使用爬虫爬取豆瓣2016电影榜单中所有电影
更多技术文章请访问我的个人博客http://www.rain1024.com
爬虫每日篇—-今天使用爬虫爬取豆瓣2016电影榜上所有电影信息,本来以为豆瓣这种大社区的防御做的会很好,看到是HTTPS协议,我都准备写一大串头部去模拟用户了,没想到一个urlopen就直接获取了,可能是网站设计者故意没做的很封闭,让我有机可乘。这是网址(https://www.douban.com/doulist/3516235/?start=0&sort=seq&sub_type=),大家可以先看看。

如图,这就是网页的基本情况,大家可以先去看看网页源代码,我现在要做的就是把每个电影的整个提取出来,代码直接用urlopen弄了出来,我先保存到一个文件里,要慢慢的测试,直接用文件里的代码就可以了,省得每次都抓取页面。
# -*- coding: utf-8 -*-
import urllib2
import re
from bs4 import BeautifulSoup
def get_html(url):
result = urllib2.urlopen(url)
return result.read()
def save_file(text, filename):
f= open(filename,'w')
f.write(text)
f.close()
def read_file(filename):
f = open(filename,'r')
text = f.read()
f.close()
return text
if __name__=='__main__':
url = 'https://www.douban.com/doulist/3516235/'
html = get_html(url)
save_file(html,'thefile.txt')下一步对抓取的代码开始提取,每个电影的介绍都包含在一对div中
使用BeautifulSoup来提取
html = read_file('thefile.txt')
soup = BeautifulSoup(html)
text = soup.find_all('div', class_='bd doulist-subject')
save_file(str(text),'thefile.txt')效果如下图
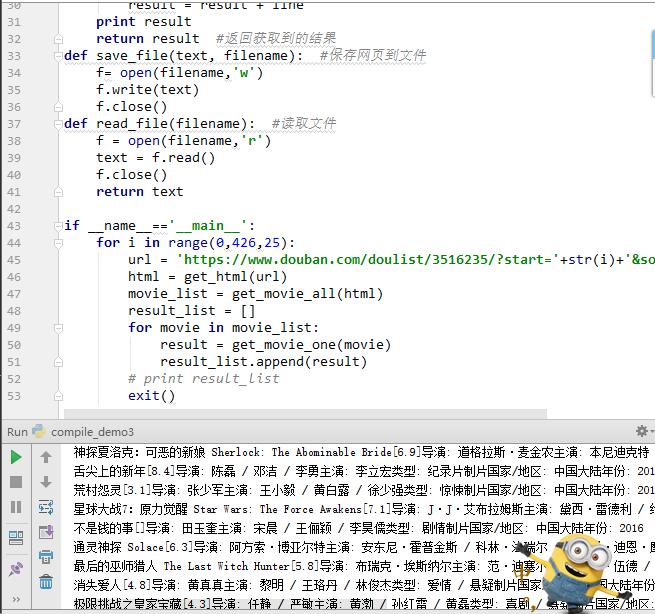
每个电影的信息都提取出来了,我想要的是电影的名称,评分,人员,上映日期,所以我只提取这些内容,大家可以按照自己的需求写。
def get_movie_one(movie):
result = []
soup_all = BeautifulSoup(str(movie))
title = soup_all.find_all('div', class_='title')
soup_title = BeautifulSoup(str(title[0]))
for line in soup_title.stripped_strings: # 对获取到的里的内容进行提取
print line
num = soup_all.find_all('span', class_='rating_nums')
print num[0].contents[0]
info = soup_all.find_all('div', class_='abstract')
soup_info = BeautifulSoup(str(info[0]))
for line in soup_info.stripped_strings: # 对获取到的里的内容进行提取
print line
## 结果:
一切都好
6.4
导演: 张猛
主演: 张国立 / 姚晨 / 窦骁
类型: 剧情 / 家庭
制片国家/地区: 中国大陆
年份: 2016第一个已经成功了,现在就开始批量的操作,一共有425个电影,我每提取一个就存到文件里,这是第一页25个电影提取出来的效果。

下面是全部的代码,大家可以参考一下。
#!/usr/bin/env python
# -*- coding=utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
import re
import time
from bs4 import BeautifulSoup
def get_html(url): #通过url获取网页内容
result = urllib2.urlopen(url)
return result.read()
# save_file(result.read(), 'thefile.txt')
def get_movie_all(html): #通过soup提取到每个电影的全部信息,以list返回
soup = BeautifulSoup(html)
movie_list = soup.find_all('div', class_='bd doulist-subject')
return movie_list
def get_movie_one(movie):
result = [] # 用于存储提取出来的电影信息
soup_all = BeautifulSoup(str(movie))
title = soup_all.find_all('div', class_='title')
soup_title = BeautifulSoup(str(title[0]))
for line in soup_title.stripped_strings: # 对获取到的里的内容进行提取
result.append(line)
# num = soup_all.find_all('span', class_='rating_nums')
num = soup_all.find_all('span')
result.append(num[1].contents[0])
soup_num = BeautifulSoup(str(num[0]))
for line in soup_num.stripped_strings: # 对获取到的里的内容进行提取
result = result + line
info = soup_all.find_all('div', class_='abstract')
soup_info = BeautifulSoup(str(info[0]))
result_str = ""
for line in soup_info.stripped_strings: # 对获取到的里的内容进行提取
result_str = result_str + line
result.append(result_str)
return result #返回获取到的结果
def save_file(text, filename): #保存网页到文件
f= open(filename,'ab')
f.write(text)
f.close()
def read_file(filename): #读取文件
f = open(filename,'r')
text = f.read()
f.close()
return text
if __name__=='__main__':
for i in range(0,426,25):
url = 'https://www.douban.com/doulist/3516235/?start='+str(i)+'&sort=seq&sub_type='
html = get_html(url)
movie_list = get_movie_all(html)
for movie in movie_list: #将每一页中的每个电影信息放入函数中提取
result = get_movie_one(movie)
