
4 / NULL
NULL/9
NULL/0
以上结果都为NULL
比较运算符
SELECT
product_name, product_type
FROM Product
WHERE
sale_price = 500;
# SQL 表示不等于的方法: != <>
SELECT
product_name, product_type
FROM Product
WHERE
sale_price <> 500;
# WHERE 子句的条件表达式中也可以使用计算表达式
SELECT
product_name, sale_price, purchase_price
FROM Product
WHERE
sale_price - purchase_price >= 500;
对字符串使用不等号时的注意事项
创建 Chars 表并插入数据
-- DDL:创建表
CREATE TABLE Chars (chr CHAR(3) NOT NULL, PRIMARY KEY (chr));
插入数据
-- DML:插入数据
BEGIN TRANSACTION;
INSERT INTO Chars VALUES ('1');
INSERT INTO Chars VALUES ('2');
INSERT INTO Chars VALUES ('3');
INSERT INTO Chars VALUES ('10');
INSERT INTO Chars VALUES ('11');
INSERT INTO Chars VALUES ('222');
COMMIT;
选取出大于 ‘2’ 的数据的SELECT语 句
SELECT chr
FROM Chars
WHERE chr > '2';


不能对 NULL 使用比较运算符
# 选取 NULL 的记录
SELECT
product_name, purchase_price
FROM Product
WHERE purchase_price IS NULL;
# 选取不为 NULL 的记录
SELECT
product_name, purchase_price
FROM Product
WHERE purchase_price IS NOT NULL;
2-3 逻辑运算符
NOT 运算符
SELECT
product_name, product_type, sale_price
FROM Product
WHERE NOT sale_price >= 1000;
AND 运算符和 OR 运算符
# 使用 AND
SELECT product_name, purchase_price
FROM Product
WHERE
product_type = '厨房用具'
AND
sale_price >= 3000;
# 使用 OR
SELECT product_name, purchase_price
FROM Product
WHERE
product_type = '厨房用具'
OR
sale_price >= 3000;
使用括号强化处理
不使用括号强化
SELECT product_name, product_type, regist_date
FROM Product
WHERE
product_type = '办公用品'
AND
egist_date = '2009-09-11'
OR
regist_date = '2009-09-20';

使用括号强化
SELECT product_name, product_type, regist_date
FROM Product
WHERE
product_type = '办公用品'
AND
( regist_date = '2009-09-11'
OR
regist_date = '2009-09-20');

逻辑运算符和真值

含有 NULL 时的真值

建表时设置 NOT NULL 约束的原因

三、聚合与排序
3-1 对表进行聚合查询
聚合函数(聚集函数)
COUNT:计算表中的记录数(行数)
SUM : 计算表中数值列中数据的合计值
AVG : 计算表中数值列中数据的平均值
MAX: 求出表中任意列中数据的最大值
MIN : 求出表中任意列中数据的最小值
计算表中数据的行数
count(*)/count(1)
计算 NULL 之外的数据的行数
SELECT COUNT(purchase_price) FROM Product;
# purchase_price列中有两行数据是 NULL, 因此并不应该计算这两行。
对于 COUNT 函数来说,参数列不同计算的结果也会发生变化
极端情况

# 包含NULL的列作为参数时,COUNT(*)和COUNT(<列名>)的 结果并不相同
SELECT COUNT(*), COUNT(col_1) FROM NullTbl;

如上所示,即使对同一个表使用 COUNT 函数,输入的参数不同得到 的结果也会不同。由于将列名作为参数时会得到 NULL 之外的数据行数, 所以得到的结果是 0 行。
该 特 性 是 C O U N T 函 数 所 特 有 的 ,其 他 函 数 并 不 能 将 星 号 作 为 参 数( 如 果使用星号会出错)。

计算合计值
# 计算销售单价的合计值
SELECT SUM(sale_price) FROM product;
# 计算销售单价和进货单价的合计值
SELECT SUM(sale_price), SUM(purchase_price) FROM product;

注意: purchase_price 中有两列是 NULL ,
但是之前我们知道 NULL+任何数都是 NULL,
这里与之并不矛盾,因为在计算SUM 时并没有将 NULL 查找出来,
所以这里计算的结果并不为 NULL
计算平均值
# 计算销售单价的平均值
SELECT AVG(sale_price) FROM product;
# 计算销售单价和进货单价的平均值
SELECT AVG(sale_price), AVG(purchase_price) FROM Product;
计算最大值和最小值
# 计算销售单价的最大值和进货单价的最小值
SELECT MAX(sale_price), MIN(purchase_price) FROM Product;
MAX/MIN 函数和 SUM/AVG 函数有一点不同,那就是 SUM/ AVG 函数只能对数值类型的列使用,而 MAX/MIN 函数原则上可以适用 于任何数据类型的列。
# 计算登记日期的最大值和最小值
SELECT MAX(regist_date), MIN(regist_date) FROM Product;

