deep learning 学习笔记(一):神经网络的发展
神经网络作为机器学习的一门重要技术,已经经历了数十年的发展。下面对它做一个简单的归纳。
(1) 奠基阶段 . 早在 40 年代初,神经解剖学、神经生理学、心理学以及人脑神 经元的电生理的研究等都富有成果.其中,神经生物学家 McCulloch 提倡数字化具有特 别意义.他与青年数学家 Pitts 合作[ 1 ],从人脑信息处理观点出发,采用数理 模型的方法研究了脑细胞的动作和结构及其生物神经元的一些基本生理特性,他们提出了第 一个神经计算模型,即神经元的阈值元件模型,简称 MP 模型,他们认识到了模拟大脑可 用于逻辑运行的网络,有一些结点,及结点与结点之间相互联系,构成一个简单神经网络模 型.其主要贡献在于:结点的并行计算能力很强,为计算神经行为的某此方面提供了可能性 ,从而开创了神经网络的研究.这一革命性的思想,产生了很大影响.50年代初,神经网络理论具备了初步模拟实验的条件,Rochester,Holland与IBM 公司的研究人员合作,通过阿络吸取经验来调节强度,以这种方式模拟Hebb的学习规则,在IBM701计算机上运行,取得了成功;1 954年生理学家Eccles提出了真实突触的分流模型。1956年Uttley发明了一种由处理单元组成的推理机,它是一种线性分离器,利用Shannon的熵值与输入输出概率之比的自然对数来调节其输人参数。
(2) 第一次高潮阶段.1958 年计算机科学家 Rosenblatt [ 9 ]基于 MP 模型,增加了学习机制,推广了 MP 模型.他证明了两层感知器能够将输入分为两类,假如这两种类型是线性并可分,也就是一个超平面能将输入空间分割,其感知器收敛定理:输入和输出层之间的权重的调节正比于计算输出值与期望输出之差.他提出的感知器模型,首次把神经网络理论付诸工程实现.例如, 1957 年到 1958 年间在他的帅领下完成了第一台真正的神经计算机,即: Mark Ⅰ的感知器.他还指出了带隐层处理元件的 3 层感知 器这一重要的研究方向,并尝试将两层感知器推广到 3 层.但他未能找到比较严格的数学方法来训练隐层处理单元.这种感知器是一种学习和自组织的心理学模型,其结构体现了神经生理学的知识.当模型的学习环境有噪音时,内部结构有相应的随机联系,这种感知器的学习规则是突触强化律,它可能应用在模式识别和联想记忆等方面.可以说,他的模型包含了一些现代神经计算机的基本原理,而且是神经网络方法和技术上的重大突破,他是现代神经网络的主要建构者之一. Rosenblatt 之举激发了许多学者对神经网络研究的极大兴趣. 美国上百家有影响的实验室纷纷投入这个领域,军方给予巨额资金资助,如,对声纳波识别 ,迅速确定敌方的潜水艇位置,经过一段时间的研究终于获得了一定的成果.这些事实说明 ,神经网络形成了首次高潮.
(3) 坚持阶段. 60年代末,Minsky从感知器的功能及局限性入手,在数学上进行了分析,证明了感知器不能实现 XOR 逻辑函数问题,也不能实现其它的谓词函数.他认识到感知器式的简单神经网络对认知群不变性无能为力.1969 年 Minsky 和 Papert 在 MIT 出版了一本论著 Percertrons ,对 当时与感知器有关的研究及其发展产生了恶劣的影响,有些学者把研究兴趣转移到人工智能 或数字计算机有关的理论和应用方面.这样,推动了人工智能的发展,使它占了主导地位.美国在此后 15 年里从未资助神经网络研究课题,前苏联有关研究机构也受到感染,终止了已经资助的神经网络研究的课题.
