Vivado Hls 设计分析
概叙设计方法:
- 综合设计
- 回顾最初的结果
- 应用优化的 directives去提高效率
你可以重复上述步骤,直到达到要求。然后,你可以重新审查设计去提高面积。此过程的关键部分是分析结果,下面通过一个project来介绍如何使用reports和 GUI perspective 去分析设计,并且决定用哪种solution去应用相应的优化。
directive简介
创建solution时,directive分为两种:
directive前面如果是”%“的话,说明存放于单独的 directive.tcl文件里,此时就是一个tcl.command,
优点:
1). 每个solution都有独立的directive
2). 如果这个solution需要重新综合,那么只有这个solution下面的directive会起到作用缺点:
1). 如果我们想把C source code 给到第三方工具,相应的directive也要被包含其中
2). 如果我们需要获得同样的C综合后的结果,也必须有相应的directivedirective前面如果是”#“的话,说明存放于相应的source file,此时会以“#pragma“形式在source code里显示,
优点:
我们在使用第三方工具时,只需要把C source code给过去就可以重现综合后的结果
缺点:
1).如果这个solution需要重新综合,由于directive写在source code里,这时候所有的directive都会被执行
2).如果把相应的 directive存放到C/C++的代码里,就不能从另外一个solution里copy过来,同时也不便于 directives的管理。
注意:在C代码的里,如果有for loop,最好给这个loop写一个标签,可以方便我们找到这个for循环,对其做相应的优化的时候可以很容易识别出来。
不同soluotion的对比
下面开门见山,直奔主题,通过一个project介绍 directives的神奇之处,在这里先定下一个interval为125 clock的小目标
