神经网络---反向传播算法(手写简单了全连接网络的框架)
反向传播
学习神经网络将近一年了。当初感觉一直难以理解的梯度下降,反向传播算法,终于在今这个特殊的时候,有了新的深刻认识。这次博客用来记录我的学习成长,也希望能帮助那些这部分内容没掌握好的朋友。这部分内容属于我的个人从不懂到懂的理解过程,会很通俗!
学习基础
需要神经网络的基础
需要对函数的求偏导,链式法则
正向传播
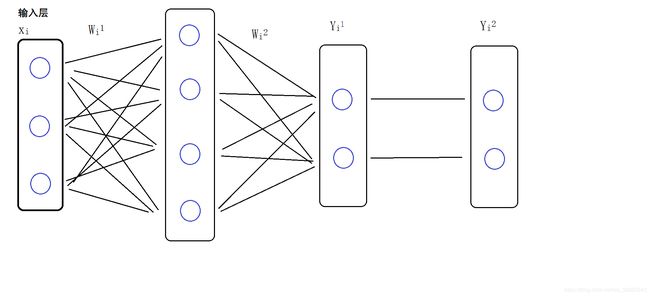
我的这个图可能和网上其他图可能不一样,为了方便初学者理解,我将中间的激活函数取消,将最后的输出层的激活函数分离开了
解析:
X为输入层
W1为输入层和中间层的权重
W2为中间层和Y1之间的权重
Y1为输出的全连接层
Y2为输出加入激活函数之后的输出结果
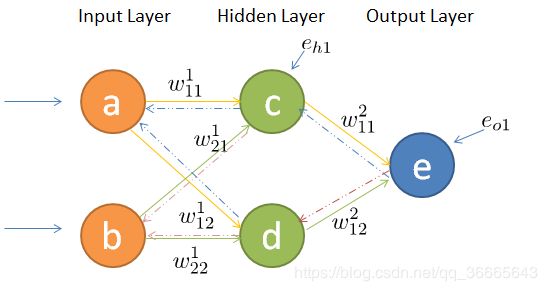
这个图是网上下载的一个比较典型的图了,我就拿这个图进行讲解
参数讲解:
a,b理解为输入值,相当于input=[[a,b]]
c,d理解为中间层,相当于input=[[c,d]]
e为输出值,通过激活函数之后的,这里我们定义激活函数为sigmoid
下面,我用中间层的输出层中的权重w11举例

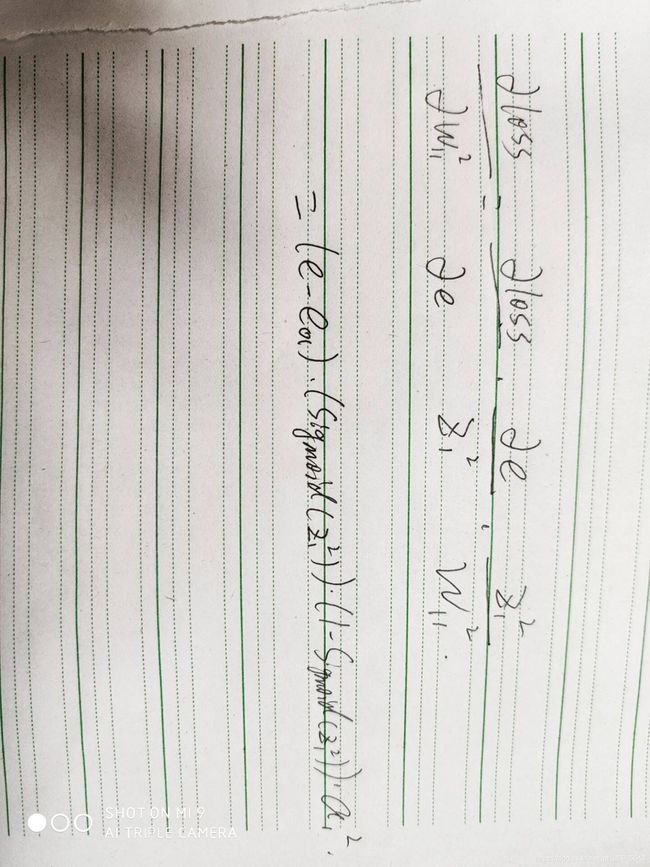
这样对w11求偏导数完毕
接下来是对w11进行更新
公式:w11=w11-learing*dw11(下面对这个公式进行解析,帮助大家理解)

深度学习在矩阵中进行,本是高维度数据。由于在高维度中太过于抽象。于是放进了二维平面。想象一下,f(x)的图就是计算梯度,我们要在梯度中求得最低值。
理想状态下,dw11=0最为合适,也就是图中y=1时的直线。
①如果,求得的dw11在x1处,此时,斜率便是dw11的值,这里为正数,如果想要dw=0,那么,就要让斜率变小,所以公式w11=w11-dw11成立,由于dw11为正数,一个数剪掉一个正数,这个值肯定就变小了。
②如果,求得的dw11在x2处,此时,斜率便是dw11的值,这里为负数。(观察图g(x)和h(x),可知,为负数时,斜率越大,dw11越小)如果想要dw=0,那么,就要让斜率变大。所以公式w11=w11-dw11成立,由于dw11为负数,一个数剪掉一个负数,相当于加上一个正数,这个值肯定就变大了。
③通过发现,我们的公式并不是w11=w11-dw11而是w11=w11-learing*dw11;其实learing就是学习率,通过设置较小的学习率,让dw11进行小幅度的纠正,避免了一次性,直接从负半轴直接冲上了正半轴,过大的话,可能直接造成了误差值越来越大。
下面的是一个bp神经网络(反向传播算法)
程序完成了一个简单的回归操作
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
real=0.114493895339242
# 真实值
net_in=np.array([0.0499853495508432,0.334657078469172]).reshape(1,2) #(1,2)
w_mid=np.random.rand(2,4)
w_out=np.random.rand(4).reshape(4,1) # 输出层的权值
epoch=0
while epoch<2000:
epoch+=1
out_in=np.matmul(net_in,w_mid) # (?,4)
out_y=np.matmul(out_in,w_out)
res=sigmoid(out_y)
print('loss:',np.sum(res-real)**2,res)
learing=0.25
deta=learing*(real-res)*sigmoid(res)*(1-sigmoid(res))
dw2=out_in.T
dw1=np.matmul(w_out,net_in).T
w_mid=w_mid+deta*dw1
w_out=w_out+deta*dw2
大家看了这个简单的程序不知道是不是看懂了很多呢!
下面的大家有兴趣可以看看,完全个人为了学习记录
简介:下面的程序是个人兴趣,想造深度学习框架的轮子,由于前期考虑不足。程序在输出层激活函数求导等地遇到了很大困难!
目前只可以进行简单的全连接,激活函数只能是relu。
代码如下:
import numpy as np
# print(a.shape)
model_sj=[]
num_n=0
class Variable(object):
def __init__(self,size,loc=0,std=0.1,hs=None,name=None):
self.size=size
self.name=name
self.hs=hs
self.loc=loc