(4) 第二次高潮阶段.Kohonen 提出了自组织映射网络模型[ 24-26 ],映射具有拓扑性质,对一维、二维是正确的,并在计算机上进行了模拟,通过实例 所展示的自适应学习效果显著.他认为有可能推广到更高维的情况.当时,他的自组织网络 的局部与全局稳定性问题还没有得到解决.值得一提的是, Hinton 和 Anderson 的著作 Para llel Models of Associative Memory 产生了一定的影响.由于理想的神经元连接组成的理 论模型也具有联想存储功能,因此特别有意义.这类神经网络从 40 年代初就有学者在研究. 当然,不同时期总有新的认识. 1982 年生物物理学家 Hopfield [ 27 ]详细阐述了它的 特性,他对网络存储器描述得更加精细,他认识到这种算法是将联想存储器问题归结为求某 个评价函数极小值的问题,适合于递归过程求解,并引入 Lyapunov 函数进行分析.在网络中 ,节点间以一种随机异步处理方式相互访问,并修正自身输出值,可用神经网络来实现,从 而这类网络的稳定性有了判据,其模式具有联想记忆和优化计算的功能.并给出系统运动方 程,即 Hopfield 神经网络的神经元模型是一组非线性微分方程.
(5)新发展阶段. 神经网络的发展已到了一个转折的时期,它的范围正在不断扩大,其应用领域几乎包括各个方面. 90 年代初,对神经网络的发展产生了很大的影响是诺贝尔奖获得者 Edelman 提出了 Darwini sm 模型.神经网络的光学方法,能充分发挥光学强大的互连能力和并行处理能力,提高神经网络实 现的规模,从而加强网络的自适应功能和学习功能,因此近来引起不少学者重视.对于不变性模式识别机制的理解,是对理论家的一大挑战,尤其是对于多目标的旋转不变 分类识别问题的研究,具有广泛的应用前景.
伴随着神经网络理论的不断发展,网络模型也在发生变化.
第一代神经网络
感知器(~1960)
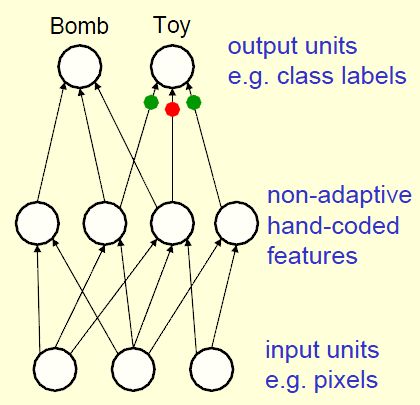
感知器(Perceptrons)使用一层手编(Hand-coded)特征,通过学习如何给这些特征加权来识别对象。
感知器的优点:调整权值的学习算法很简洁。
感知器的缺点:对于线性可分样例,通过一定的学习算法可以收敛到一组可以正确划分所有训练样例的权值向量;但是对于线性不可分的样例,不能保证收敛.
第二代神经网络
BP(反向传播,Back-propagate)神经网络(~1985)
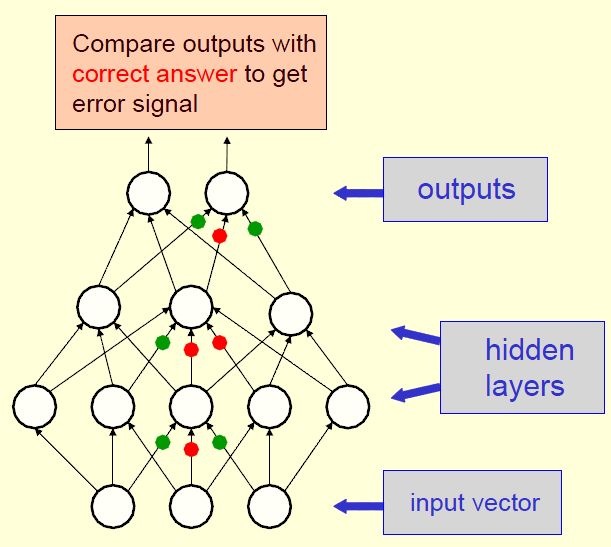
BP神经网络通常使用梯度法来修正权值。
BP并不是一种很实用的方法。原因有三:
- 它需要被标记的训练数据,但是几乎所有的数据都是未标记的。
