使用Selenium+Chrome/PhantomJS抓取淘宝“美食”详解
参考:崔庆才老师教程
状态:未完成
准备工作
淘宝的页面是相当复杂的,含有各种请求参数或是加密参数,如果直接请求或者分析Ajax将十分繁琐。
Selenium是一个自动化测试工具,可以驱动浏览器完成各种操作,比如模拟点击、输入、下拉等等,这样我们只需要关心操作,而不再需要关心后台发生了什么请求。
Chrome是一个常用浏览器。
PhantomJS是一个无界面浏览器(可以在不打开浏览器界面的情况下完成爬取)。
本次将要爬取的是淘宝“美食”关键词下的所有宝贝内容,并存储到MongoDB。
使用的解析库是PyQuery。
请确保以上类库已经正确安装。
关于下文提到的一些关于selenium的用法,可以在selenium-python中文文档进行查阅。
由于翻译等问题,中文文档的阅读性稍差,你也可以查阅selenium-python英文文档。
目标站点分析
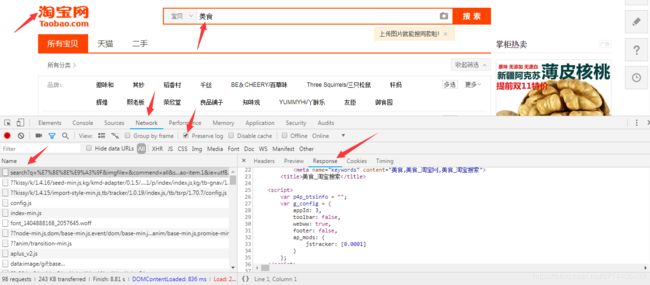
如上图,打开淘宝,搜索关键词“美食”,可以看到许多好吃的(流口水…)。右键审查,点击Network,勾选Preserve log,刷新网页,找到第一个请求并查看返回信息。可以发现,其中都是一些JS代码,并没有任何的商品信息。因此,通过分析Ajax是非常复杂的。那么我们可以通过模拟浏览器的一整套动作来完成。
流程框架
1.搜索关键字
利用Selenium驱动浏览器搜索关键字,得到查询后的商品列表。
2.分析页码并翻页
得到商品页码数,模拟翻页,得到后续页面的商品列表。
3.分析提取商品内容
利用PyQuery分析源码,解析得到商品列表
4.存储至MongoDB
将商品列表信息存储到数据库MongoDB。
爬虫实战
1.搜索关键字
(1)输入关键字、点击搜索
首先新建项目以及py文件。导入selenium中的webdriver并且创建一个浏览器驱动对象:
from selenium import webdriver
browser = webdriver.Chrome() #创建一个Chrome驱动对象
此时运行的话,会弹出一个Chrome浏览器窗口。
如果没有弹出,说明驱动没有安装好。安装步骤可以看这篇文章:https://blog.csdn.net/z714405489/article/details/83047772
接下来定义搜索函数:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#声明一个WebDriverWait对象在里面传入一个browser等待条件参数,一个最长等待时间参数
wait=WebDriverWait(browser, 10)#因为后面用到比较多,所以把这部分单独复制为一个变量
#search函数可以让浏览器输入关键词并点击搜索
def search():
browser.get('https://www.taobao.com')#请求淘宝首页
input = wait.until(#利用wait.until方法传入一些等待的条件,条件的参数是目标元素
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))#通过CSS选择器选择q(也就是搜索框)。
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))#通过CSS选择器选择搜索按钮。
)
input.send_keys('美食')#在搜索框中输入内容
submit.click()#点击按钮,也就是提交搜索内容
这部分可以参考中文文档-5. 等待页面加载完成(Waits)或者https://blog.csdn.net/z714405489/article/details/83280894。
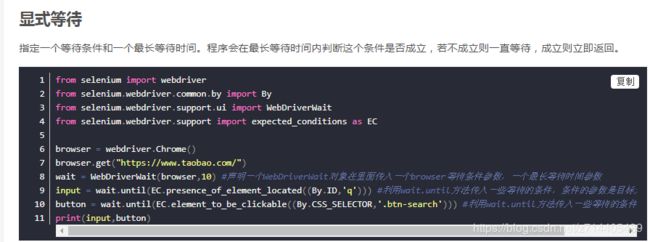

