Mysql之函数&分组函数
select ename,char_length(ename) from emp
注:查询员工姓名的长度,在这里一个字符=一个汉字=一个数字=一个字母select adddate(hiredate,interval 1 day) from test2;
注:给hiredate都加一天,但是原表没改,也可以加一个月/年,就是 1 month或者1 year就行
虽然原表没改,但是你可以得到这个数据啊
create table test as select adddate(hiredate,interval 1 day) from test2;select curdate();
//获取当前日期,如2020-03-13
select curtime();
//获取当前时间, 如17:46:39select md5('wzj')
注:将wzj用md5加密: bb357078df7534c173f68a4932b75dfaselect ename,sal,ifnull(comm,'没有奖金') from emp;
//注:如果comm这个字段为空的话,那么就显示没有奖金!
select ename,if(comm,'有奖金','没有奖金') from emp;
//注:如果comm 不等于null或者0,那么就显示有奖金,否则显示没有奖金,三目运算符!//相当于java中的switch
select case deptno
when 10 then '教研部'
when 20 then '学工部'
else '其他部门'
end from emp;
当工作是销售员,那么它的工资*1.1,当是工作是经理的时候,那么它的工资是*1.0 其他人的工资不变!
select ename, job, sal,(case job when '销售员' then sal*1.1 when '经理' then sal*1.2 else sal end)
from emp
select concat(sal,'块') from emp;
//类似于字符串连接符组函数:max(), min(), avg(), sum(),count() 就不演示了
分组函数:group by
group by后面通常跟一个或多个列名,表示根据一列或多列进行分组
如果根据多列分组,要求多列的值完全相同,才会当成一组
select max(sal),comm from emp;
//n aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'exam.emp.COMM'; this is incompatible with sql_mode=only_full_group_by
注意:如果select后面,出现了组函数,但是没有使用group by子句,那么出现在select后的字段,必须用分组函数包起来!
如果select后既使用了组函数,并且select语句中使用了group by分组子句,那么出现在select后的要么使用分组函数包起来,要么是出现在group by子句后面的列
where和having的区别:
where 和 having都有过滤功能的,where是在分组前过滤,而having是在分组后过滤的
where只能过滤行,不能过滤组,having才能过滤组
所以在where子句后面不能使用组函数,having后面才能使用组函数!!
select deptno,max(sal) from emp group by deptno;
//如果使用了group by的话,那么select后面只能出现组信息,就是代表一个整体的,就是第一人称
可以用“我们”来说,像这里的话,我们的部门编号是xxx, 我们的最高薪水是xxx
//反例: 这里你可以说,我们的名字是xxx, 不行吧,因为一组人里面的名字这么多,我怎么知道?
select deptno,dname from emp group by deptno;
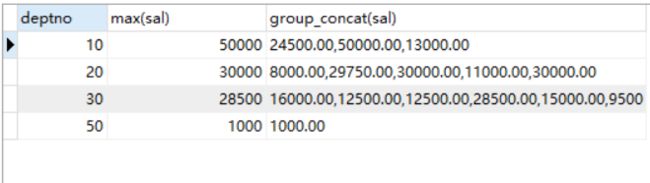
再接受一个分组时容易理解的函数(group_concat)
select deptno,max(sal),group_concat(sal)
from emp
group by deptno
最后:其实不推荐在java程序中使用特定数据库的函数,因为这导致程序和特定的数据库耦合,不方便切换数据库
写sql的顺序
select
from
where
group by
having
order by
limit
执行的顺序是 from where group by having order by limit, 然后显示select后面的列,如果有子查询:会先将值先算出来
来自:虽然帅,但是菜的cxy