线性数据结构
Python 内置数据结构
分类
数值型
int float complex bool
类型转换
int(x) 返回一个整数
float(x) 返回一个浮点数
complex(x)、complex(x,y) 返回一个复数
bool(x) 返回一个布尔值,False等价对象
序列 (sequence)
1.字符串 str bytes bytearry
2.列表 list 元组 tuple
键值对(keyvalue)
1.集合 set
2.字典 dict
数字的处理函数
取值
1. // 向下取整
2. floor 向下取整
3. ceil 向上取整
4. int 只取整数部分
5. round 四舍六入五取偶





算数
1. min() 取最小值
2. max() 取最大值
3. pow(x,y)等于 x**y
4.math.sqrt() 等于x**0.5
5.进制函数,返回值是字符串
(1) bin()
(2) oct()
(3) hex()
6.math.pi
7.math.e


类型判断
1.type 返回类型而不是字符串
2.isinstance(obj,class_or_tuple) 返回布尔值
举例: type(a)
type('abc')
type(123)
isinstance(6,str)
isinstance(1,(str,int,bool))
type(1+True)
type(1+True+2.0)


列表(list)(排队模型)
1.一个队列,一个排列整齐的队伍
2.列表内的个体称作元素,有若干元素组成列表
3.元素可以是任意对象(数字、字符串、对象、列表等)
4.列表内的元素有顺序,可以使用索引
5.线性的数据结构,顺序结构
6.是一个容器,一个可迭代对象,可遍历(就是把数据拿出来看一下)
7.使用[]表示
列表是可变的
索引
1.索引,也叫下标
2.正索引,从左至右,从0开始为每个元素编号
3.负索引,从右至左,从-1开始
4.正、负索引不可以超界,否则引发异常indexerror
5.列表通过索引访问
list[index],index就是索引,使用中括号访问
6.列表的长度是正索引+1
列表的特点
1.通过索引定位数据速度快,位移比较快
2.在开头或中间增删数据麻烦(在结尾无影响)因为列表需要的是
内存中连续编址的空间,连续开辟的空间,不能断开,
如果在开头或中间添加(删除)数据,那所有的数据都得往后挪动
(往前挪动),牵一发而动全身
链表(Linked list)(手拉手模型)
特点 :
1.通过索引定位数据的速度慢,但是增加或者删除数据的速度快。
比如一个一个的数据中包含着这个数值,上个数据的地址,下个
数据的地址,因为它不是和列表一样编址是连续的,不能位移,
所以它就得从第一个数据中找到下一个数据的地址,然后再从第
二个数据中找到第三个数据的地址,以此类推,需要一个一个的
找下去,比较麻烦。插入数据时只需要把上一个数据的地址和下
一个数据的地址存到插入的这个数据中就行,所以插入数据会比
较简单。
栈(stack)(LIFO:last in first out)
特点 :
1.后进先出
2.一般不插队、不删除数据
3.一般不数数量
队列 (queue)
特点 :
1.先进先出
2.不关注插入元素、删除元素
遍历:不加区别的读取
列表 list定义初始化
1.列表不能一开始就初始化
list=list()
list=[]
list=[2,6,9,'ab']
list=list(range(5))

列表查询
index(value,[start,[stop]])
1. 通过 value,从指定区间查找列表内的元素是否匹配
2.匹配第一个就立即返回索引
3.匹配不到就抛出异常ValueError
count(value)
1.返回列表中匹配的value的次数
时间复杂度
1.index和count方法都是 O(n)
2.随着列表数据规模的增大,而效率下降

返回列表元素的个数(长度)
1.len()
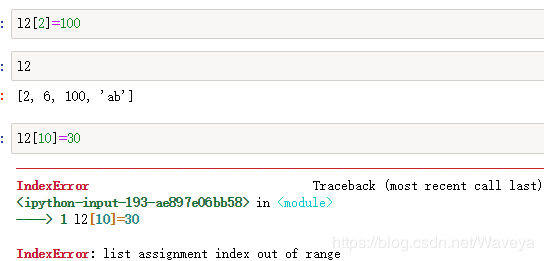
列表元素修改
1.索引访问修改
list[index]=vlaue
修改的索引不要超界
列表增加、插入元素
append(object 元素)->None
1.列表尾部追加元素返回None值
2.返回None值就等于没有新的列表产生,就地修改
3.时间复杂度是O(1)
insert(index,object)->None
1.在指定索引index处插入元素object
2.返回None值就等于没有新的列表产生,就地修改
3.时间复杂度是O(n)
4.索引能超越上下界
超越上界尾部追加
超越下界头部追加