此外,代码中有两处用到了CSS选择器,那么选择器的内容(也就是等待判断条件的另一个参数)怎么获取呢?
可以在审查界面中,先点击左边的select按钮,再点击搜索框,接下来会定位到相应的元素,右击->Copy->Copy selector,再复制到代码中相应的位置即可。“搜索”按钮的选择器同理。
最后在主函数中调用函数即可:
def main():
search()
if __name__ == '__main__':
main()
运行程序之后,浏览器会自动完成相应的动作。
(2)手动登录
问题来了,浏览器点击搜索之后,会跳到登录界面(如果没有那就太爽了)。
我搜索了很多使用selenium进行自动登录、或是绕过selenium检测的方法,但是都没有成功,淘宝的反爬应该还是做得不错的。那么,我们就得需要手动登录了,否则无法进行后面的步骤。
我们可以在
browser.get('https://www.taobao.com')
这条语句之后添加一个延时:
sleep(15)
在15秒的时间内通过扫码登录(账户密码登录是不行的,因为selenium驱动的浏览器无法拖过滑块验证),之后再回到首页,这样20秒结束后,chrome会继续执行后面的动作,而因为现在已经是登录状态,就不会出错了。
2.翻页
好了,处理完上面的小插曲之后,继续。
输入关键词搜索之后,需要等待“页数”加载完成,所以加一个wait(跟上面一个套路):
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
这个CSS选择器同样可以在审查中复制出来。

再加上一个异常判断,最后在主函数里打印一下:
def search():
try:
browser.get('https://www.taobao.com')#请求淘宝首页
sleep(15)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))#通过CSS选择器选择q(也就是搜索框)。
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))#通过CSS选择器选择搜索按钮。
)
input.send_keys('美食')#在搜索框中输入内容
submit.click()#点击按钮,也就是提交搜索内容
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search()
def main():
total = search()
print(total)
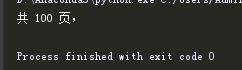
成功取得了页数。
再进一步,我们仅仅需要页数这个数字,那么用正则表达式提取一下:
def main():
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
print(total)
接下来考虑如何实现翻页。

如上图,要实现翻页有两种方式:
- 点击下一页:这种方式需要判断高亮页码的位置,可能会造成位置错乱,容易出错
- 输入页码进行跳转:这种方法比较方便,可行性更高
那么我们选择第二种方式,先定义一个函数用来翻页:
def next_page(page_number):
try:
#获取输入框:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")) # 通过CSS选择器选择q(也就是搜索框)。
)
#获取“确定”按钮
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')) # 通过CSS选择器选择搜索按钮。
)
input.clear()#清楚之前输入的内容
input.send_keys(page_number)#输入页码
submit.click()#点击确定
#判断翻页是否成功(当前页码是否在高亮块中):
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number))
)
except TimeoutException:
然后再主函数中进行调用:
for i in range(2,total+1):
next_page(i)
正当我要运行来测试时,悲剧出现了:

又被淘宝检测到异常了。
马云爸爸你厉害,我选择放弃!
3.分析提取商品内容
这一步需要用到pyquery来解析:
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
html =browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image':item.find('.pic .img').attr('src'),
'price':item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
单页运行:


爬还是能爬的,但是要翻页的话,就会遇到上面的问题了。
4.存储至MongoDB
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到MONGODB成功',result)
except Exception:
print('存储到MONGODB失败',result)
config文件:
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_TABLE = 'product'
准备:
from config import *
import pymongo
client = pymongo.MongoClient(MONGO_URL)
db =client[MONGO_DB]