Spark JobServer简介
SparkJob-Server简介
| 日期 |
版本 |
修订 |
审批 |
修订说明 |
| 2017.2.27 |
1.0 |
章鑫 |
|
初始版本 |
|
|
|
|
|
|
1 简介
Spark-jobserver提供了一个RESTful接口来提交和管理spark的jobs、jars和jobcontext。这个项目包含了完整的Spark job sever的项目,包括单元测试盒项目部署脚本。
2 版本特性
2.1 特性
l “Spark as Service”:针对job和contexts的各个方面提供了REST风格的api接口进行管理
l 支持SparkSQL、Hive、StreamingContext/jobs以及定制job contexts!
l 通过集成Apache Shiro来支持LDAP权限验证
l 通过长期运行的job contexts支持亚秒级别低延迟的任务
l 可以通过结束context来停止运行的作业(job)
l 分割jar上传步骤以提高job的启动
l 异步和同步的job API,其中同步API对低延时作业非常有效
l 支持Standalone Spark和Mesos、yarn
l Job和jar信息通过一个可插拔的DAO接口来持久化
l 对RDD或DataFrame对象命名并缓存,通过该名称获取RDD或DataFrame。这样可以提高对象在作业间的共享和重用
l 支持Scala 2.10版本和2.11版本
2.2 版本
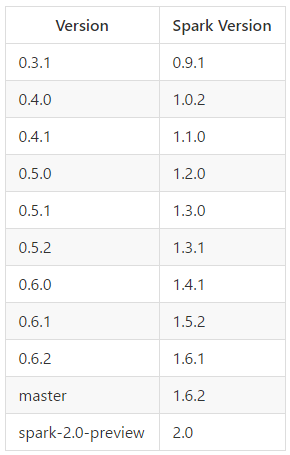
可以查看notes/目录获取更多有关于版本的信息。
3 部署使用
根据上文中提到的版本对应关系,下载压缩包(spark-jobserver-0.6.2.tar.gz)并解压。注意需要有sbt编译环境!
目录结构如下:
| [root@node8 spark-jobserver-0.6.2]# ll total 72 drwxrwxr-x 5 root root 56 Dec 19 14:00 akka-app drwxrwxr-x 3 root root 4096 Feb 23 15:58 bin -rw-rw-r-- 1 root root 27 Apr 28 2016 build.sbt lrwxrwxrwx 1 root root 17 Apr 28 2016 config -> job-server/config drwxrwxr-x 3 root root 4096 Apr 28 2016 doc drwxrwxr-x 6 root root 53 Dec 19 14:00 job-server drwxrwxr-x 4 root root 29 Dec 19 14:00 job-server-api drwxrwxr-x 5 root root 40 Dec 19 16:47 job-server-extras drwxrwxr-x 4 root root 29 Dec 19 14:14 job-server-tests -rw-rw-r-- 1 root root 579 Apr 28 2016 LICENSE.md drwxrwxr-x 2 root root 4096 Apr 28 2016 notes drwxrwxr-x 4 root root 4096 Dec 20 09:44 project -rw-rw-r-- 1 root root 35345 Apr 28 2016 README.md -rw-rw-r-- 1 root root 5939 Apr 28 2016 scalastyle-config.xml drwxrwxr-x 3 root root 17 Apr 28 2016 src drwxr-xr-x 5 root root 88 Dec 19 14:15 target -rw-rw-r-- 1 root root 31 Apr 28 2016 version.sbt |
最简单的启动模式就是尝试使用Dockercontainer安装包,该安装可以方便的完成分布式Spark和jobserver启动和部署。部署所需的脚本均在bin目录下。
另外的话:
l 利用SBT在本地Local模式下完成jobserver的构建和运行。提示:这种方式下不支持YARN模式,而且建议spark.master被设置成local[*]。最好尝试用YARN或者其他真实的集群来部署。
l 在集群上部署job server,这里有两种选择:
n server_deploy.sh将job server部署在一台远程设备的目录上
n server_packager.sh将job server部署在本地(local)目录上,你可以以目录的形式部署;在YARN或Mesos模式下也可以采用.tar.gz的形式部署。
l EC2部署脚本-参照EC2的说明搭建起一个Spark和job server以及一个给定示例的集群。
l EMR部署说明-参照EMR相关说明。
提示:当fork出来的JVM进程中的spark.jobserver.context-per-jvm配置项被设置成true时,Spark Job Server可以选择是否由它们自身来运行SparkContext。这一特性暂时不支持在SBT/local模式中使用。更多相关信息请参考下一小节。
1. Copyconfig/local.sh.template to
| # Environment and deploy file # For use with bin/server_deploy, bin/server_package etc. DEPLOY_HOSTS="node6.dcom node7.dcom node8.dcom"
APP_USER=root APP_GROUP=root # optional SSH Key to login to deploy server #SSH_KEY=/root/.ssh/id_rsa.pub INSTALL_DIR=/home/spark/job-server LOG_DIR=/var/log/job-server PIDFILE=spark-jobserver.pid JOBSERVER_MEMORY=1G SPARK_VERSION=1.6.1 MAX_DIRECT_MEMORY=512M SPARK_HOME=/usr/hdp/current/spark-client SPARK_CONF_DIR=$SPARK_HOME/conf # Only needed for Mesos deploys #SPARK_EXECUTOR_URI=/home/spark/spark-1.6.1.tar.gz # Only needed for YARN running outside of the cluster # You will need to COPY these files from your cluster to the remote machine # Normally these are kept on the cluster in /etc/hadoop/conf YARN_CONF_DIR=/usr/hdp/current/hadoop-client/conf HADOOP_CONF_DIR=/usr/hdp/current/hadoop-client/conf # # Also optional: extra JVM args for spark-submit # export SPARK_SUBMIT_OPTS+="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5433" SCALA_VERSION=2.10.4 # or 2.11.6 |
2. Copyconfig/shiro.ini.template to shiro.ini 并正确编辑内容。注意:只在authentication = on时需要
3. Copyconfig/local.conf.template to
