利用python爬取百度翻译内容
利用python可以实现对百度翻译内容的爬取,具体过程如下:
前期工作
本程序的测试环境为python3.5,Chrome浏览器。进入百度翻译的页面,点开F12进入开发者调试工具,点击network,并清空所有的请求,方便判断点击“翻译”按钮后,会有哪些请求,上述过程如下图所示:
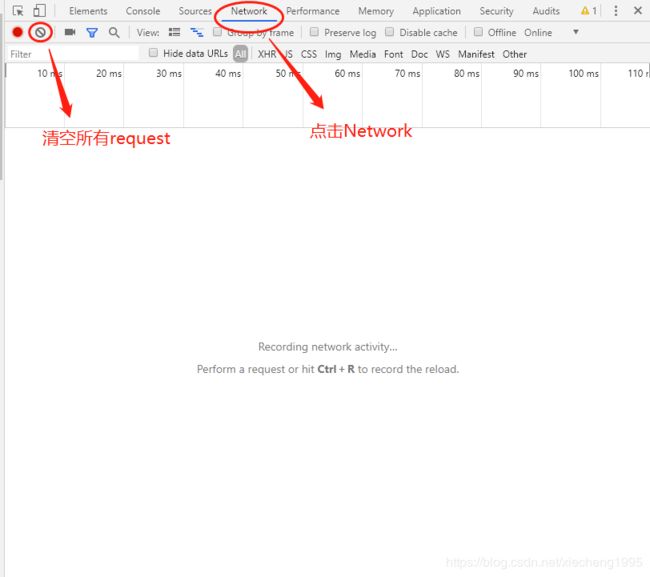
在百度翻译中输入想要翻译的内容,并点击翻译,在network的请求框中可以看到如下一堆的请求:

从上到下依次点击,在Response中,如果发现翻译结果,说明这个就是执行翻译请求的URL。本人对应的request是第四个,即v2transapi,对应的Response为:
![]()
因为本人执行的是英译汉,即最后输出的是中文,所以在上述翻译结果中,中文被转码为Unicode编码格式,不影响后续爬取结果,后台转码就可以了,后续会有相应介绍。
对应的Headers(请求头,部分)为:
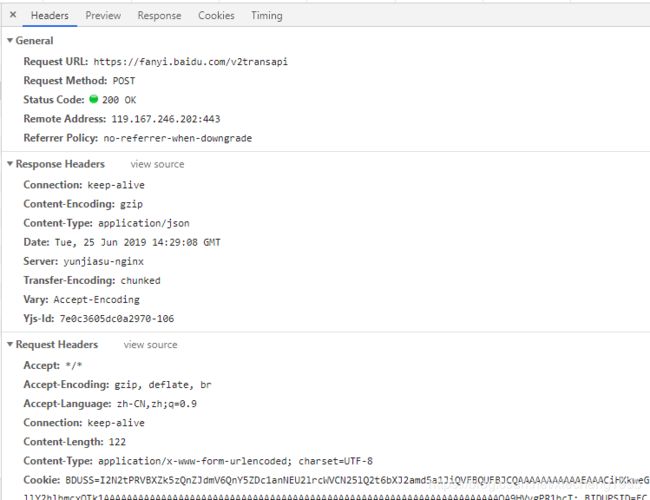
对于上述请求头中的内容,对我们来说比较重要的有如下几个部分:
-
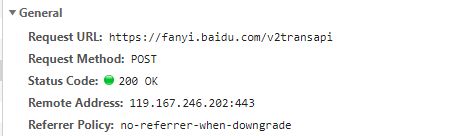
General:
-
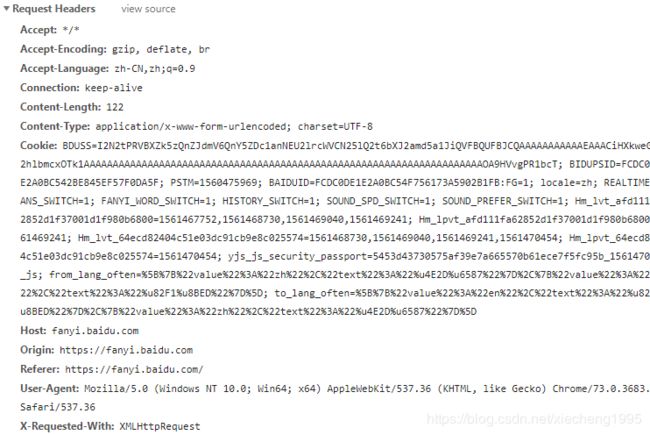
Request Headers:
-
Form Data:

Python程序
# coding=utf-8
import requests
url = "https://fanyi.baidu.com/v2transapi"
data = {
"from": "en",
"to": "zh",
"query": "hello",
"transtype": "translang",
"simple_means_flag": "3",
"token": "f8c8ea6c95d6e9e7ba318e136ee2c490",
"sign": "54706.276099" # 随着翻译内容变化而变化
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Cookie": "BDUSS=I2N2tPRVBXZk5zQnZJdmV6QnY5ZDc1anNEU2lrcWVCN25lQ2t6bXJ2amd5a1JiQVFBQUFBJCQAAAAAAAAAAAEAAACiHXkweGllY2hlbmcxOTk1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOA9HVvgPR1bcT; BIDUPSID=FCDC0DE1E2A0BC542BE845EF57F0DA5F; PSTM=1560475969; BAIDUID=FCDC0DE1E2A0BC54F756173A5902B1FB:FG=1; locale=zh; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; to_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; from_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1561467752,1561468730,1561469040,1561469241; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1561469241; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1561468730,1561469040,1561469241,1561470454; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1561470454; yjs_js_security_passport=5453d43730575af39e7a665570b61ece7f5fc95b_1561470456_js"
}
response = requests.post(url, data=data, headers=headers)
print(response)
print(response.content.decode('unicode_escape')) # 中文转码
程序说明:
- url为General中Request URL的地址;
- data是将 Form Data中的内容写成字典的形式;
- headers是请求头,从Request Headers中将"User-Agent"和"Cookie"提取出来;
- response.content.decode(‘unicode_escape’):当相应结果中存在中文的时候,利用这种编码格式进行转码。
结果如下:
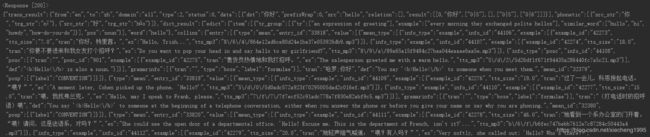
注意
由于百度对外部爬虫的限制,在请求头当中,一定要把cookie带上,否则会出现error:997,没有翻译结果等类似的错误。另外data中内容一定要全,经笔者测试,改变翻译内容,data中的sign会发生变化,其他的如token(应该是加密用的),包括请求头中的cookie,user-agent在同一个浏览器下是不会改变的。sign的加入应该是百度为了防止外界直接对url进行请求,而不通过浏览器请求的一种限制吧。
本人原创,转载请标明出处,谢谢合作!