extend(iteratable)-> None
1.将可迭代对象的元素追加进来,返回None
2.就地修改

+ -> list
1.连接操作将两个列表连接起来
2.产生新的列表,原列表不变
3.本质上调用的是魔术方法_add_()方法
* -> list
1.重复操作,将本列表元素重复n次,返回新的列表
l1=[1]*5
l2=[[1]*5]
l3=[[1]]*5
在修改[[1]]*5 的第二个元素里面的第1个元素是,发现其他元素里的第1个元素也被修改了
[[1, 100, 3], [1, 100, 3], [1, 100, 3], [1, 100, 3], [1, 100, 3]]
在对于外面这个[]来说里面有五个元素,对于里面的五个元素来说每个元素又有三个元素
假如把五个元素标注上门牌号 401、401、 401、 401、 401,因为是把一个元素重复了5
次所以他们的门牌号一致,它们存的是引用地址但是,修改401里面的元素就是把它指向
的东西修改了,本质改变了,所以其他元素也修改了。
列表重复的坑
* -> list
1.重复操作,将本列表元素重复n次,返回新的;列表


列表删除元素
remove (value) -> None
1.从左至右查找第一个匹配value的值,找到就移除该元素并返回None,否则ValueError
2.就地修改
3.效率低O(n)

pop([index]) -> item
1.不指定索引index,就从列表尾部弹出一个元素
2.指定索引index,就从所引出弹出一个元素,索引超界就抛出IndexError 的错误
3.不指定索引的效率高,指定索引的效率低

clear() -> None
1.清除列表的所有元素,只剩下一个空列表
列表的其他操作
reverse() -> None
1.将列表元素反转,返回None
2.就地修改
sort(KEY=None,reverse=False) -> None
1.对列表元素进行排序,就地修改,默认排序
2.reverse为True ,反转,降序
3.key 一个函数,指定key如何排序

列表复制
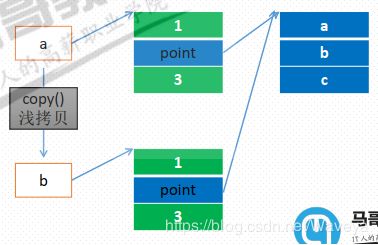
copy() ->list
shadow copy
影子拷贝也叫浅拷贝,遇到引用类型只是复制了一个引用而已
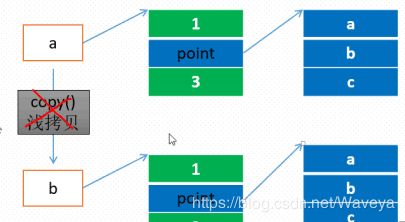
深拷贝
copy模块提供了deepcopy
随机数
random 模块
1. random.choice(seq) 从非空序列的元素中随机挑选一个元素
2. random.shuffle(list) ->None 就地打乱列表元素
3. random.randint(a,b) 返回[a,b]之间的整数,闭区间
4. random.randrange(a,b) 返回[a,b)之间的整数,前包后不包区间
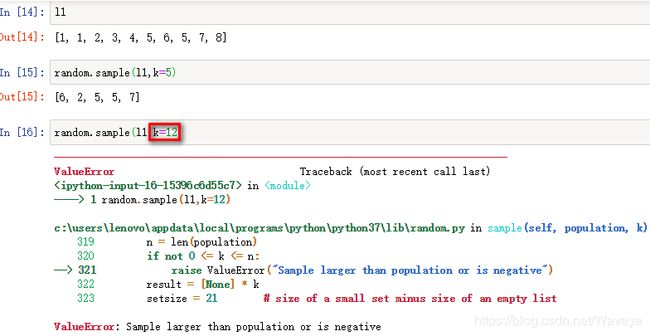
5. random.sample (population,k) 从样本空间或总体(序列或者集合类型)
中随机抽出k个不同的元素,不同位置上的抽取,返回一个新列表