- 学习时间不易衡量,在多层网络中,速度非常慢。
- 它陷入局部极小点而不收敛的情况极大。
神经网络(Neural Network)与支持向量机(Support Vector Machines,SVM)是统计学习的代表方法。可以认为神经网络与支持向量机都源自于感知机(Perceptron)。感知机是1958年由Rosenblatt发明的线性分类模型。感知机对线性分类有效,但现实中的分类问题通常是非线性的。
神经网络与支持向量机(包含核方法)都是非线性分类模型。1986年,Rummelhart与McClelland发明了神经网络的学习算法Back Propagation。后来,Vapnik等人于1992年提出了支持向量机。神经网络是多层(通常是三层)的非线性模型,支持向量机利用核技巧把非线性问题转换成线性问题。
神经网络与支持向量机一直处于“竞争”关系。
Scholkopf是Vapnik的大弟子,支持向量机与核方法研究的领军人物。据Scholkopf说,Vapnik当初发明支持向量机就是想"干掉"神经网络(He wanted to kill Neural Network)。支持向量机确实很有效,一段时间支持向量机一派占了上风。
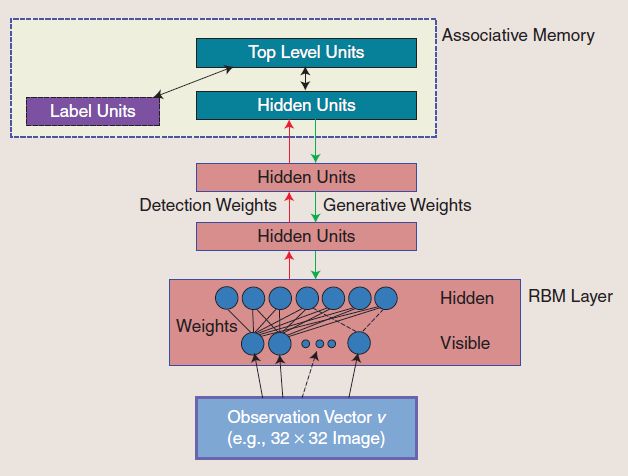
近年来,神经网络一派的大师Hinton又提出了神经网络的Deep Learning算法(2006年),使神经网络的能力大大提高,可与支持向量机一比。
Deep Learning假设神经网络是多层的,首先用Boltzman Machine(非监督学习)学习网络的结构,然后再通过Back Propagation(监督学习)学习网络的权值。
关于Deep Learning的命名,Hinton曾开玩笑地说: I want to call SVM shallow learning. (注:shallow 有肤浅的意思)。其实Deep Learning本身的意思是深层学习,因为它假设神经网络有多层。
总之,Deep Learning是值得关注的统计学习新算法。
第三代神经网络
最近的神经科学研究表明,和人类的许多认知能力相关的大脑皮层,并不显式地预处理感知信号,而是让它们通过一个复杂的模块层次结构,久而久之,就可以根据观察结果呈现的规律来表达它们。
这一发现促进了深机器学习(DML, Deep Machine Learning)的发展。DML关注的恰恰正是是信息表达的计算模型,和大脑皮层类似。
目前DML领域有两种主流的方法:
- Convolutional Neural Networks
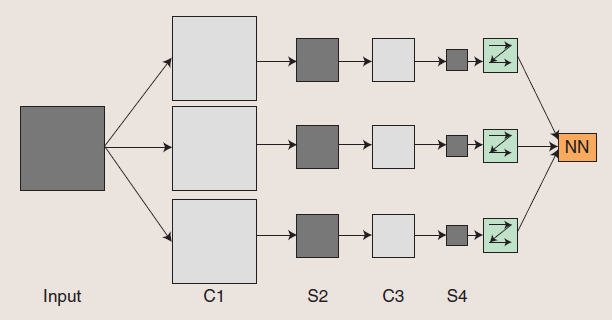
- Deep Belief Networks