Solution1:
step1 打开Vivado Hls
1.在 command 里写入vivado_hls–f run_hls.tcl,如下图

2.再在 command 里写入vivado_hls –p dct_prj
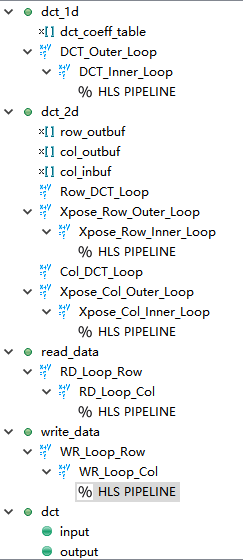
step2 查看source code结构
step3 C synthesis
点击C synthesis,得到report:
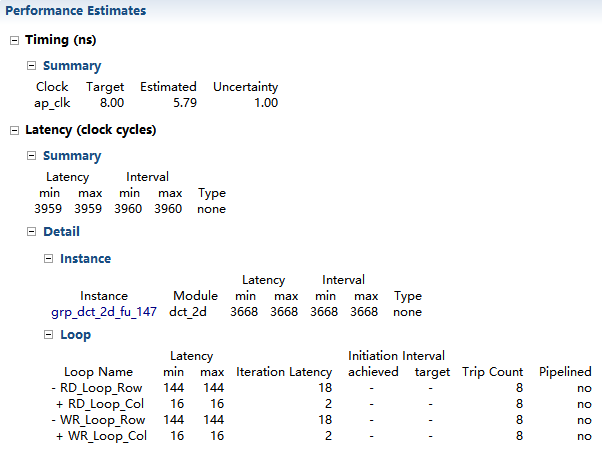
这里注意到:
• 时钟频率的 8 ns 得到满足。
• 顶层设计需要 3959 时钟周期去完成所有输出。
• 3960个时钟周期后,你可以进行新的输入。注意这里,输出数据写入后,还需要有一个时钟周期。
• 顶层只有一个instance, 它的 latency 和 initiation interval 为 3668,此block也没有流水线和占了绝大部分的时钟周期。
• 所有loop的pipelined类型设置为 no ,可以看出这也没有流水线
step4 使用Analysis 窗口
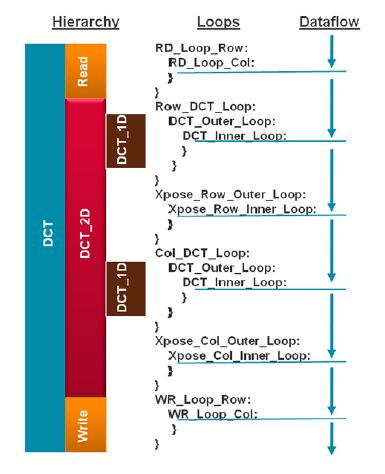
1.打开Analysis 窗口,展开dct下面的loop
2.打开dct_2d,展开下面的loop
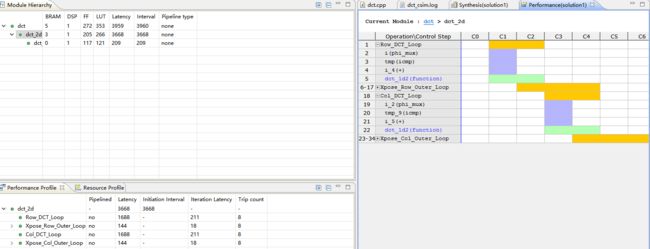
loop虽然可以减小面积,但是设计会使用多重迭代状态去完成设计。在这里,大部分latency是由Row_DCT_Loop 和Col_DCT_Lo造成的,
3.打开dct_1d2,展开下面的loop
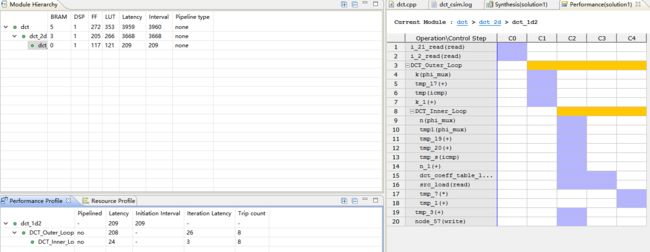
发现有许多loops可以被pipelined
此时你可以:
1)pipeline函数,然后pipeline loops
2)pipeline 带有函数的loops,可以简单的使函数执行的更快