| # Template for a Spark Job Server configuration file # When deployed these settings are loaded when job server starts # # Spark Cluster / Job Server configuration spark { # spark.master will be passed to each job's JobContext #master = "local[4]" # master = "mesos://vm28-hulk-pub:5050" master = "yarn-client"
# Default # of CPUs for jobs to use for Spark standalone cluster job-number-cpus = 4
jobserver { port = 8090 jar-store-rootdir = /tmp/jobserver/jars
context-per-jvm = false
jobdao = spark.jobserver.io.JobFileDAO
job-binary-paths { WL = /home/spark-jobserver/VehicleFootHold-assembly-1.0.jar }
filedao { rootdir = /tmp/spark-job-server/filedao/data }
# When using chunked transfer encoding with scala Stream job results, this is the size of each chunk result-chunk-size = 1m }
# predefined Spark contexts # contexts { # my-low-latency-context { # num-cpu-cores = 1 # Number of cores to allocate. Required. # memory-per-node = 512m # Executor memory per node, -Xmx style eg 512m, 1G, etc. # } # # define additional contexts here # }
# universal context configuration. These settings can be overridden, see README.md context-settings { num-cpu-cores = 2 # Number of cores to allocate. Required. memory-per-node = 512m # Executor memory per node, -Xmx style eg 512m, #1G, etc.
# in case spark distribution should be accessed from HDFS (as opposed to being installed on every mesos slave) # spark.executor.uri = "hdfs://namenode:8020/apps/spark/spark.tgz"
# uris of jars to be loaded into the classpath for this context. Uris is a string list, or a string separated by commas ',' # dependent-jar-uris = ["file:///some/path/present/in/each/mesos/slave/somepackage.jar"]
# If you wish to pass any settings directly to the sparkConf as-is, add them here in passthrough, # such as hadoop connection settings that don't use the "spark." prefix passthrough { #es.nodes = "192.1.1.1" } }
# This needs to match SPARK_HOME for cluster SparkContexts to be created successfully home = "/home/spark/spark" }
# Note that you can use this file to define settings not only for job server, # but for your Spark jobs as well. Spark job configuration merges with this configuration file as defaults.
akka { remote.netty.tcp { # This controls the maximum message size, including job results, that can be sent # maximum-frame-size = 10 MiB } } |
4. bin/server_deploy.sh
5. 在远程服务器上,在部署目录下使用server_start.sh和server_stop.sh来启动和停止job server
server_start.sh脚本调用了spark-submit方法,用户可以输入spark-submit所支持的额外
参数。
注意:默认情况下依赖于job-server-extras打包出来的jar包会包含SQLContext和HiveContext,在使用过程中会面临着所有extra依赖带来的所有问题,请考虑修改install脚本用sbt job-server/assembly来代替,这种方式不会包含extra依赖。
3.1 开发模式
下面给的这个walk-through并不是job server在实际环境中的用法,我们通过这个利用SBT在local模式下运行job server的例子来帮助你更好的理解使用job server。
系统中必须已经正确安装SBT。
利用下方的语句来获得当前的SBT版本:
export VER=`sbt version | tail -1 | cut –f2`
在SBT shell模式下,输入“reStart”,将会采用默认的配置文件。指定配置文件的具体路径可作为可选参数。你也可以在”---“之后设置JVM参数。包括所有参数的命令如下所示:
Job-server/restart /path/to/my.conf --- -Xmx8g
需要注意reStart(SBT Revolver)会为job server另起一个单独的进程。如果你的代码有所变更,直接在SBT shell模式下再次输入reStart,系统将会重新编译代码并重启job server。这使得代码的更新编译变得方便快捷。
注意:不能在操作系统的shell上输入sbt reStart。SBT会启动job server并立即kill掉它。相关的例子在job-server-tests/project/目录中可以找到。
当你使用reStart命令时,日志文件保存在job-server/job-server-local.log中。我们也可以通过设置环境变量EXTRA_JAR往classpath中添加jar包。
3.1.1 WordCountExample
(1)发送jar包至服务器
第一步,使用sbt job-server-tests/package命令将包含WordCountExample的代码编译打包成jar包。
利用下面的命令上传jar包:
| curl --data-binary @job-server-tests/target/scala-2.10/job-server-tests-$VER.jar localhost:8090/jars/test ok(正确返回) |
(2)Ad-hoc模式-单独的job(TransientContext)
刚才上面上传的jar包对应的app为“test”。接下来开启一个ad-hoc的word countjob,即job server创建它自己的SparkContext,并且为下面的查询返回一个job ID:
| curl -d “input.string = a b c a b see” ‘localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample’ { “duration”: ”Job not done yet”, “classPath”: “spark.jobserver.WordCountExample”, “startTime”: “2016-06-19T16:27:12,196+05:30”, “context”: “b7ea0eb5-spark.jobserver.wordCountExample”, “status”: “STARTED”, “jobId”: “5453779a-f004-45fc-a11d-a39ae0f9bf4” } |
注意:如果你想在使用curl的POST命令时读取一个text类型的配置文件,需要加上--data-binary选项,否则curl会munge你的行分隔符。例如:
curl --data-binary @my-job-config.json ‘localhost:8090/job?appName=…’
注意2:如果你想要发送UTF-8格式的字符,确保有合适的消息头以便于CURL命令编码转义,否则将会采用不是你所期望的编码转义格式。
由上可知,我们可以异步的去查询job的状态和结果:
| curl localhost:8090/jobs/5453779a-f004-45fc-a11d-a39dae0f9bf4 { “duration”: “6.431 secs”, “classPath”: “spark.jobserver.WordCountExample”, “startTime”: “2015-10-16T03:17:03.127Z”, “context”: “b7ea0eb5-spark.jobserver.WordCountExamlple”, “result”: { “a”: 2, “b”: 2, “c”: 1, “see”: 1 }, “status”: “FINISHED”, “jobId”: “5453779a-f004-45fc-a11d-a39ae0f9bf4” } |
注意当你想通过一次POST命令去获取所有结果时,可以在命令中加上&sync=true,但
在实际的集群中会性能会比较差。
(3)context保持模式-对需要该特性的job来说会极大的加快速度
预先创建好context来运行该job。创建新的context:
| curl -d “” ‘localhost:8090/contexts/test-context?num-cpu-cores=4&memory-per-node=512m’ ok(正确时返回) |
可通过命令来确认context是否被正确创建:
| curl localhost:8090/contexts [“test-context”] |
现在,用特定的context来运行job并获取结果:
| curl -d “input.string = a b c a b see ” ‘localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample&context=test-context&sync=true’ { “result”: { “a”: 2, “b”: 2, “c”: 1, “see”: 1 } } |
注意context=和sync=true。
3.2 创建Job Server工程
3.2.1 使用giter8从头开始创建工程
一个可用的模板https://github.com/spark-jobserver/spark-jobserver.g8
| $sbt new spark-jobserver/spark-jobserver.g8
该工程包含了用新旧两种API写的Word Count例子 $cd /path/to/project/directory $sbt package |
你可以删除示例代码,添加你自己的代码。
3.2.2 手工创建工程,假设你已经搭建好了sbt项目架构
在build.sbt文件中,加上下面语句以使用job server的相关jar包:
| resolvers += “Job Server Binary” at https://dl.binary.com/spark-jobserver/maven” libraryDependencies += “spark.jobserver” %% “job-server-api” % “0.6.2” “provided”
如果需要SQL或者Hive job/context,需要额外添加job-server-extras: libraryDependencies += “spark.jobserver” %% “job-server-extras” % “0.6.2” “provided” |
在大多数情况下,最好加上“provided”这样就不会使SBT assembly将整个job server jar
打包到工程对应的jar包中。
为了创建一个能够提交至job server的job,你必须实现SparkJob trait。你的代码类似于:
| object SamleJob extends SparkJob { override def runJob(sc: SparkContext, jobConfig: Config): Any = ??? override def validate(sc: SparkContext, config: Config): SparkJobValidation = ??? } |
l runJob 是job的具体实现部分。jobServer管理SparkContext,应用程序通过runJob方法获取SparkContext。这一特性使得用户从繁琐复杂的SparkContext创建以及管理工作中解脱出来,另外通过jobServer可实现对SparkContext的有效管理和复用。
l validate对context和所有提供的配置做一个最原始、最简单的有效性、正确性检查工作。如果context和配置符合job运行的条件,该函数返回的spark.jobserver.SparkJobValid将使对应的job执行,否则将返回spark.jobserver.SparkJobInvalid(reason)以阻止job运行并提示失败的原因。在这种情况下,该调用会立即返回HTTP/1.1 400 Bad Request状态码。validate能够帮助我们避免因为配置错误或者丢失的缘故而导致的job运行失败情况发生。
4 NewSparkJob API
注意:从0.7.0版本开始,一套新的更为优秀的SparkJob API将会取代原先旧版本的API。当前版本下的job仍需要用旧的spark.jobserver.SparkJob API来编译使用,但在不久的将来将会被遗弃。另外在0.7.0版本之前的job需要重新编译否则会与当前SJS例子相冲突。新版本的API如下所示:
| Object WordCountExampleNewApi extends NewSParkJob { type JobData = Seq[String] type JobOutput = collection.Map[String, Long]
def runJob(sc:SparkContext, runtime:JobEnvironment, data:JobData):JobOutput = sc.parallelize(data).countByValue
def validate(sc:SparkContext, runtime:JobEnvironment, config: Config): JobData Or Every[ValidationProblem] = { Try (config.getString(“input.String”).split(“”).toSeq) .map(words => Good(words)) .getOrElse(Bad(One(SingleProblem(“No input.string param”)))) } } |
与原先想比,类型安全性得到了提高,独立的context配置、job ID、命名对象和其他环
境变量被放置在一个独立的JobEnvironment中输入,并且允许validation方法为runJob方法返回特定的数据。具体可以参考WordCountExample和LongPiJob的例子。
