使用nGraph的Intel®Xeon®上的高性能TensorFlow
使用nGraph的Intel®Xeon®上的高性能TensorFlow
High-performance TensorFlow* on Intel® Xeon® Using nGraph
最近宣布了nGraph的开源版本™一个C++库、编译器和运行时套件,用于在各种设备上运行深度神经网络。基于Tensraph的优化项目,能公布优化后的项目或反向代码。与我们最初的TensorFlow集成相比,桥接代码实现提供了高达10倍的性能。
设置很简单(我们在bridge代码库中提供了说明):像平常一样构建TensorFlow并选择nGraph作为TensorFlow设备,然后在现有的基于TensorFlow的DL模型中修改几行Python代码以针对nGraph。目前,nGraph支持Intel x86处理器上的工作负载,并将支持Intel®Nervana™ 神经网络处理器(Intel®Nervana™ NNPs)可用时。未来对NVIDIA GPU的支持也在进行中。
英特尔至强处理器上的nGraph性能
新的nGraph TensorFlow桥比上个月开源的初始版本提供了显著的改进。如图1所示,与XLACPU编译器相比,使用nGraph可以显著提高训练性能。虽然需要注意的是,XLA CPU的实现仍然是实验性的,并且有很大的改进空间,但是我们的测量结果表明,nGraph与TensorFlow的IA优化的最新技术相比也非常好。图2比较了MKL DNN优化的TensorFlow实现,它直接在TensorFlow的本地计算引擎中实现MKL-DNN优化,与nGraph TensorFlow桥代码实现进行了比较。在使用ImageNet数据集的ResNet50等模型上,结合nGraph可以获得更好的训练性能(nGraph上为68.9个图像/秒,而TF-MKL-DNN上为64个图像/秒,提高了约7个百分点1)。结果还表明CIFAR10
ResNet模型的性能有了显著的改进。然而,我们注意到,这个差距是由一个已知的问题造成的,这个问题与基线TF-MKL-DNN实现中MKL-DNN原语初始化的开销有关。该问题的解决方案正在向上游的TensorFlow进行。综上所述,这些结果表明nGraph-TensorFlow集成所产生的开销很小,并且可以实现TensorFlow最先进的IA性能。
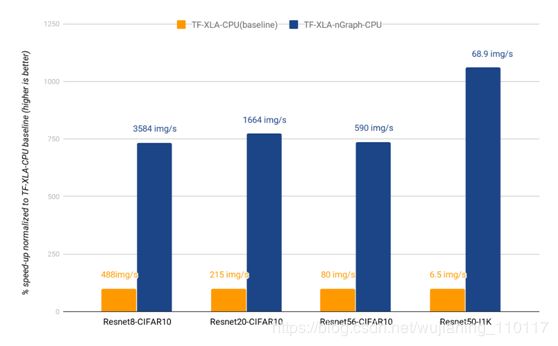
Figure 1: Training speed using TensorFlow-XLA (2S Intel® Xeon® Platinum 8180 CPU) yields 68.9 img/sec at peak performance on
ResNet50-I1k with nGraph and 6.5 img/sec without.

Figure 2: Training speed of ResNet50-I1k using TensorFlow-XLA-nGraph (2S Intel® Xeon® Platinum 8180 CPU) yields 68.9 img/sec at peak performance with nGraph compared to 64 img/sec using MKL-DNN-optimized TensorFlow
How we did it
Performance optimizations in the nGraph CPU backend
nGraph CPU后端(有时称为“IA transformer”)实现了许多优化,在英特尔CPU平台上为给定型号提供了最优化的性能:
与框架无关的优化:
我们利用优化的内核库,如MKL-DNN和Eigen来实现快速DNN内核。此外,我们还加入了图优化过程,这些过程为这些内核实现选择了最佳的数据布局,并减少了图形级别的总体数据布局转换。我们还融合了BatchNorm和ReLu等操作,以更好地利用具有较低内存需求的融合内核实现。
TF/XLA特定的优化:
TensorFlow有一些API级别的缺陷,导致在模型中添加额外的Pad操作。这些操作可能导致不必要的数据布局转换,并且可以通过MKL-DNN提供的填充卷积核来避免。我们利用这一点将这些pad操作融合到现有的卷积算子中,相对于基本的TensorFlow模型,它提供了更好的性能提升。此外,XLA还添加了一些标识操作符,比如从Float32到Float32的类型转换,这些操作符可以从图中删除而不影响正确性。
基于模式匹配的图操作融合
nGraph-IR包含许多常见深度学习原语的内置原语,包括卷积、填充和批处理规范化。之所以选择这些原语,是因为它们可以相对容易地映射到后端库(如“英特尔MKL-DNN”)提供的高度优化的计算内核上。
TensorFlow的tf2xla转换器将一些高级TensorFlow操作分解为根据低级张量操作定义的图。一个经常发生的情况是TensorFlow的平均池操作。如果填充输入张量,则由tf2xla将操作重写为包含以下内容的子图:
a reduce-window operation to sum sliding windows of the graph;
a second reduce-window operation to compute the divisors to apply to each summed window; and
an element-wise division operation.