注意:pipeline函数会展开所有的loops,这样就会大大增加面积。
Solution2:
在directive里应用loop pipeline
1.回到systhesis界面,创建solution2,给DCT_Inner_Loop插入Directive,选择pipeline
2.给下列 loops重复上述操作,如下图:
a. In function dct_2d loop Xpose_Row_Inner_Loop
b. In function dct_2d loop Xpose_Col_Inner_Loop
c. In function read_data loop RD_Loop_Col
d. In function write_data loop WR_Loop_Col
3.然后点击systhesis,将综合后的report与solution1比较
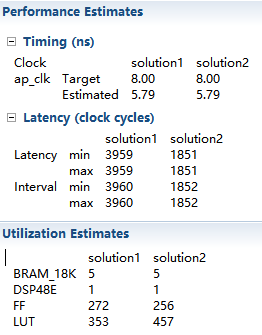
发现这里的latency和interval都比原来小了一半多,也就意味着数据吞吐率提高了一倍多。
4.打开analyse窗口,在Module Hierarchy中点开dct_2d
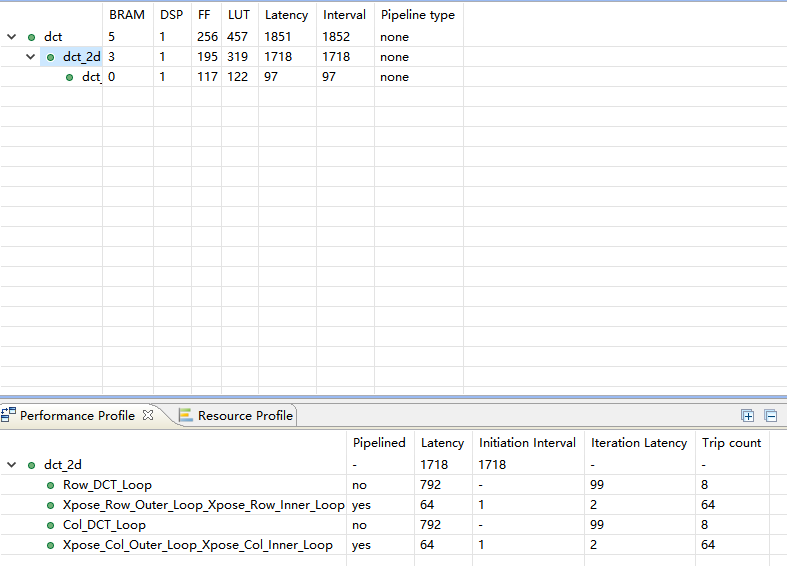
我们可以看到,latency主要是由dct_2d造成的,dct_2d的里latency主要是因为Row_DCT_Loop和Col_DCT_Loop,下面打开dct_1d2

我们发现,DCT_Outer_Loop没有被pipelined,而latency主要就是因为DCT_Outer_Loop
5.进一步分析DCT_Outer_Loop没有被pipelined的原因,打开右边performance和Resource窗口
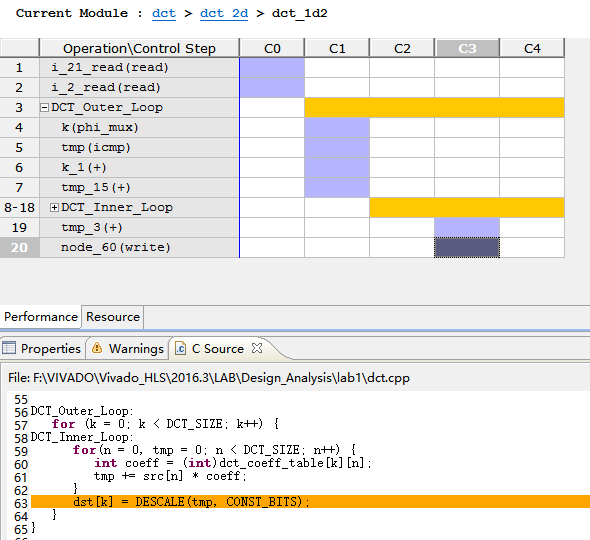
我们发现,加法计数操作在DCT_Inner_Loop的外面,就会阻止loop被flatten,在这里,node 60(write)对应c source里的突出部分,也在DCT_Inner_Loop的外面,因而write不能被flatten进入DCT_Inner_Loop,因此我们需要对DCT_Outer_Loop进行pipeline