self.std=std
self.content=np.random.normal(self.loc, self.std, self.size)
self.shape=self.content.shape
def text(self):
return self.content
def reshape(self,shape):
self.content=self.content.reshape(shape)
self.shape=self.content.shape
class Activations(object):
def __init__(self,x,activation='relu',name=None):
self.activation=activation
self.x = x
self.name=name
self.content=self.__choose()
self.save=self.__save()
def __relu(self,x):
a=np.copy(x) # 用x会直接改变x本身
a[a<0]=0
return a
def __softmax(self,x):
exp=np.exp(x).T
ex=np.exp(x)
return (exp/np.sum(ex,axis=1)).T
def __sigmoid(self,x):
return 1/(1+np.exp(-x))
def __choose(self):
if self.activation=='relu':
return self.__relu(self.x)
elif self.activation=='tanh':
return np.tanh(self.x)
elif self.activation=='sigmoid':
return self.__sigmoid(self.x)
elif self.activation=='softmax':
return self.__softmax(self.x)
def __save(self):
'''
model_act = {'name': self.name, 'shape': self.content.shape,'data':self.content,'act':self.activation,'type':3} #求偏导,不转置
model_sj.append(model_act)
'''
dx=DAct(self.content).run()
model_1 = {'name': self.name, 'input_data': self.x, 'dx': dx,'type':1}
model_sj.append(model_1)
class model(object):
def __init__(self):
pass
def add(self,layer):
pass
class Dense(object):
def __init__(self,w,input_data,name=None):
self.w=w
# self.activation=activation
self.input_data=input_data
self.name=name
def run(self):
global num_n
y=np.matmul(self.input_data,self.w.content)
num_n=num_n+1
'''
model_x={'name':'x','shape':self.input_data.shape,'data':self.input_data,'type':2} # 不求偏导 不转置
model_w = {'name': self.w.name, 'shape': self.w.content.shape, 'data': self.w.content,'type':1} # 求值,中间需要转置
model_y={'name':self.name,'shape':y.shape,'data':y,'type':0} # 求偏导,转置
model_sj.append(model_x)
model_sj.append(model_w)
model_sj.append(model_y)
'''
model_1={'name':self.name,'input_data':self.input_data,'w':self.w.content,'dx':self.w.content.T,'dw':self.input_data,'type':0}
model_sj.append(model_1)
return y
class DAct(object):
def __init__(self,x,activation='relu'):
self.x=x
