Redis Cluster数据分片实现原理、及请求路由实现
Redis在3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。但redis cluster发布得比较晚(2015年才发布),在这期间各个大厂在redis主从模式上开发了自己的集群,想进一步详细了请参考:聊聊Redis的各种集群方案、及优缺点对比。
Redis Cluster模式为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。Redis Cluster集群采用了P2P的模式,完全去中心化。
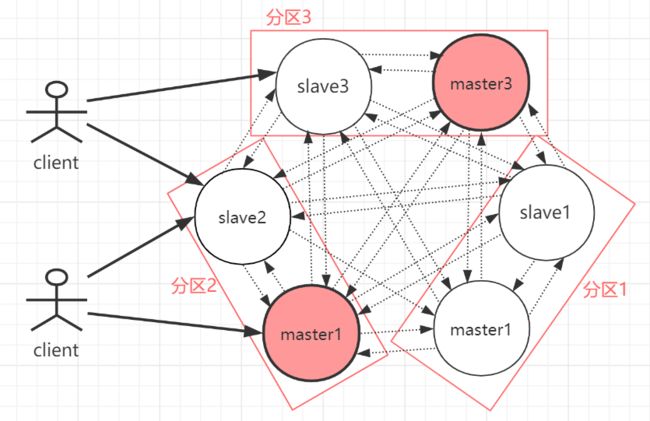
如上图,官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。Redis Cluster集群具有如下几个特点:
-
集群完全去中心化,采用多主多从;所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
-
每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。
-
每一个master节点负责维护一部分槽,以及槽所映射的键值数据。
redis cluster主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster,数据量不是很大时,使用sentinel就够了。redis cluster的性能和高可用性均优于哨兵模式。
1.分片机制-虚拟槽
Redis Cluster采用虚拟哈希槽分区而非一致性hash算法,预先分配16384(2^14)个卡槽,所有的键根据哈希函数映射到 0 ~ 16383整数槽内,每一个分区内的master节点负责维护一部分槽以及槽所映射的键值数据。
#key到hash槽映射算法:对每个key计算CRC16值,然后对16384取模
计算公式:slot = CRC16(key) & 16383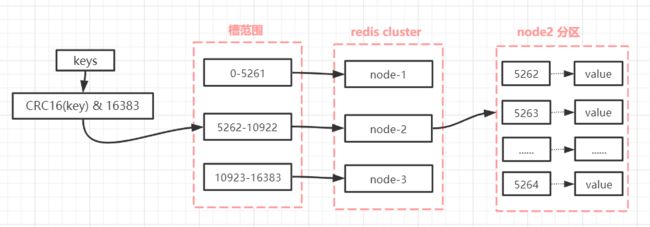
这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。使用哈希槽的好处就在于可以方便的添加 或 移除节点,当添加或移除节点时,只需要移动对应槽和数据移动到对应节点就行。
需要注意的是:
-
(1) hash卡槽只会分配给每个片区的主节点上,从节点不会分配卡槽,从节点会同步master上的hash槽。
-
(2)每个hash卡槽可以存放多个Key,每一个数据key对应一个hash槽。
-
(3)hash卡槽的目的是确认数据存放到哪个片区的Redis主节点上,实现Redis集群分摊Key。
-
(4) 每个片区的Redis主节点卡槽数都对应一个范围,多个片区之间卡槽数范围是等比分配的。比如:存在3个片区对应3个Redis主机,那么3个Redis主机的卡槽总数分别是:16384/3。3个Redis主机的卡槽范围分别是:
第一台Redis主机:0~5461
第二台Redis主机:5462 ~ 10922
第三台Redis主机:10923~16383
-
(5)写操作时,会根据Key值计算出对应的卡槽所在的位置,再将数据存入卡槽区对应的master中;读数据也是一样,通过key得到slot,再通过slot找到node获取数据(客户端读请求是打到任意节点上的,当请求的数据没有在接受请求的node上时,会出现重定向,后面有详细讲解)。
-
(6)Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽。所以客服端请求任意一个节点,都能获取到slot对应的node信息。
Redis 虚拟槽分区的特点:
-
解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
-
节点自身维护槽的映射关系,不需要客户端 或 代理服务维护数据分片关系。
-
Redis Cluster的节点之间会共享消息,每个节点都知道另外节点负责管理的槽范围。每个节点只能对自己负责的槽进行维护 和 读写操作。
#面试题:
#1.redis cluster为什么没有使用一致性hash算法,而是使用了哈希槽预分片?