下面尝试使用错误的配置来运行一个job:
| curl -i -d "bad.input=abc" 'localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample'
HTTP/1.1 400 Bad Request Server: spray-can/1.2.0 Date: Tue, 10 Jun 2014 22:07:18 GMT Content-Type: application/json; charset=UTF-8 Content-Length: 929
{ "status": "VALIDATION FAILED", "result": { "message": "No input.string config param", "errorClass": "java.lang.Throwable", "stack": ["spark.jobserver.JobManagerActor$$anonfun$spark$jobserver$JobManagerActor$$getJobFuture$4.apply(JobManagerActor.scala:212)", "scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24)", "scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24)", "akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:42)", "akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:386)", "scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)", "scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)", "scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)", "scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)"] } } |
4.1 依赖的jar包
我们可以同时对打包和上传依赖jar包做出配置。
l 最简单的方法就是使用例如sbt-assembly这样工具来产生一个较大的jar包。为使最终
的jar包不至于太大,确保Spark和job-server的依赖加上”provided”标签。
l 当依赖不是很多或者不希望job每次都需要重新加载依赖时,我们可以将依赖单独打包并且使用以下几种配置:
n 使用dependent-jar-uris context配置参数,每一个job都会去下载该jar包
n 在提交job的时候dependent-jar-uriscontext也可以用来设置job的配置参数。dependent-jar-uris context配置参数与ad-hoc context有着相同的作用。在一个长期运行着的context中jar包将会被当前运行的job所加载切任何一个job都会在的这个长期运行的context中执行。
|
|
/myjars/deps01.jar&/myjars/deps02.jar(只在SJS节点上有)将会被Sparkdriver&executors加载。
n 在server_start.sh脚本中使用和Maven组件相关的—package配置选项。
n 在SPARK_CLASSPATH中添加额外的依赖jar包
5 命名对象
5.1 使用命名RDD
在一开始,job server只支持命名的RDD,考虑到向后兼容性和方便性,仍然支持以下内容,即使现在可以使用下一节中所描述的更为通用的命名对象。
命名RDD是一种在job之间共享RDD的方法。在这种方式下,计算过的RDD可以有一个对应的名字并先缓存以便后续运算。要使用该特性,SparkJob需要继承混合NamedRddSupport特性:
object SampleNamedRDDJob extends SparkJob with NamedRddSupport { override def runJob(sc:SparkContext, jobConfig: Config): Any = ??? override def validate(sc:SparkContext, config: Config): SparkJobValidation = ??? } |
在接下来的job的实现内容中,RDD可以以一个对应名字的形式保存下来:
this.namedRdds.update("french_dictionary", frenchDictionaryRDD)
后续在同一个context中运行着的job可以检索获得并使用该RDD:
val rdd = this.namedRdds.get[(String, String)]("french_dictionary").get
(注意提供给get方法的指定类型,它将被允许强制转换检索出来的RDD,否则RDD为[_]类型)
对于依赖命名RDD的job来说,建议在如下所示的validate方法中检测对应的命名RDD是否存在:
def validate(sc:SparkContext, config: Config): SparkJobValidation = { ... val rdd = this.namedRdds.get[(Long, scala.Seq[String])]("dictionary") if (rdd.isDefined) SparkJobValid else SparkJobInvalid(s"Missing named RDD [dictionary]") } |
5.2 使用命名对象
命名对象用来更方便的在job中间共享RDD、DataFrames以及其他对象等。拥有该特性后,计算过的对象可以以名称储存并且在后续被检索出来。SparkJob需要混合NamedObjectSupport以支持该特性。此外还需要为每个所需类型的命名对象设置隐性的持久性。为方便起见,jobserver提供了RDD持久性和DataFrame持久性(在job-server-extras中定义)的实现。
object SampleNamedObjectJob extends SparkJob with NamedObjectSupport { implicit def rddPersister[T] : NamedObjectPersister[NamedRDD[T]] = new RDDPersister[T] implicit val dataFramePersister = new DataFramePersister override def runJob(sc:SparkContext, jobConfig: Config): Any = ??? override def validate(sc:SparkContext, config: Config): SparkJobValidation = ??? } |
在后续的job的实现中,RDD可以以具体名字来存储:
this.namedObjects.update("rdd:french_dictionary", NamedRDD(frenchDictionaryRDD, forceComputation = false, storageLevel = StorageLevel.NONE)) |
DataFrame可以像这样存储:
this.namedObjects.update("df:some df", NamedDataFrame(frenchDictionaryDF, forceComputation = false, storageLevel = StorageLevel.NONE)) |
建议对不同类型的对象使用不同的名称前缀,以避免混淆。
在同一个context中运行的job可以在后续以如下的方式检索和使用这些命名对象:
val NamedRDD(frenchDictionaryRDD, _ ,_) = namedObjects.get[NamedRDD[(String, String)]]("rdd:french_dictionary").get val NamedDataFrame(frenchDictionaryDF, _, _) = namedObjects.get[NamedDataFrame]("df:some df").get |
(注意提供给get方法的类型,这将允许将检索出的RDD/DataFrame对象转换为合适的结果类型。)
对于依赖于命名对象的job,最好在validate方法中检查对应的NamedObject是否存在,如前所述:
def validate(sc:SparkContext, config: Config): SparkJobValidation = { ... val obj = this.namedObjects.get("dictionary") if (obj.isDefined) SparkJobValid else SparkJobInvalid(s"Missing named object [dictionary]") } |
6 HTTPS/SSL配置
若要使用SSl通信,请在你的application.conf文件中设置如下标志
(spray.can.server一节):
|
你将需要一个包含服务器证书的密钥库。使用下面命令可以创建一个最小体积的自签名证书:
|
你可以将密钥库放置在任何位置,下面是一个使用ssl的简单curl命令:
|
|
-k标志告诉curl“允许链接到没有证书的SSL站点”。导出服务器证书并将其导入客户端的信任库以充分利用ssl的安全性。
7 身份验证
身份验证采用的是Apache Shiro框架,使用时需要设置以下标志内容(shiro一节):
|
Shiro特定的配置选项应当放置在由配置项config.path指定的目录下名为shiro.ini的文件中。下面给了一个用户组配置LDAP的例子:
|
确保根据你本地设置准确的编辑url、userDnTemplate、ladp.allowedGroups以及ldap.searchBase文件。
下面是一个简单curl命令的示例,验证用户并使用ssl(你可能会希望使用-H来隐藏用户凭据,这是一个很简单的入门示例):
|
8 配置
8.1 Context per JVM
当context-per-jvm设置成true时,通过manager_start.sh脚本使用spark-submit命令提交
后每个context都会变成一个单独的进程,用户可能想通过设置deploy.manager-start-cmd为正确的启动脚本路径并自定义脚本。当你想要同时运行多个context或者需要单独进程来运行的特定类型context例如StreamingContexts时,这种方式非常可取。
此外,额外的进程使用Akkacluster gossip协议通过随机端口来与主HTTP进程通信。如果因为某种原因单独的进程导致问题,设置spark.jobserver.context-per-jvm为false,这将会使所有的context使用单个相同的JVM。
在已知问题中:
已经加载启动的context不会自己关闭,需要用户手动的去kill每个进程,或者使用-X DELETE /contexts/,每个context的日志文件将会单独分开,存储在LOG_DIR目录的子目录中,LOG_DIR可在部署目录的settings.sh中配置(假设context-per-jvm 被设置成true)。
注意:若需要测试部署到本地临时目录或者打包job server成Mesos版本,请使用
bin/server_package.sh。
8.2 配置Spark JobServer meta data数据库后端
默认情况下使用H2数据库来存储于Spark JobServer相关的metadata,也可以自定义
其他方案。例如在local.conf中作如下配置就可使用PostgreSQL来作为存储后端,在确保你已经创建好具有授予用户必要权限的spark_jobserver数据库的前提下。
|
如果配置了context-per-jvm = true,确保将AUTO_MIXED_MODE添加到H2 JDBC URL中,可以使多个进程通过使用锁文件来共享同一个H2数据库。
并且在root级别添加以下行:
flway.locations=”b/postgresql/migration”另外需要将任何依赖的jar包添加至job Server的class path中。
8.3 Chef(厨师)
另外有一个Chef cookbook(厨师食谱)可用来部署Spark Jobserver。
9 框架和API
9.1 框架
Jobserver旨在作为一个或者多个独立的进程来运行,与spark集群相分离(虽然它与Master协同工作起来也很不错)。
咋一看,其中的许多功能(例如 job管理)可以被集成到Spark standalone master上。虽然这切实可行,但我们坚信有很多重要的原因让它们独立开来:
l 我们希望job server也能很好的为Mesos和YARN服务
l Spark和Mesos masters围绕着“application”或者context组织,但是job server能够支持在单一的context中运行多个离散的job。
l 我们希望在将来能够支持Shark功能。
l 解耦以允许灵活的HA布置(多个job server针对相同的standalone master或者可能的话让每个job server对应多个Spark 集群)
doc/子目录下保存着Flow图,.diagram文件可从websequencediagrams.com...中检测得到,它真的会帮助你理解演员之间的小溪流。
9.2 API
9.2.1 二进制文件
|
在POST新的二进制文件时,内容类型头必须被设置成BinaryType trait子类所支持的类型,例如"application/java-archive"或 application/python-archive"。
9.2.2 Jars(已弃用)
|
由于历史原因,这些API被保留了下来,但为了支持/binaries被弃用了
9.2.3 Contexts
|
Spark context配置参数可跟随者POST /contexts/
9.2.4 Jobs
提交至job server的job必须实现了SparkJob trait,它有一个主要的runJob方法,将会传递一个SparkContext和一个类型安全的Config对象,该方法返回的结果可通过REST API来获取。
|
有关于Typesafe配置的输入格式(支持JSON)的更多细节,参考Typesafe Config docs。
9.2.5 Data
有时候需要以编程方式将文件上传至服务端,使用下列路径来管理此类文件:
|
这些文件被上传到了服务端并保存在JobServer运行设备上的一个本地目录下。POST命令返回上传文件的完整路径名和文件名,以便后续的job可以像操作服务器本地文件一般的操作它们。Job能够将这个文件添加至HDFS或者通过SparkContext.addFile。若文件大于上百MB的话,建议手动上传至服务端而不是直接添加到HDFS中。
(1) Data API Example
| $ curl -d "Test data file api" http://localhost:8090/data/test_data_file_upload.txt { "result": { "filename": "/tmp/spark-jobserver/upload/test_data_file_upload.txt-2016-07-04T09_09_57.928+05_30.dat" } }
$ curl http://localhost:8090/data ["/tmp/spark-jobserver/upload/test_data_file_upload.txt-2016-07-04T09_09_57.928+05_30.dat"]
$ curl -X DELETE http://localhost:8090/data/%2Ftmp%2Fspark-jobserver%2Fupload%2Ftest_data_file_upload.txt-2016-07-04T09_09_57.928%2B05_30.dat OK
