Jdk源码解析
Jdk源码解析
HashMap源码部分
1. HashMap 初始化
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
// 使用默认的初始化容量和默认的加载因子0.75 构造一个空的HashMap,其他所有的字段使用默认值。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
其他字段指的是如下这些:

/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
// 第一次使用的时候 table 会初始化,并根据需要调整大小,
// 当分配大小时,长度总是2的次幂,
// 在某些操作中,我们也允许长度为0,为了允许当前不需要的引导机制。
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
// 保存缓的entrySet(),注意点 这个AbstractMap字段被用于keySet()和values()。
// 父类AbstractMap public abstract Set> entrySet();
// -####拓展源码##----》当前类下搜索即可
transient Set<Map.Entry<K,V>> entrySet;
/**
* Returns a {@link Set} view of the mappings contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own remove operation, or through the
* setValue operation on a map entry returned by the
* iterator) the results of the iteration are undefined. The set
* supports element removal, which removes the corresponding
* mapping from the map, via the Iterator.remove,
* Set.remove, removeAll, retainAll and
* clear operations. It does not support the
* add or addAll operations.
*
// 返回 这个map中包含的一个映射set视图
* @return a set view of the mappings contained in this map
*/
// 这个方法返回一个Set,这个Set是HashMap的视图,对Map的操作会在Set上反映出来
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
/**
* The number of key-value mappings contained in this map.
*/
// 这个map中包含的key-value的数量
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
// 这个map在结构上被修改的次数,结构修改是指那些改变hashMap的映射数量或
// 其他方式修改其内部结构的修改 例如:rehash。这个字段用于使HashMap集合视图上做迭代器操作的快速失败。
// 参考:ConcurrentModificationException
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
* 用于调整大小的下一个size的值 (容量*负载因子)
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
// 如果数组table没有分配,此字段将保留初始数组容量,或使用零标志·表示 DEFAULT_INITIAL_CAPACITY
int threshold;
/**
* The load factor for the hash table.
* hash表的加载因子
* @serial
*/
final float loadFactor;
2. 疑问
-
hashmap中有个entrySet,翻遍了源码也只看到了声明了这个属性,没有任何赋值操作 ?
// HashMap的entrySet()方法返回一个特殊的Set,这个Set使用EntryIterator遍历,而这个Iterator则直接操作
// 于HashMap的内部存储结构table上。通过这种方式实现了“视图”的功能。整个过程不需要任何辅助存储空间。
public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new EntrySet()) : es; }final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } -
为啥size为2的次幂?
3. 面试题
《源码角度一探究竟。源码采用JDK1.7》
Hashmap可以说是Java面试必问的,一般的面试题会问:
- Hashmap有哪些特性?
- Hashmap底层实现原理(get\put\resize)
- Hashmap怎么解决hash冲突?
- Hashmap是线程安全的吗?
=>构造方法 :
首先看构造方法的源码
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
由以上源码可知,Hashmap的初始容量默认是16, 底层存储结构是数组(到这里只能看出是数组, 其实还有链表,
下边看源码解释)。基本存储单元是Entry,那Entry是什么呢?我们接着看Entry相关源码

由Entry源码可知,Entry是链表结构。综上所述,可以得出:Hashmap底层是基于数组和链表实现的
=>Hashmap中put()过程
我已经将put过程绘制了流程图帮助大家理解
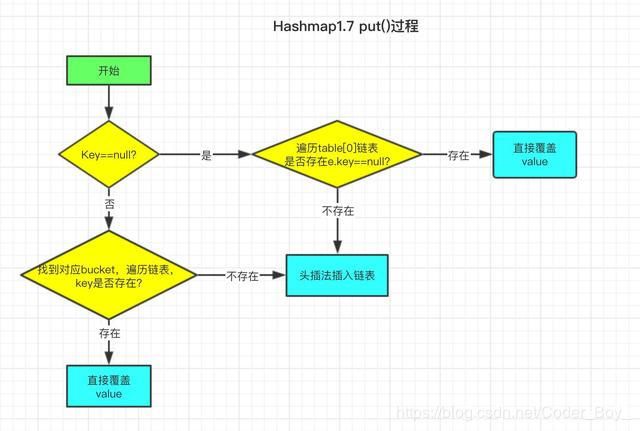
先上put源码
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
