最新-使用selenium爬取淘宝商品数据(扫码方式绕过反爬虫验证),并根据搜索关键词分类
文章目录
- 环境准备
- 爬虫的准备:
- 各函数
- 1.login()
- 2.drop_scroll()
- 3.get_gooods()
- 4.to_searchs()
- 5.save_data()
- 完整代码和数据
- 来个一级标题,记得点个star
视频演示 :https://www.bilibili.com/video/BV1154y1v7tk/
使用selenium爬取淘宝商品数据(扫码方式绕过反爬虫验证),并根据搜索关键词分类
环境准备
博主python为3.8,应该3.x的都没问题
下载selenium:
pip install selenium
也可以使用清华镜像下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
下载浏览器的驱动包,博主使用的是Chrome,下载前,请查看自己的浏览器版本:
驱动镜像–链接,查看版本号,在地址栏输入Chrome://version

在链接中下载自己对应的驱动,如果没有自己的版本号,就试试相近的版本号,将exe文件移动到你的python目录下(其实是因为要配置环境变量,python配置过路径了,移动到它下面就不用在配置啦,你要是python路径也没有配置,就自己手动配置环境变量哦):
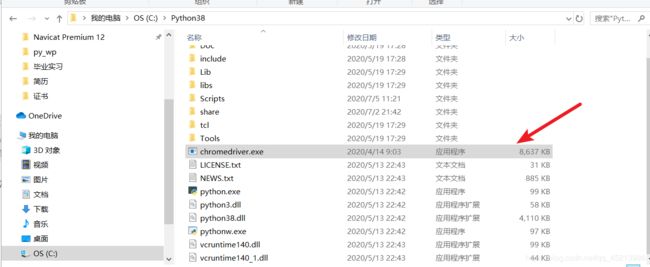
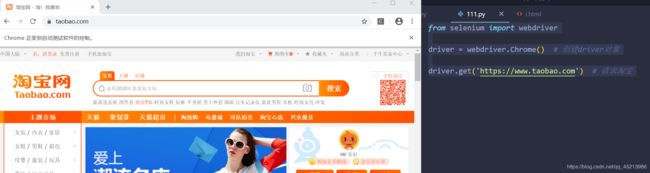
此时,试试运行python代码:
from selenium import webdriver
driver = webdriver.Chrome() # 创建driver对象
driver.get('https://www.taobao.com') # 请求淘宝
弹出淘宝窗口,没有报错,说明可以开始愉快的爬虫啦!
爬虫的准备:
from selenium import webdriver
# 用于延迟等待
import time
# 正则
import re
import requests
import csv
我将各种解释,注释到代码中了,我就不过多解释了,看代码吧。
if __name__ == "__main__":
driver = webdriver.Chrome() # 创建driver对象
#最大化窗口(我试过最大化方便扫码,但是好像会被淘宝识别出机器人,所以我后面换了种方法)
# driver.maximize_window()
# 所有的数据将保存到datas中
datas = []
# 查找的关键词集合
searchs = {'java语言','python','c++','安卓开发','JavaScript','html5','vue','人工智能与机器学习','数据结构','node.js','linux','计算机组成原理','汇编原理','swift语言','go语言'}
# 扫码登录函数
login()
# 查找所有商品信息
to_searchs(searchs)
# 保存数据和图片
save_data(datas)
各函数
1.login()
扫码登录
def login():
# 请求淘宝
driver.get('https://www.taobao.com')
# 输入查询内容
driver.find_element_by_xpath('//*[@id="q"]').send_keys('java')
# 获取到搜索按钮后,点击
driver.find_element_by_xpath(
'//*[@id="J_TSearchForm"]/div[1]/button').click()
# 改变窗口宽度,不要最大化,会被反爬虫检测到
driver.set_window_size(1300, 800)
# 点击二维码扫描
driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
# 等待扫描二维码,时间短了就改一改
time.sleep(10)
2.drop_scroll()
拉动侧边滑动条,使页面数据加载完全
def drop_scroll():
for x in range(1, 11, 2):
# 停一下,慢慢拉,拉快了会出问题哦
time.sleep(0.5)
# 代表滑动条位置
j = x/10
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
# 运行上面的js代码
driver.execute_script(js)
3.get_gooods()
获取商品信息
def get_gooods(serach):
# 获取分页面总数,由于自己的需求,没有翻页,翻页需要的最大值
# 这里提醒大家,如果自己要翻页,请不要点击下一页按钮,也会被检测出来,(可观察后,改变地址栏)
# token = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text
# print(token)
# 序号
xh = 0
# 分析淘宝页面后,获取商品div里面的数据
divs = driver.find_elements_by_xpath(
'//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
# 遍历每个divs,获取商品详细信息
for div in divs:
# print(search)
xh += 1
# 获取图片地址
img = div.find_element_by_xpath(
'.//div[@class="pic"]/a/img').get_attribute('data-src')
# 拼接全地址,用于下载
src_path = "https:"+img
# 请求图片地址,并进行下载,重命名,格式为:分类_序号,没有img文件夹请自己新建
open("./img/{}_{}.jpg".format(serach,xh), mode="wb").write(requests.get(src_path).content)
# 获取标题
title = div.find_element_by_css_selector('div.row.row-2.title').text
# 获取价格
price = div.find_element_by_xpath(
'.//div[@class="price g_price g_price-highlight"]/strong').text+'元'
# 付款人数(销售数)
fukuan = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 一条数据
product = {'分类': serach, '序号': xh, '标题': title,
'imgurl': img, '价格': price, '销售数': fukuan}
print(product)
# 向数组添加一条数据
datas.append(product)
4.to_searchs()
根据自己的关键词开始遍历每个关键词
def to_searchs(serachs):
for serach in serachs:
print(serach)
# 获取文本框
serachInput = driver.find_element_by_xpath('//*[@id="q"]')
# 清空文本框
serachInput.clear()
# 输入查询内容
serachInput.send_keys(serach)
# 点击搜索按钮
driver.find_element_by_xpath('//*[@id="J_SearchForm"]/button').click()
# 拉动侧边滑动条,使页面数据加载完全
drop_scroll()
# 获取商品信息
get_gooods(serach)
5.save_data()
保存数据
def save_data(datas):
# csv文件表头
header = ['分类', '序号', '标题', 'imgurl', '价格', '销售数']
with open('test1.csv', 'a', newline='') as f:
# 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer = csv.DictWriter(f, fieldnames=header)
# 写入列名(表头)
writer.writeheader()
# 写入数据
writer.writerows(datas)
完整代码和数据
请自行克隆代码哦,也有博主爬下来的一些数据,不需要数据,就copy那个py文件吧
gayhub地址:链接