$ curl http://localhost:8090/data [] |
注意:POST和DELETE都会采用URI编码的文件名。
10 Context配置
在创建context(POST/contexts)或者运行一个ad-hoc job(即席创建context)时,可以
控制许多context-specific的配置。例如,为context添加依赖jar包的url。
|
注意:只是最新的dependent-jar-uris(是jar-uris而不是jar-uri)有效,用户可以通过逗号来分隔指定的多个uri,比如:
|
通过POST /contexts来创建context时,查询参数用来覆盖spark.context-settings中的默认配置,例如:
|
这将会覆盖spark.context-settings 中num-cpu-cores的默认配置。
当启动job时未指定context=时,一个ad-hoc的context会自动创建。Spark.context-settings中指定的任何设置将会覆盖对应的job server中配置的默认值。
任何spark配置参数可以在post /context查询参数或者通过spark.context-settings job配置来覆盖,另外,num-cpu-cores被映射成了spark.cores.max,mem-per-node映射成了spark.executor.memory,因此下面这种表示是等价的:
|
或在使用POST /jobs时的job配置:
|
已通过Kerberos验证的用户的用户模拟通过spark.proxy.user查询参数支持:
| POST /contexts/my-new-context?spark.proxy.user= |
但是,只要shiro.use-as-proxy-user标志被设置为on(并且authentication也为on)就会忽略该参数,并且在创建context时始终将经过身份验证的用户的用户名作为参数spark.proxy.user的值。
若需要将配置直接传递给sparkConf而不使用带”as-is”前缀的“spark”,请使用“passthrough”部分。
|
若需要在Spark context中添加底层的Hadoop配置,只需要在context配置中增加“hadoop”部分即可。
|
更准确的context配置参数信息请参考JobManagerActor文档和application.conf配置文件,也可参阅yarn doc。
10.1 其他配置
若想研究学习所有的Spark Job Server配置,参阅
job-server/src/main/resources/application.conf配置文件。
11 Job 返回结果序列化
SparkJob runJob方法的返回结果被job server序列化后转换为JSON字符串组成的
Rest路由(GET /jobs with sync=true, GET /jobs/)。目前下列类型能够被合理的序列化:
l String、Int、Long、Double、Float、Boolean
l Scala Map KV键值对(非String key会被转换为String)
l Scala Seq
l Array数组
l 任何实现了Product(Option、case类)--将会被转换为list列表
l Java.util.List的子类
l 具有String类型Key的java.util.Map的子类(非String key会被转换为String)
l Map、Seq、java Map和java List和可能包含以上内容的嵌套类型
l 若一个job的返回值是scala的Stream[Byte],它将会被直接序列化为块编码流。如果job的返回结果很大导致序列化耗时超时的话,使用这种返回方式很有用。注意,目前不支持context-per-jvm=true配置,因为需要在进程之间序列化Stream[_] bolb,所以需要将context-per-jvm设置为false,这个也是未来优化的方向之一。
另外遇到哪些不支持的类型,整个结果将会转换为字符串。
12 当前环境下的配置与使用
这里的内容不会涉及到具体的代码结构以及代码,主要讲解的是在当前环境下jobserver
的使用步骤、使用方法以及个人的一些理解。
集群环境为20.2.37.210、20.2.37.212、20.2.37.214,在这三台上都部署了spark job server服务,下面的一系列操作是在212上进行的。
12.1 系统配置
Jobserver的所有配置都可以参照官网上推荐的application.conf文件。具体路径(源码):
spark-jobserver/job-server/src/main/resources/application.conf。
实际运行环境中的配置文件可能会有些许不同,这里就介绍下实际运行环境下的配置文件,Application.conf在需要的时候可以详细研究一下。
| # Template for a Spark Job Server configuration file # When deployed these settings are loaded when job server starts # # Spark Cluster / Job Server configuration spark { # spark.master will be passed to each job's JobContext #master = "local[4]" # master = "mesos://vm28-hulk-pub:5050" master = "yarn-client" #yarn集群模式,只有yarn-client一种
# Default of CPUs for jobs to use for Spark standalone cluster job-number-cpus = 4
jobserver { port = 8090 jar-store-rootdir = /tmp/jobserver/jars
context-per-jvm = false
jobdao = spark.jobserver.io.JobFileDAO
# Automatically load a set of jars at startup time. Key is the appName, value is the path/URL. 设置一个jar目录,在每次启动的时候都会自动去加载 job-binary-paths { WL = /home/spark-jobserver/VehicleFootHold-assembly-1.0.jar }
filedao { rootdir = /tmp/spark-job-server/filedao/data }
# When using chunked transfer encoding with scala Stream job results, this is the size of each chunk result-chunk-size = 1m }
# predefined Spark contexts # contexts { # my-low-latency-context { # num-cpu-cores = 1 # Number of cores to allocate. Required. # memory-per-node = 512m # Executor memory per node, -Xmx style eg 512m, 1G, etc. # } # # define additional contexts here # }
# universal context configuration. These settings can be overridden, see README.md 配置全局的context参数,可以被覆盖 context-settings { num-cpu-cores = 24 # Number of cores to allocate. Required. memory-per-node = 16G # Executor memory per node, -Xmx style eg 512m, #1G, etc.