缓存热点问题:一致性哈希算法在节点太少时,容易因为数据分布不均匀而造成缓存热点的问题。一致性哈希算法可能集中在某个hash区间内的值特别多,会导致大量的数据涌入同一个节点,造成master的热点问题(如同一时间20W的请求都在某个hash区间内)。
#2.redis的hash槽为什么是16384(2^14)个卡槽,而不是65536(2^16)个?
(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3)槽位越小,节点少的情况下,压缩率高。集群配置:
#1.redis cluster的集群模式可以部分提供服务,当redis.conf的配置cluster-require-full-coverage为no时,表示当一个小主从整体挂掉的时候集群也可以用,也是说0-16383个槽位中,落在该主从对应的slots上面的key是用不了的,但key落在其他的范围是仍然可用的。
#2.在cluster架构下,默认的,一般redis-master用于接收读写,而redis-slave则用于备份,当有请求是在向slave发起时,会直接重定向到对应key所在的master来处理。但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。
#3.redis-cluster 不可用的情况
(1)集群主库半数宕机(无论是否从库存活)。
(2)集群某一节点的主从全数宕机。2.Redis cluster伸缩的原理
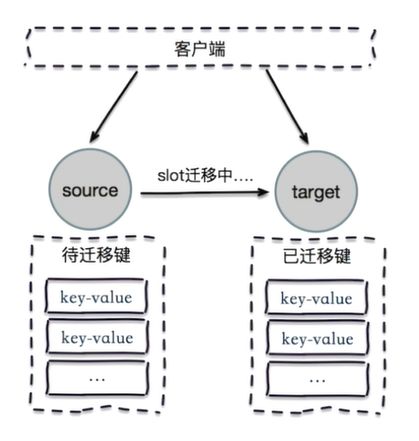
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。当动态添加或减少node节点时,只需要将16384个槽做个再分配,将槽中的键值和对应的数据迁移到对应的节点上。redis cluster提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容,也可以下线部分节点进行缩容。可以说,槽是 Redis 集群管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
(1)集群扩容
当一个 Redis 新节点运行并加入现有集群后,我们需要为其迁移槽和槽对应的数据。首先要为新节点指定槽的迁移计划,确保迁移后每个节点负责相似数量的槽,从而保证这些节点的数据均匀。如下图:向有三个master集群中加入M4(即node-4),集群中槽和数据的迁移。
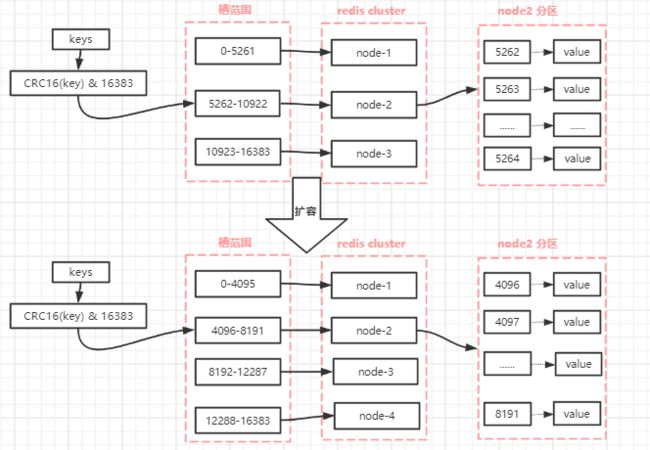
#集群扩容过程:
1.首先启动一个 Redis 节点,记为 M4。
2.使用 cluster meet 命令,让新 Redis 节点加入到集群中。新节点刚开始都是主节点状态,由于没有负责的槽,所以不能接受任何读写操作,后续我们就给他迁移槽和填充数据。
3.对M4节点发送 cluster setslot { slot } importing { sourceNodeId } 命令,让目标节点准备导入槽的数据。 对源节点,也就是 M1,M2,M3 节点发送 cluster setslot { slot } migrating { targetNodeId } 命令,让源节点准备迁出槽的数据。
4.源节点执行 cluster getkeysinslot { slot } { count } 命令,获取 count 个属于槽 { slot } 的键,然后执行步骤五的操作进行迁移键值数据。
5.在源节点上执行 migrate { targetNodeIp} " " 0 { timeout } keys { key... } 命令,把获取的键通过 pipeline 机制批量迁移到目标节点,批量迁移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