Solution3:
1.回到systhesis界面,创建solution3,移除DCT_Inner_Loop的Directive,给DCT_Outer_Loop插入Directive,选择pipeline,其它不变,然后点击C synthesis,将得到的report和solution2比较:
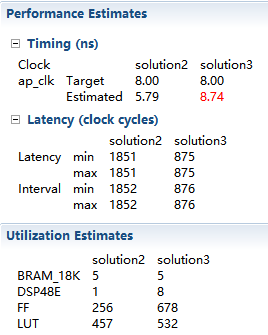
在这里,latency减小了一半多,但是相对应所利用的资源也增加了。同时,显示solution3的时钟周期不能被满足,不过没关系,通常来说,RTL systhesis后的设计都是符合timing,你可以利用Export RTL的特点并选择Evaluate验证它。
2.打开Analysis窗口,进入dct_1d2
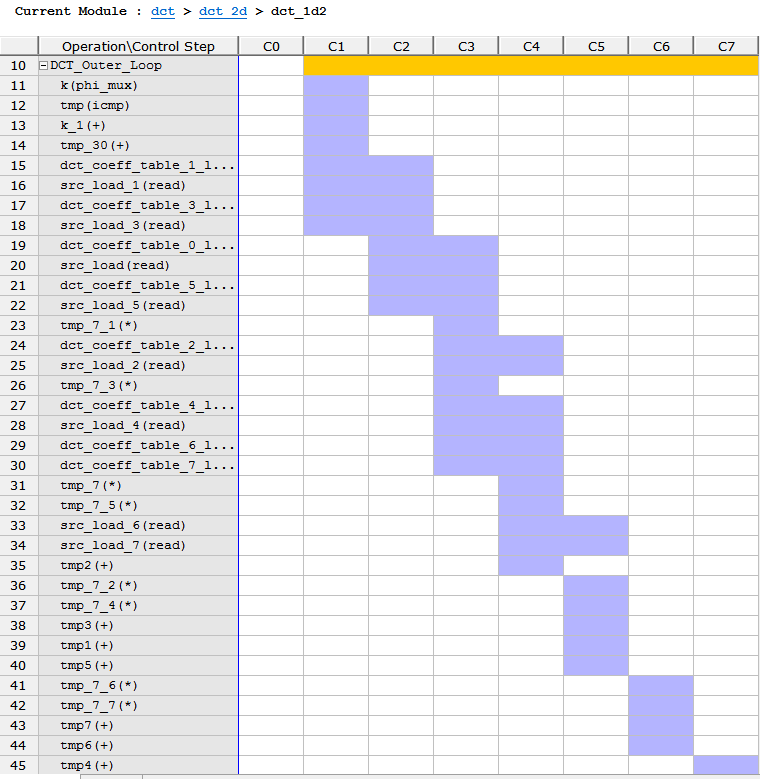
在这里,我们发现了不同点,这里的latency很多,从输入到输出有很多drift,造成这样的原因,一个是因为源代码中数据依赖关系,一个是因为I/O或者RAM block的限制
3.下面检测block中的resource sharing,打开右下角的Resource
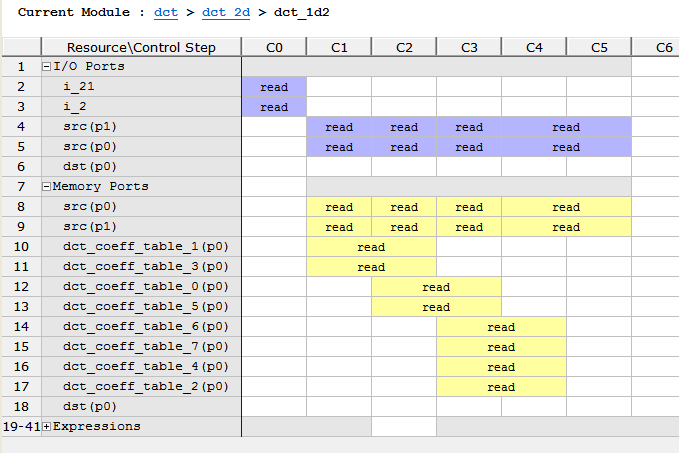
Resource显示的是设计中的resource是如何被利用到不同的控制模块的。图中,我们发现,block RAM src在每个时钟都被使用到了,解决的办法就是,使用partition directive去优化block RAM。这里通过 对dct_1d的输入数组进行partition,去让数据并行处理:
• instance dct_1d 的 第一个输入数组函数 dct里面的buf_2d_in .
• instance dct_1d 的第二个输入数组是函数dct_2d里面的 col_inbuf .