text = ''+'电影名:'+str(result[0])+' | 评分:'+str(result[1])+' | '+str(result[2])+'\n'+'\t'
save_file(text,'thee.txt')
time.sleep(5) #每隔5秒抓取一页的信息
更多技术文章请访问我的个人博客http://www.rain1024.com
提取出来,代码直接用urlopen弄了出来,我先保存到一个文件里,要慢慢的测试,直接用文件里的代码就可以了,省得每次都抓取页面。
下一步对抓取的代码开始提取,每个电影的介绍都包含在一对div中
# -*- coding: utf-8 -*-
import urllib2
import re
from bs4 import BeautifulSoup
def get_html(url):
result = urllib2.urlopen(url)
return result.read()
def save_file(text, filename):
f= open(filename,'w')
f.write(text)
f.close()
def read_file(filename):
f = open(filename,'r')
text = f.read()
f.close()
return text
if __name__=='__main__':
url = 'https://www.douban.com/doulist/3516235/'
html = get_html(url)
save_file(html,'thefile.txt')下一步对抓取的代码开始提取,每个电影的介绍都包含在一对div中
使用BeautifulSoup来提取
html = read_file('thefile.txt')
soup = BeautifulSoup(html)
text = soup.find_all('div', class_='bd doulist-subject')
save_file(str(text),'thefile.txt')效果如下图
每个电影的信息都提取出来了,我想要的是电影的名称,评分,人员,上映日期,所以我只提取这些内容,大家可以按照自己的需求写。
def get_movie_one(movie):
result = []
soup_all = BeautifulSoup(str(movie))
title = soup_all.find_all('div', class_='title')
soup_title = BeautifulSoup(str(title[0]))
for line in soup_title.stripped_strings: # 对获取到的里的内容进行提取
print line
num = soup_all.find_all('span', class_='rating_nums')
print num[0].contents[0]
info = soup_all.find_all('div', class_='abstract')
soup_info = BeautifulSoup(str(info[0]))
for line in soup_info.stripped_strings: # 对获取到的里的内容进行提取
print line
## 结果:
一切都好
6.4
导演: 张猛
主演: 张国立 / 姚晨 / 窦骁
类型: 剧情 / 家庭
制片国家/地区: 中国大陆
年份: 2016第一个已经成功了,现在就开始批量的操作,一共有425个电影,我每提取一个就存到文件里,这是第一页25个电影提取出来的效果。
下面是全部的代码,大家可以参考一下。
#!/usr/bin/env python
# -*- coding=utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
import re
import time
from bs4 import BeautifulSoup
def get_html(url): #通过url获取网页内容
result = urllib2.urlopen(url)
return result.read()
# save_file(result.read(), 'thefile.txt')
def get_movie_all(html): #通过soup提取到每个电影的全部信息,以list返回
soup = BeautifulSoup(html)
movie_list = soup.find_all('div', class_='bd doulist-subject')
return movie_list
def get_movie_one(movie):
result = [] # 用于存储提取出来的电影信息
soup_all = BeautifulSoup(str(movie))
title = soup_all.find_all('div', class_='title')
soup_title = BeautifulSoup(str(title[0]))
for line in soup_title.stripped_strings: # 对获取到的里的内容进行提取
result.append(line)
# num = soup_all.find_all('span', class_='rating_nums')
num = soup_all.find_all('span')
result.append(num[1].contents[0])
soup_num = BeautifulSoup(str(num[0]))
for line in soup_num.stripped_strings: # 对获取到的里的内容进行提取
result = result + line
info = soup_all.find_all('div', class_='abstract')
soup_info = BeautifulSoup(str(info[0]))
result_str = ""
for line in soup_info.stripped_strings: # 对获取到的里的内容进行提取
result_str = result_str + line
result.append(result_str)
return result #返回获取到的结果
def save_file(text, filename): #保存网页到文件
f= open(filename,'ab')
f.write(text)
f.close()
def read_file(filename): #读取文件
f = open(filename,'r')
text = f.read()
f.close()
return text
if __name__=='__main__':
for i in range(0,426,25):
url = 'https://www.douban.com/doulist/3516235/?start='+str(i)+'&sort=seq&sub_type='
html = get_html(url)
movie_list = get_movie_all(html)
for movie in movie_list: #将每一页中的每个电影信息放入函数中提取
result = get_movie_one(movie)
text = ''+'电影名:'+str(result[0])+' | 评分:'+str(result[1])+' | '+str(result[2])+'\n'+'\t'
save_file(text,'thee.txt')
time.sleep(5) #每隔5秒抓取一页的信息
更多技术文章请访问我的个人博客http://www.rain1024.com