6.重复执行步骤 5 和步骤 6 直到槽下所有的键值数据迁移到目标节点。
7.向集群内所有主节点发送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽执行新节点(2)集群收缩
收缩节点就是将 Redis 节点下线,整个流程需要如下操作流程:
-
首先需要确认下线节点是否有负责的槽,如果有,需要把槽和对应的数据迁移到其它节点,保证节点下线后整个集群槽节点映射的完整性。
-
当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记改节点后可以正常关闭。
下线节点需要将节点自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。迁移完槽后,还需要通知集群内所有节点忘记下线的节点,也就是说让其它节点不再与要下线的节点进行 Gossip 消息交换。
3.客户端请求路由
(1)moved重定向
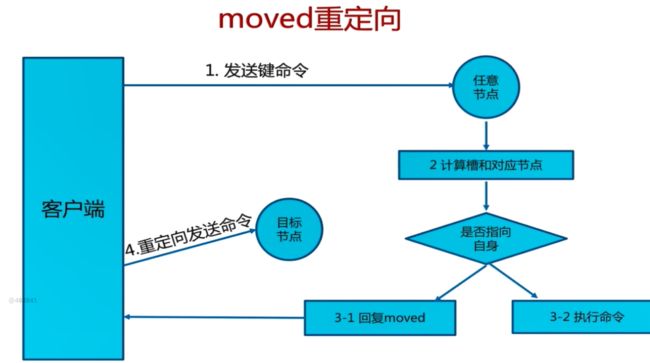
客服端请求产生moved重定向的执行过程:
-
1.每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系。
-
2.客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与16383取余,计算自己的槽和对应节点 。
-
3.如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端。
-
4.如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常 。
-
5.客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息。
-
6.客户端向目标节点发送命令,获取命令执行结果。
(2)ask重定向
在对集群进行扩容和缩容时,需要对槽及槽中数据进行迁移。当槽及槽中数据正在迁移时,客服端请求目标节点时,目标节点中的槽已经迁移支别的节点上了,此时目标节点会返回ask转向给客户端。
当客户端向某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应的槽的节点信息;客户端再向正确的节点发送命令时,如果此时正在进行集群扩展或者缩空操作,槽及槽中数据已经被迁移到别的节点了,就会返回ask,这就是ask重定向机制。如下图:
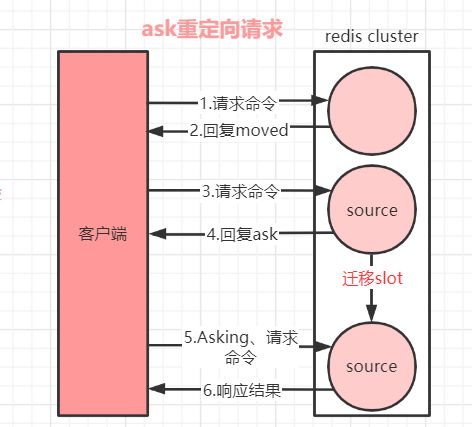
请求执行步骤:
-
1.当客户端向集群中某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应目标槽的节点信息。
-
2.客户端再向目标节点发送命令,目标节点中的槽已经迁移出别的节点上了,此时目标节点会返回ask重定向给客户端。
-
2.客户端向新的target节点发送Asking命令,然后再次向新节点发送请求请求命令。
-
3.新节点target执行命令,把命令执行结果返回给客户端。
#moved和ask重定向的区别:
两者都是客户端重定向
moved异常:槽已经确定迁移,即槽已经不在当前节点
ask异常:槽还在迁移中(3)smart智能客户端
当数据过多,集群节点较多时,客服端大多数请求都会发生重定向,每次重定向都会产生一次无用的请求,严重影响了redis的性能。如果客户端在请求时就知道由哪个节点负责管理哪个槽,再将请求打到对应的节点上,那就有效的解决了这个问题。
提高redis的性能,避免大部分请求发生重定向,可以使用智能客户端。智能客户端知道由哪个节点负责管理哪个槽,而且某个当节点与槽的映射关系发生改变时,客户端也会进行响应的更新,这是一种非常高效的请求方式。
