1组函数 avg(),sum(),max(),min(),count()案例:
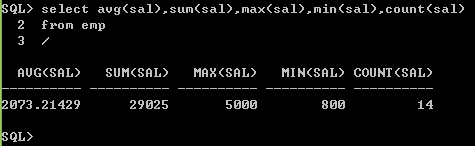
selectavg(sal),sum(sal),max(sal),min(sal),count(sal)
from emp
/
截图:
2 组函数和null在一起
案例:求员工的平均奖金
错误sql:
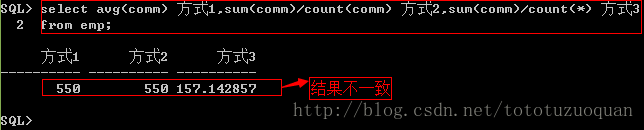
select avg(comm) 方式1,sum(comm)/count(comm)方式2,sum(comm)/count(*) 方式3
from emp;
截图:
错误原因:
select count(comm),count(*) from emp;
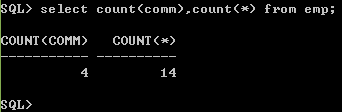
分析:
--组函数自己主动滤空,组函数忽略空值
--修正函数的滤空
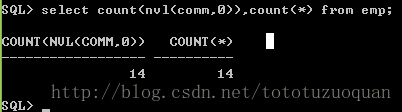
select count(nvl(comm,0)),count(*) fromemp;
3.分组数据
A 求各个部门的平均工资
思路:须要把各个部门的数据划分….10部门 20部门 30部门….分组……
select deptno,avg(sal)
from emp
group by deptno;
执行结果:

B 组函数设计的本意
(1)、select检索的列 必需要位于group by后面的集合列中
(2)、组函数设计的本意:必需要在分组数据之上,进行结果集的检索….
注意:group by子句要求:全部在select中出现的列,都必须在出现group by分组子句中。
select a, b, c
from emp
group by a, b, c,d; 这样的格式是对的,由于在select后的a、b、c都在groub by后面。
select a, b, f
from emp
group by a, b, c,d; 这样的格式是错的,由于在select后的f不在group中
4 在GROUP BY子句中包括多个列
--按部门 不同的职位 统计平均工资
--先依照部门分组。在依照job分组,假设deptno和job一样,就是同一组。然后求平均工资。
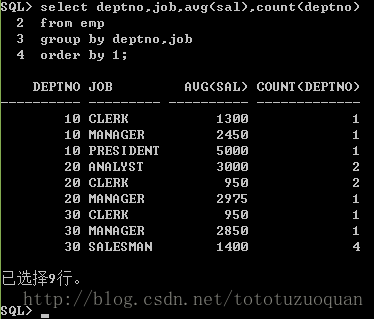
--求各个部门的,每个工种的平均工资
select deptno,job,avg(sal),count(deptno)
from emp
group by deptno,job
order by 1;
截图:
5 分组过滤
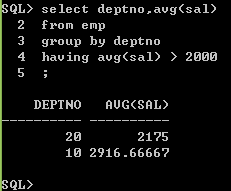
--查询各个部门的平均工资
--进一步。查询平均工资大于2000的部门
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > 2000;
6 having和where子句差别
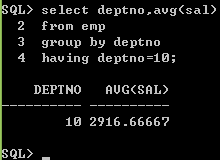
求10号部门的平均工资
方法1:先分组,在过滤
select deptno,avg(sal)
from emp
group by deptno
having deptno=10;
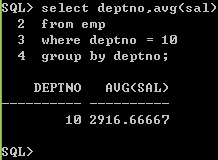
方法2:先过滤再分组
select deptno,avg(sal)
from emp
where deptno = 10
group by deptno;
7 关于sql优化
select * from emp;
select deptno, ename, ..., from emp 把要显示的全部的列都写出来,速度快,,不须要"翻译"
select *form emp
where (deptno = 10) and (deptno = 20) and (deptno=30)
<---------
oracle解析逻辑表达式 的方向....从右向左