// 根据key计算hash值
int hash = hash(key);
// 计算元素在数组中的位置
int i = indexFor(hash, table.length);
// 遍历链表, 如果相同则覆盖原来value值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 修改次数加 1
modCount++;
// 采用头插法插入元素
addEntry(hash, key, value, i);
return null;
}
上图中多次提到头插法,啥是 头插法 呢?接下来看 addEntry 方法
void addEntry(int hash, K key, V value, int bucketIndex) {
// 判断是否需要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容后容量为原来的2倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
// 计算插入元素在扩容后数组中的位置
bucketIndex = indexFor(hash, table.length);
}
// 头插法插入元素的操作
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// 取出原来bucket链表
Entry<K,V> e = table[bucketIndex];
// 头插法 (将添加元素放于原来bucket链表之头部)
table[bucketIndex] = new Entry<>(hash, key, value, e);
// 数组大小加 1
size++;
}
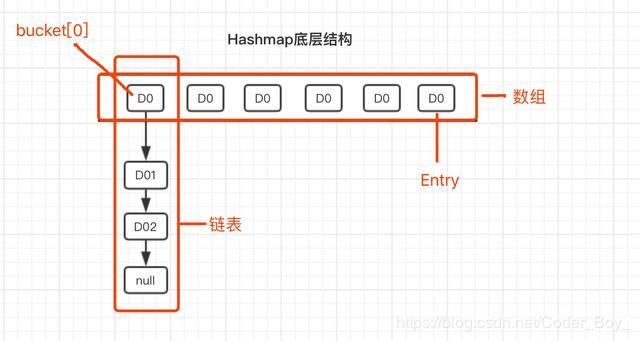
结合Entry类的构造方法,每次插入新元素的时候,将bucket原链表取出,新元素的next指向原链表,这就是 头插法 。为了更加清晰的表示Hashmap存储结构,再绘制一张存储结构图。
==>Hashmap中get()过程
get()逻辑相对比较简单,如图所示
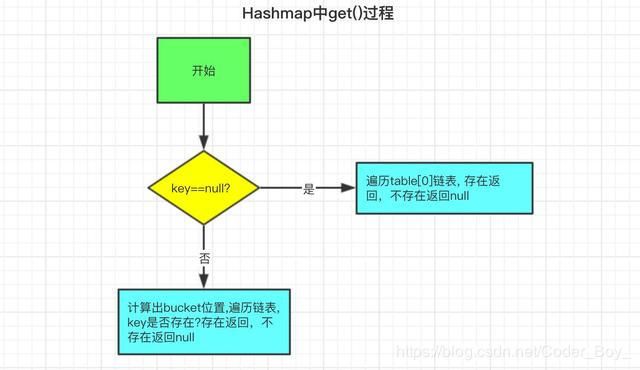
我们来对应下get()源码
public V get(Object key) {
// 获取key为null时的值
if (key == null)
return getForNullKey();
// 不为null时的操作
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
// 根据key获取hash值
int hash = (key == null) ? 0 : hash(key);
// 遍历链表,直到找到对应元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// 更hash值与key的equals比较,都一致则相同
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
==> Hashmap中resize()过程
只要是新插入元素,即执行addEntry()方法,在插入完成后,都会判断是否需要扩容。从addEntry()方法可知,扩容后的容量为原来的2倍。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建数组
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
// 检查是否hash冲突
boolean rehash = oldAltHashing ^ useAltHashing;
// 原有数组中数组 迁移到 新数组中
transfer(newTable, rehash);
// table引用指向新数组
table = newTable;
// 重新计算扩容阈值-[取当前容量*加载因子之乘积和 MAXIMUM_CAPACITY+1 之中最大值]
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
这里有个transfer()方法没讲,别着急,扩容时线程安全的问题出现在这个方法中,接下来讲解数组复制过程。
==> Hashmap扩容安全问题
大家都知道结果: 多线程扩容有可能会形成环形链表,这里用图给大家模拟下扩容过程。
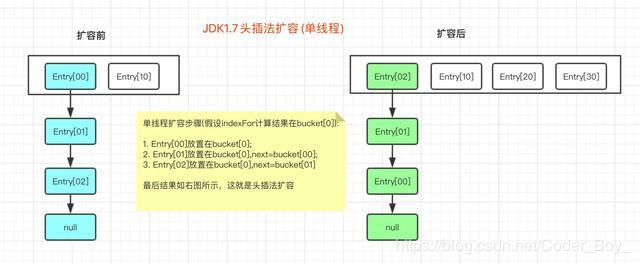
然后看下多线程可能会出现的问题
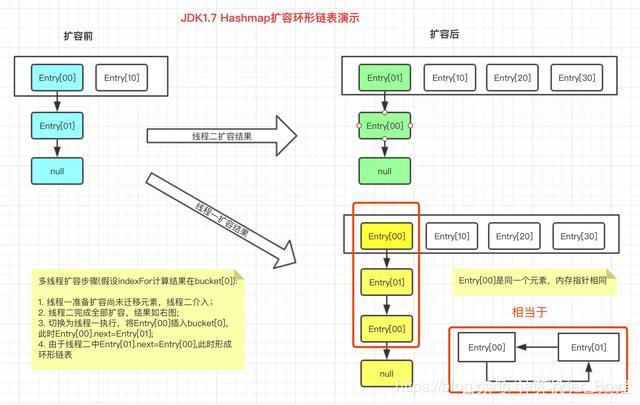
以下 是源码,你仔细分析一下
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
// 配合 最后一段代码 e = next; 做遍历
Entry<K,V> next = e.next;
// 有hash冲突重新计算hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 重新根据新的数组长度计算位置(同一bucket桶上元素的hash值相同,所以扩容后必然还在一个链 // 表上)
int i = indexFor(e.hash, newCapacity);
// 头插法(同一数组位置上的新元素总会被放在链表的头部位置)
// 将newTable[i]引用赋值给了e.next
e.next = newTable[i];
// 将元素放在新数组上
newTable[i] = e;
// 访问下一个元素
e = next;
}
}
}
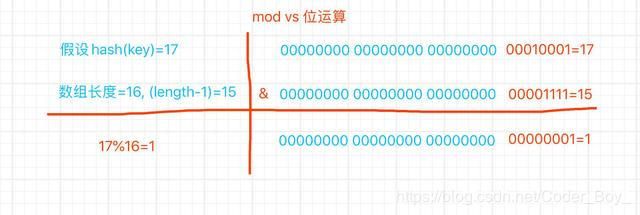
==> Hashmap寻找bucket位置
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// 位运算效率高的写法 计算存放的数组位置
return h & (length-1);
}
由源码可知, jdk根据key的hash值和数组长度做mod运算,这里用位运算代替mod。
hash运算值是一个int整形值,在java中int占4个字节,32位,下边通过图示来说明位运算。