使用聚合函数删除重复值(关键字 DISTINCT)
# 计算去除重复数据后的数据行数
SELECT COUNT(DISTINCT product_type) FROM Product;
# 使不使用 DISTINCT 时的动作差异(SUM 函数)
SELECT SUM(sale_price), SUM(DISTINCT sale_price) FROM Product;
3-2 对表进行分组
GROUP BY子句
格式
SELECT
<列名1>, <列名2>, <列名3>, ......
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ......;
# 按照商品种类统计数据行数
SELECT
product_type, COUNT(*)
FROM Product
GROUP BY product_type;
GROUP BY 的分割标准

聚合键中包含 NULL 的情况
# 按照进货单价统计数据行数
SELECT
purchase_price, COUNT(*)
FROM
Product
GROUP BY
purchase_price;

从结果我们可以看出,当聚合键中包含 NULL 时,也会将 NULL 作为一组特定的数据
使用WHERE子句时GROUP BY的执行结果
SELECT
<列名1>, <列名2>, <列名3>, ......
FROM
<表名>
WHERE
<where 条件>
GROUP BY
<列名1>, <列名2>, <列名3>, ......;
SELECT
purchase_price, COUNT(*)
FROM Product
WHERE
product_type = '衣服'
GROUP BY
purchase_price;
与聚合函数和GROUP BY子句有关的常见错误
-- 在 SELECT 子句中书写聚合键之外的列名会发生错误
SELECT
product_name, purchase_price, COUNT(*)
FROM
Product
GROUP BY
purchase_price;
-- 在GROUP BY子句中写了列的别名
-- 该错误并不适用 MySQL 以及 PostgerSql,但是对于其他 DBMS并不通用,不推荐使用.
SELECT
product_type AS pt, COUNT(*)
FROM
Product
GROUP BY
pt;

3-3 为聚合结果指定条件
HAVING 子句
SELECT
<列名1>, <列名2>, <列名3>, ......
FROM
<表名>
GROUP BY
<列名1>, <列名2>, <列名3>, ......
HAVING
<分组结果对应的条件>
-- 按照商品种类进行分组后的结果中,取出“包含的数据行数为 2 行”的组
SELECT
product_type, COUNT(*)
FROM
Product
GROUP BY
product_type
HAVING
COUNT(*) = 2;
-- 销售单价的平均值大于等于 2500 日元
SELECT
product_type, AVG(sale_price)
FROM
Product
GROUP BY
product_type
having
AVG(sale_price) >350
HAVING 子句的构成要素
常数
聚合函数
GROUP BY子句中指定的列名(即聚合键)
不能使用别名
相对于 HAVING 子句,更适合写在 WHERE 子句中的条件
有些条件既可以写在 HAVING 子句当中, 又可以写在 WHERE 子句当中。
这些条件就是聚合键所对应的条件。
聚合键所对应的条件还是应该书写在 WHERE 子句之中

3-4 对查询结果进行排序
ORDER BY子句
SELECT
<列名1>, <列名2>, <列名3>, ......
FROM
<表名>
ORDER BY
<排序基准列1>, <排序基准列2>, ......
指定升序或降序
DESC 降序
ASC 升序
指定多个排序键
SELECT
product_id, product_name, sale_price, purchase_price
FROM
Product
ORDER BY
sale_price, product_id;
NULL 的顺序
-- 使用含有 NULL 的列作为排序键时, NULL 会在结果的开头或末尾汇总显示
SELECT
product_id, product_name, sale_price, purchase_price
FROM
Product
ORDER BY
purchase_price;

在排序键中使用显示用的别名
SELECT
product_id AS id, product_name, sale_price AS sp, purchase _price
FROM
Product
ORDER BY
sp, id;
使用 HAVING 子句时 SELECT 语句的顺序
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
ORDER BY子句中可以使用的列

不要使用列编号
-- ORDER BY子句中可以使用列的编号
-- 通过列名指定
SELECT
product_id, product_name, sale_price, purchase_price
FROM
Product
ORDER BY
sale_price DESC, product_id;
-- 通过列编号指定
SELECT
product_id, product_name, sale_price, purchase_price
FROM
Product
ORDER BY
3 DESC, 1;
不推荐使用,原因有二
- 不利于代码的阅读
- 该语法将来会被移除
SQL 的简单教程(Mac 下 PostgreSQL 的安装与使用)(2)