对图的滑动窗口求和的减窗运算;
第二个reduce window操作,用于计算要应用于每个求和窗口的除数;以及
元素除法运算。
虽然这些操作中的每一个都直接在nGraph中得到支持,但它们的性能将不及nGraph的AvgPool原语,后者直接映射到MKL-DNN提供的优化实现。对于最大池、卷积反向传播和其他一些重要的原语,也会出现类似的情况。
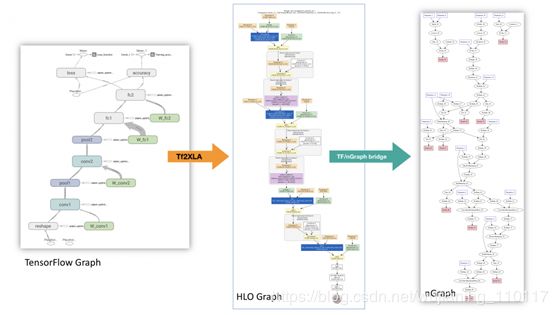
为了解决这个问题,我们在TensorFlow到nGraph桥内部实现了一个HLO融合过程。这个融合过程,如下面的图3所示,补充了nGraph CPU后端本身实现的许多与框架无关的优化。当HLO融合被纳入时,从HLO到nGraph的转换分三步进行。首先,搜索由tf2xla生成的原始图形(图3a),以查找与高级操作对应的模式(在图3b中由橙色节点表示)。第二,每个识别出要融合的子图被包装在一个HLO融合指令中(图3c)。最后,将融合后的HLO图转换为nGraph图(图3d),并将融合指令映射到高级nGraph操作。

Figure 3: Illustration of nGraph graph generation.
fusion pass目前识别卷积反向传播、平均和最大池的正向和反向传播、ReLU的正向和反向传播以及sum、product和max等缩减操作(请注意,其他一些高级操作,包括批处理规范化,在HLO中已被视为原始操作,因此,没有必要将它们熔合。)
它是如何工作的?
TensorFlow的XLA框架为“后端”设备提供了一种机制,用于注册接收以HLO格式表示的计算图,并提供一个能够在运行时执行计算的可执行对象。我们开发了一个XLA插件,它注册为“NGRAPH”设备,遵从并执行HLO计算。
一个动态加载的插件框架
目前,XLA插件设备源代码需要驻留在TensorFlow树中,并且必须与TensorFlow源代码树的其余部分一起构建。添加一个新设备需要理解TensorFlow代码和构建系统,这两者都相当复杂。此外,上游和维护新代码是困难的,有时是不可取的,因为插件实现中的每一个更改都需要经过TensorFlow团队的审核,即使它可能与TensorFlow无关。
我们开发的动态可加载的XLA插件,其中实际的XLA插件源代码位于TensorFlow源代码树之外,它内置于一个动态共享对象(DSO)库中,具有许多nGraph固有的优化。在XLA方面,我们创建了一个插件适配器,该适配器加载插件DSO并使用插件DSO提供的属性注册XLA设备。
Graph compilation and execution
From TensorFlow* computation graph to nGraph
TensorFlow*使用XLA创建HLO计算图。HLO的中间表示(IR)随后被移交给nGraph插件DSO。nGraph桥的源代码位于一个名为nGraph tensorflow bridge的单独GitHub存储库中。
当工作负载部署到目标nGraph设备时,nGraph tensorflow bridge可以将HLO-IR转换为nGraph-IR,然后对其进行编译以生成特定设备的可执行代码。然后,该可执行文件返回到TensorFlow,以便后续执行计算。
Figure 4: Transformation of TensorFlow graph to nGraph IR.
Configuration details
Hardware configuration: 2S Intel® Xeon® Platinum 8180 CPU @ 2.50GHz (28 cores), HT enabled, turbo enabled, scaling governor set to “performance” via intel_pstate driver, 384GB (12 * 32GB) DDR4 ECC SDRAM RDIMM @ 2666MHz (Micron* part no. 36ASF4G72PZ-2G6D1),800GB SSD 2.5in SATA 3.0 6Gb/s Intel Downieville
SSDSC2BB800G701 DC S3520, client ethernet adapter: Intel PCH Integrated 10 Gigabit Ethernet Controller
Software configuration: Ubuntu 16.04.3 LTS (GNU/Linux
4.4.0-109-generic x86_64). Datasets were hosted on NFS storage.
Software Release Versions:
- ngraph-tensorflow, Commit- c2cc26b
- ngraph-tensorflow-bridge, Commit- f9b9e5a
- ngraph, Commit- eec1922
Scripts:https://github.com/NervanaSystems/ngraph-tensorflow bridge/tree/master/test/resnet
Command lines
Resnet cifar10: KMP_BLOCKTIME=1 OMP_NUM_THREADS=56 KMP_AFFINITY=granularity=fine,compact,1,0 python cifar10_main.py --data_dir /path/to/dataset --model_dir /path/to/saved_model/ --batch_size 128 --resnet_size $RESNET_SIZE --data_format channels_first --inter_op 2 --select_device NGRAPH
# (RESNET_SIZE was tested at 8, 20, 56)
Resnet Imagenet(I1k): KMP_BLOCKTIME=0 OMP_NUM_THREADS=56
KMP_AFFINITY=granularity=fine,compact,1,0 python imagenet_main.py --data_dir /path/to/dataset --model_dir /path/to/saved_model/ --batch_size 128 --resnet_size 50 --data_format channels_first --inter_op 2 - select_device NGRAPH