self.activation=activation
def __drelu(self,x):
a=np.copy(x)
# print(a)
a[a>0]=1
a[a<0]=0
return a
def run(self):
if self.activation=='relu':
return self.__drelu(self.x)
class comple(object):
def __init__(self,input_data,out_data,y_,loss,learing,epch=10):
self.input_data=input_data
self.out_data=out_data
self.y_=y_ # 预测真实值
self.loss=loss
self.learing=learing
self.epch=epch
def losss(self):
if self.loss=='mse':
return 0.5*(self.out_data-self.y_)**2,self.learing*(self.y_-self.out_data)
def __relu(self,x):
a=np.copy(x) # 用x会直接改变x本身
a[a<0]=0
return a
def __drelu(self,x):
a=np.copy(x)
a[a>0]=1
a[a<0]=0
return a
def run(self):
global num_n
pop=0
while pop<self.epch:
print('-'*30)
pop+=1
lit=[]
loss, ddd = self.losss()
print(np.sum(loss))
for i in range(num_n):
loss, dd = self.losss()
j = 0
l = len(model_sj)
while l>0:
l-=1
if model_sj[l].get('type')==1:
dd=dd*model_sj[l].get('dx')
elif model_sj[l].get('type')==0:
if j==i:
j+=1
d=model_sj[l].get('dw')
dd=np.matmul(dd.T,d)
dit={'w':model_sj[l]['w'],'dw':dd.T}
lit.append(dit)
break
else:
j+=1
d=model_sj[l].get('dx')
dd = np.matmul(dd, d)
for tmp in range(len(lit)):
lit[tmp]['w']+=lit[tmp]['dw']
model_sj[(len(lit)-1-tmp)*2]['w']=lit[tmp]['w']
s=self.input_data
p=0
for tmp in model_sj[:-1]:
if p%2==0:
y = np.matmul(s, tmp['w'])
tmp['x']=s
tmp['dx']=tmp['w'].T
tmp['dw']=tmp['x']
s=y
else:
s=self.__relu(s)
tmp['input_data']=s
tmp['dx']=self.__drelu(s)
p+=1
# -----------------------输出层的激活函数------------------#
s = self.__relu(s)
self.out_data=s
model_sj[-1]['input_data'] = s
model_sj[-1]['dx'] = self.__drelu(s)
# -----------------------输出层的激活函数------------------#
# a=np.array([[1,2,3,4]])
a=np.random.rand(100,2)-0.5 # (?,2)
aa=np.sum(a,axis=1).reshape(100,1) # (100,)
w1=Variable(size=(2,100),name='w1')
b=Dense(w1,a,name='b').run()
y=Activations(b,activation='relu',name='y1').content # (1,10)
w2=Variable(size=(100,1),name='w2')
c=Dense(w2,y,name='c').run()
y2=Activations(c,activation='relu',name='y2').content
z=comple(a,y2,aa,'mse',0.001,epch=1000).run()
上面代码完全是作者兴趣来潮所作,不好的地方可以留言,有什么不懂的地方也可以留言告知!