# in case spark distribution should be accessed from HDFS (as opposed to being installed on every mesos slave) # spark.executor.uri = "hdfs://namenode:8020/apps/spark/spark.tgz"
# uris of jars to be loaded into the classpath for this context. Uris is a string list, or a string separated by commas ',' # dependent-jar-uris = ["file:///some/path/present/in/each/mesos/slave/somepackage.jar"]
# If you wish to pass any settings directly to the sparkConf as-is, add them here in passthrough, # such as hadoop connection settings that don't use the "spark." prefix passthrough { #es.nodes = "192.1.1.1" } }
# This needs to match SPARK_HOME for cluster SparkContexts to be created successfully home = "/home/spark/spark" }
# Note that you can use this file to define settings not only for job server, # but for your Spark jobs as well. Spark job configuration merges with this configuration file as defaults.
akka { remote.netty.tcp { # This controls the maximum message size, including job results, that can be sent # maximum-frame-size = 10 MiB } }
# check the reference.conf in spray-can/src/main/resources for all defined settings spray.can.server { # Increase this in order to upload bigger job jars 这个配置限定了上传jar包的大小,默认是30m parsing.max-content-length = 100m } |
12.2 使用步骤
这里建议在windows上使用restclient REST工具来进行操作而不是官网上推荐的在linux端使用curl工具进行操作。
(1) 上传编译好的jar包
| URL: http://20.2.37.212:8090/jars/13 操作类型: POST Body类型: file body File类型: application/x-www-form-urlencoded; charset=UTF-8 返回值: OK(成功)或者具体错误 |

另外需要对应的jar包路径,上传至服务器的jar包会保存在jars/目录下,对应名称为13,如下图所示:

(2) 创建context
这一步是可选操作,如果不建立的话,系统会默认建立一个context,后面会作介绍。
用户手动建立context的话可进行多种参数配置,一旦建立好之后,context就会以服务的形式存在不会停止,除非用户手动kill。

| URL:http://172.6.3.146:8090/contexts/my-new-context?spark.executor.cores=2&spark.executor.instances=2&spark.executor.memory=1G&spark.driver.memory=1G 操作类型: POST Body类型: string body String类型: text/plain; charset=UTF-8 返回值: OK(成功)或者具体错误 具体配置参数直接在URL中指明 |

新的context以服务的形式长期存在,供用户提交任务时使用。

任务若使用该context,则会生成对应的一个个的job,所有job执行完毕,任务结束,该context处于运行状态。
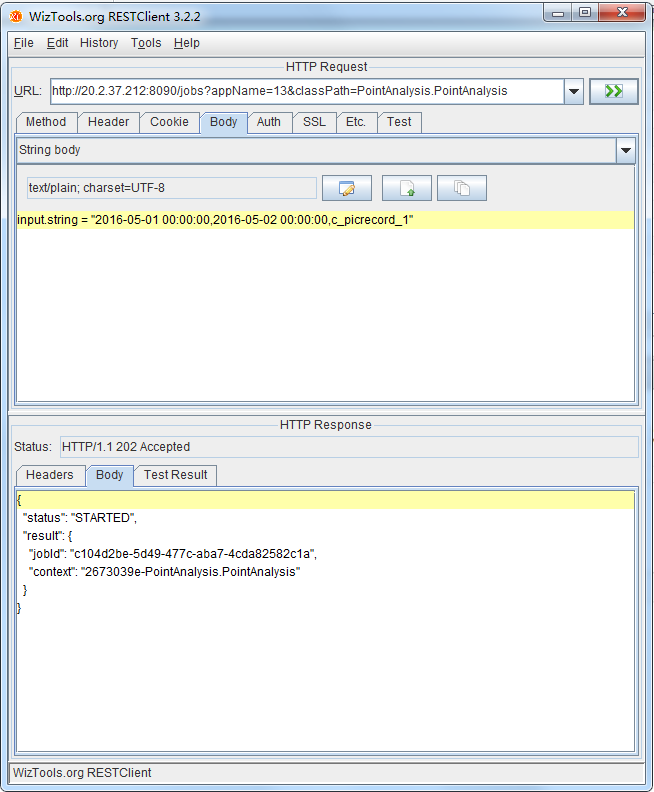
(3) 提交任务(共享context)
这里使用预建立的context即共享context。

| URL: http://20.2.37.212:8090/jobs?appName=13&classPath=PointAnalysis.PointAnalysis&context=my-new-context URL解析: appName: 刚才所上传的jar包的名字 classPath: jar包中对应的类名 context: 要使用的context 操作类型: POST Body类型: String body String类型: text/plain; charset=UTF-8 input.string = "2016-05-01 00:00:00,2016-05-02 00:00:00,浙BP0655,c_picrecord_1,1",这个是入参,在代码中validate函数会进行一些简单的合法性检测。 返回值: 正确的话如下: { "status": "STARTED", "result": { "jobId": " 08c261b1-153b-400f-bf10-401f46a5f6b7", "context": "my-new-context" } } 否则会返回具体错误信息。 |
用户提交的Job已经在指定的context上运行了,可通过restclient或者jobserver webui来获知job的实时状态。
(4)获取job结果
Job正常运行完之后,可以获取执行结果。

| URL: http://20.2.37.212:8090/jobs/08c261b1-153b-400f-bf10-401f46a5f6b7 Jobs后面的一串字符指的是jobId。 操作类型: GET Body类型: 无 返回值: job运行结果字符串,如上图所示 |