Solution4:
1.回到systhesis界面,创建solution4,给buf_2d_in插入Directive,选择ARRAY_PARTITION,type设为Complete,dimension设为2,点击OK
2.重复对col_inbuf操作,其它不变,点击C synthesis,然后将综合得到的report和solution3比较:
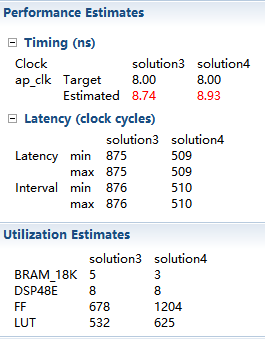
这里提供提高dct_1d里src block RAM 的数据吞吐率,使得dct_1d频繁执行,显著提高了整体性能
3点开Analysis窗口,在Module Hierarchy选中dct,再点击左下角的Resource Profile标签
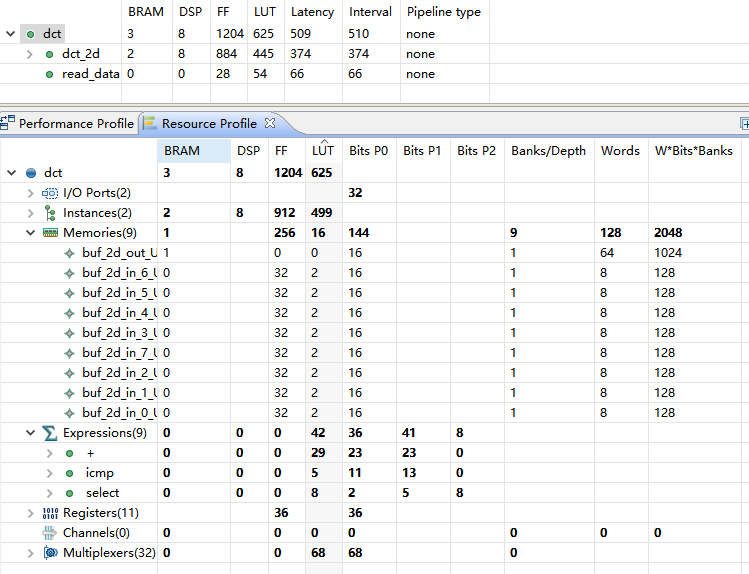
图中显示:
• 此模块有两个I/O端口.
• 此模块大部分区域是Instances
• 这里有九个memories,其中八个是被partition后的buf_2d_in block RAm,因为它们都少于1024 bits,并且在LUTRAM中自动执行
• 大部分逻辑是加法,有一些比较器和选择器
为了进一步降低每个独立loop的latency和interval,现在必须使用dataflow directive优化,它能使地理loop和函数并行执行,这样就能显著提高整体设计interval
Solution5:
1.回到systhesis界面,创建solution5,给顶层函数dct插入Directive,选择DATAFOLW,点击Ok,其它不变,点击C synthesis,然后将综合得到的report和solution4比较:

这里得到的interval跟要求的125相差甚远,因此必须分享当前performance
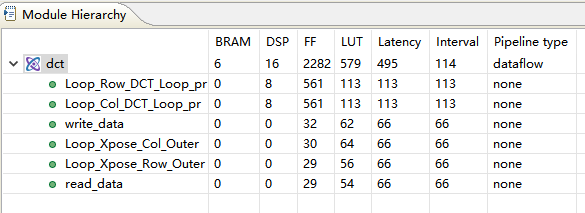
2.点击Analysis窗口,进入Module Hierarchy
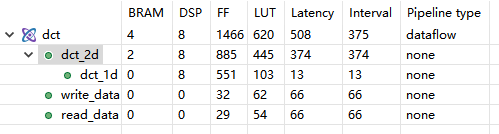
图中:
• dct block的interval是小于individual latencies (即r
read_data, dct_2d和write_data),这说明blocks是并行操作的
• dct block的interval跟sub-block dct_2d相同,因此sub-block dct_2d是限制因素
解决方法:一个是pipeline整个函数让dct_2d中所有模块并行操作,这会unroll所有的loops,导致面积大大增加。另一个是通过对 dct_2d函数进行inline directive,将loops提到顶层hierarchy,这样他们就包含在顶层的dataflow优化中。
Solution6:
1.回到systhesis界面,创建solution6,给dct_2d插入Directive,选择INLINE,点击Ok,其它不变,点击C synthesis,然后将综合得到的report和solution5比较:
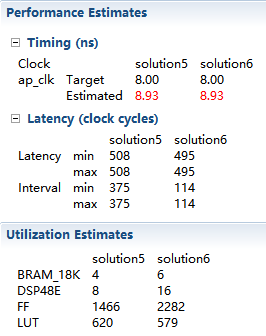 、
、
发现这里的interval小于125时钟目标了,达到了114!
总结
在这里介绍了如何使用analysis 窗口去分析一个设计,怎样判断和应用directives去减少latency和interval