Jedis为Redis Cluster提供了Smart客户端,也就是JedisCluster类。JedisCluster会从集群中选一个可运行的节点,使用 cluster slots 初始化槽和节点映射,将映射关系保存到本地,为每个节点创建JedisPool,相当于为每个redis节点都设置一个JedisPool,然后就可以进行数据读写操作。
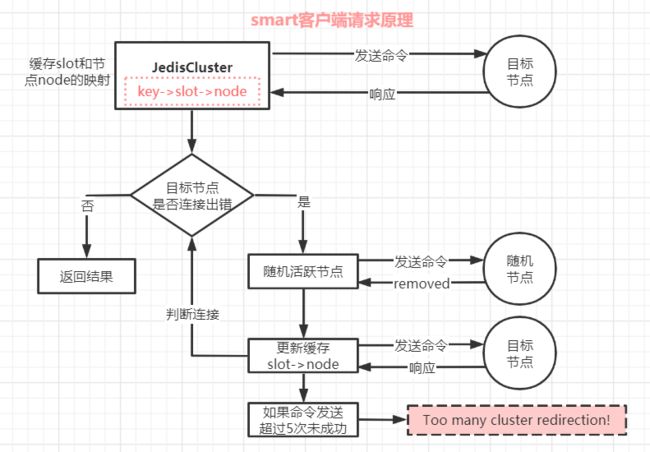
smart智能客户端读写数据命令执行过程如下:
-
1.JedisCluster启动时,会从集群中选一个可运行的节点,使用 cluster slots 初始化槽和节点映射,将映射关系保存到本地。
-
2.smart 客户端将请求要操作的 key 发送到目标节点,如果请求成功,就得到响应,并返回结果。
-
3.如果目标节点出现连接出错(说明节点的slot->node的映射有更新),客户端将随机找个活跃节点,向其发送命令,大概率会得到 moved异常,然后根据moved响应更新 slot 和 node 的映射关系,再向新的目标节点发送命令。
-
如果这样的情况连续出现 5 次未找到目标节点,则抛出异常:Too many cluster redirection!。
总结:mart智能客户的目标:追求性能。避免了大量请求的moved重定向操作,在数据量和请求量大的环境下,极高的提升了redis性能。
4.Redis Cluster主从选举
当某个master挂掉后,在cluster集群仍然可用的前提下,由于某个master可能有多个slave,某个salve将提升为master节点,那么就会存在竞争,那么此时它们的选举机制是怎样的呢?
#1.currentEpoch选举轮次标记
一个集群状态的相关概念,记录集群状态变更的递增版本号。集群中每发生一次master选举currentEpoch就加一,集群节点创建时,不管是 master还是slave,都置currentEpoch为0。
当前节点在接受其他节点发送的请求时,如果发送者的currentEpoch(消息头部会包含发送者的 currentEpoch)大于当前节点的currentEpoch,那么当前节点会更新currentEpoch。
因此,集群中所有节点的 currentEpoch最终会达成一致,相当于对集群状态的认知达成了一致。master节点选举过程:
-
1.slave发现自己的master变为FAIL。
-
2.发起选举前,slave先给自己的epoch(即currentEpoch)加一,然后请求集群中其它master给自己投票,并广播信息给集群中其他节点。
-
3.slave发起投票后,会等待至少两倍NODE_TIMEOUT时长接收投票结果,不管NODE_TIMEOUT何值,也至少会等待2秒。
-
4.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送结果。
-
5.尝试选举的slave收集master返回的结果,收到超过半投票数master的统一后变成新Master,如果失败会发起第二次选举,选举轮次标记+1继续上面的流程。
-
6.选举成功后,广播Pong消息通知集群其它节点。
之所以强制延迟至少0.5秒选举,是为确保master的fail状态在整个集群内传开,否则可能只有小部分master知晓,而master只会给处于fail状态的master的slaves投票。
如果一个slave的master状态不是fail,则其它master不会给它投票,Redis通过八卦协议(即Gossip协议,也叫谣言协议)传播fail。
而在固定延迟上再加一个随机延迟,是为了避免多个slaves同时发起选举。
#延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。每次痛苦的挣扎过程都是一次成长,坚持过去了就海阔天空;越优秀的人,越自律;越痛苦的时候,越要坚持,不忘初心!
2020年07月27号 晚 于北京记