在jobserver的webui上也可以查看每个job的执行状态和执行结果,直接点击jobId即可,jobId末尾的(c)表示的是入参。

(5)提交job(不适用共享context)
提交任务时不指明context,系统会默认创建一个context,job执行完毕后,context
随之结束。
| URL: http://20.2.37.212:8090/jobs?appName=13&classPath=PointAnalysis.PointAnalysis URL解析: appName: 之前上传的jar名称 classPath: jar包中对应的类名 操作类型: POST Body类型: String body String类型: text/plain; charset=UTF-8 input.string = "2016-05-01 00:00:00,2016-05-02 00:00:00,浙BP0655,c_picrecord_1,1" 这个是入参,在代码中validate函数会进行一些简单的合法性检测。 返回值:正确的话如下: { "status": "STARTED", "result": { "jobId": "45c41de2-5ea7-4a7d-b186-0ddb51e334d0", "context": "68a99781-PointAnalysis.PointAnalysis" } } 否则会返回具体错误信息。 |
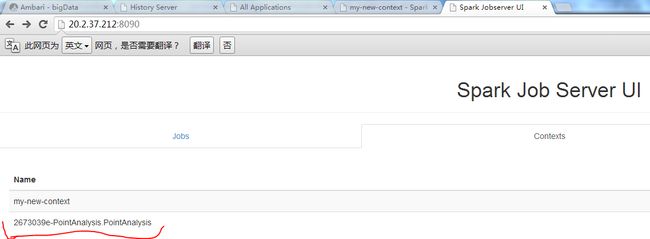
系统会建立一个临时的context。

如上图所示,默认建立的job执行完就结束了,context也随之结束。
总结,涉及到的rest操作还有很多,这里只选取了最主要的几种进行介绍,后续的话该文档还会持续更新。
12.3 个人理解
12.3.1 总体理解
Spark程序在运行时启动时间和环境的初始化时间会很长,而且这部分时间不能避免,
这对spark程序的性能有很大的影响;另外每个spark程序的driver都会起一个spark context来作为spark程序运行的上下文环境。
每次执行spark程序时都需要有context,在一个大数据处理框架中,每次用到的context可能都是类似的,如果每次都去创建context会造成资源的极大浪费以及性能的损耗,而jobserver的作用恰恰在此,该框架使得spark变成了一个服务来运行,我们可以在通过rest接口来对job和context管理,其中对于context和RDD的共享和复用极大的提高了资源利用效率、加快spark job的执行速度,避免了多余繁重的context构建,使得spark框架更好的为计算服务。
综上,建议使用sparkjobserver时应当预先建立好合适的context,使用共享context来完成job,尽可能的发挥jobserver的技术优势。
12.3.2 代码细节
这里以一个官网的例子来简单介绍下spark jobserver的代码框架使用细节:
| package spark.jobserver
import com.typesafe.config.{Config, ConfigFactory} import org.apache.spark._ import org.apache.spark.SparkContext._ import scala.util.Try
/** * A super-simple Spark job example that implements the SparkJob trait and can be submitted to the job server. * * Set the config with the sentence to split or count: * input.string = "adsfasdf asdkf safksf a sdfa" * * validate() returns SparkJobInvalid if there is no input.string */ object WordCountExample extends SparkJob { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local[4]").setAppName("WordCountExample") val sc = new SparkContext(conf) val config = ConfigFactory.parseString("") val results = runJob(sc, config) println("Result is " + results) }
override def validate(sc: SparkContext, config: Config): SparkJobValidation = { Try(config.getString("input.string")) .map(x => SparkJobValid) .getOrElse(SparkJobInvalid("No input.string config param")) }
override def runJob(sc: SparkContext, config: Config): Any = { sc.parallelize(config.getString("input.string").split(" ").toSeq).countByValue "hello world" } } |
如上所示,WordCountExample类继承了SparkJob并实现了validate和runJob方法,其中validate方法是用来对入参进行最简单的判断的;runJob是spark 程序的主函数部分,实现原先由main函数实现的功能,注意:runJob可以返回任意内容。
由实践可知,在使用sparkjobserver框架运行spark job时,代码中可以将validate省略(不做任何可靠性检测),对功能没有任何影响。
main函数的主要作用是用在local本地模式下进行代码调试运行时使用,使用方法与普通spark jar包一致(通过spark submit命令提交运行),这样同一份代码无需修改既可在本地调试也可上传至job server服务器上运行。
13 附录
Jobserver官网:
https://github.com/spark-jobserver/