破解猫眼动态加载的票房数据
破解猫眼电影网动态加载的票房、观看人数数据
- **一、先交代下前事**
- 二、具体的分析
一、先交代下前事
先交代下背景,这次我们要爬的网站是猫眼,尽管猫眼电影网是一个静态网页,没有Ajax动态加载那些七七八八复杂的操作,但猫眼电影里有一项数据是相对其他而言比较难获取到的,比方下面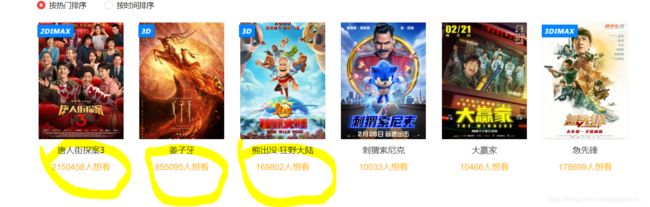 比较粗糙将就着看下hhh, 我用黄色圈起来的数字即为猫眼的加密字体,按照常规操作右键→检查→element,锁定该数据的位置,我们可以看到
比较粗糙将就着看下hhh, 我用黄色圈起来的数字即为猫眼的加密字体,按照常规操作右键→检查→element,锁定该数据的位置,我们可以看到
 这里span标签下的数据很明显被加密了,是一堆框框组成的,接下来我们再看一下网页源代码
这里span标签下的数据很明显被加密了,是一堆框框组成的,接下来我们再看一下网页源代码
[外链图片转存失败,源站可能有防盗]!链机制,建(https://img-s4blog.cwdnimg.cn/202019225223166.PNG#pic_center)htt225223166.PNG#pic_center)]红色笔圈起来的代码即为我们今天的主题,加密字体,今天的目标也是攻克该加密字体。
先捋一下思路,我们在正常的网页上能看到具体的123456数字,但为什么源代码上却是一堆奇怪的乱码?用大白话来说,就是我们在请求该页面的时候,猫眼那头儿,也会动态传递过来一个字体包,而这些字体包里存在某种映射关系,即数字和上面这堆乱码之间的对应关系,而后浏览器自动将这些乱码解析成我们看得懂的数字。
那我们现在要如何去捕获这个字体包呢?看下图
 一般来说,像字体包这类的数据均存放在Font内,下方的woff格式的文件即为该页面对应的字体包。
一般来说,像字体包这类的数据均存放在Font内,下方的woff格式的文件即为该页面对应的字体包。
我个人觉得这个猫眼的加密字体也是有够恶心的。。每一页的字体包都不一样,并且他是会实时动态变化的,举个例子,比方说,我现在访问该界面,乱码对应的数字是1,但过一会儿再刷新相同的页面,之前的映射关系也全部发生了变化,并且数字的坐标也会发生一定程度的变化,这点后面分析会着重提到。
二、具体的分析
一、预热
在爬取之前,我们需要去做一项准备工作,就是先去下一份该网站的字体包,解析字体,方便我们日后去比较,这边推荐使用fontcreator,如下图,
 这样数字和Unicode之间的关系就连结起来了,但这并不是数字和我们所看到的乱码之间的对应关系,因此我们还要接着使用python的一个第三方模块,fontTools,用来解析woff文件,
这样数字和Unicode之间的关系就连结起来了,但这并不是数字和我们所看到的乱码之间的对应关系,因此我们还要接着使用python的一个第三方模块,fontTools,用来解析woff文件,from fontTools.ttLib import TTFont file = TTFont('maoyan.woff') list1 = file.getBestCmap()
这样我们得到的结果即为:
{120: 'x', 58475: 'uniE46B', 58674: 'uniE532', 60748: 'uniED4C', 60974: 'uniEE2E', 61385: 'uniEFC9', 61969: 'uniF211', 62172: 'uniF2DC', 63131: 'uniF69B', 63406: 'uniF7AE', 63443: 'uniF7D3'}
这里返回的是一个字典,字典里面的键换算成十六进制 0x— ,再将0替换掉,即为我们所看到的密文啦,这样我们的准备工作也就完成了,建立了一套可供参考的映射关系。
二、进入正题
因为该加密文件是实时动态变化的,我们要先找到存放该加密字体文件的具体位置,最简单的方法:因为字体文件是woff格式的,我们先在F12-element中直接搜索woff
 这样就能很清楚的看到啦,接着我们使用一个简单的正则,再进行一个拼接我们就能下载好字体块啦。代码如下:
这样就能很清楚的看到啦,接着我们使用一个简单的正则,再进行一个拼接我们就能下载好字体块啦。代码如下:
woff = re.findall(r'//vfile.*?woff', res)[0]
woff_url = 'http:' + woff
woff_resp = requests.get(woff_url, headers=headers).content
with open('movie.woff', 'wb') as fi:
fi.write(woff_resp)
接着,我们便要两个文件一起操作,一是我们之间所准备好的参照物,二是我们需要翻译的字体块。
# 打开参考文件和要翻译的文件
trans_file = TTFont('movie.woff')
refer_file = TTFont('maoyan.woff')
# 打开参考和翻译的Unicode列表,以及参考表Unicode对应的数字
trans_file_list = trans_file.getGlyphOrder()[1:]
refer_file_list = refer_file.getGlyphOrder()[1:]
shuzi = ['', '1', '0', '5', '3', '6', '8', '2', '7', '4', '9']
getGlyphOrder的调用返回的是一个Unicode列表,由于该列表的第一个元素没用,我们从第二个开始取,紧接着SHUZI这一列表是我们所设置的参考表,该表的数字和打开的参考文件列表一一对应。
接着我们的工作是要对翻译文件动刀
# 编写源代码中的16进制乱码与Unicode的映射关系,翻译组:trans_tump为十进制数字和Unicode之间的映射关系,real_tump为十六进制乱码和Unicode之间的
# 映射关系
trans_tump = trans_file.getBestCmap()
real_tump = {}
trans_dict = {}
for i, j in trans_tump.items():
real_tump['&#' + hex(i)[1:]] = j
上式的代码比较简单,即建立正确的我们所看到的乱码和Unicode之间的映射关系。
接下来便是我们的重头戏啦,要将参考组和翻译文件里面的数据一一对应起来,先上代码。
# 寻找参考组和翻译组间的对应关系并用trans_dict字典联系起来,其中字典内容为翻译的数字和Unicode之间的映射关系
for trans_file_element in trans_file_list: # 对翻译组的Unicode进行循环
coordinate = trans_file['glyf'][trans_file_element].coordinates # 坐标
for i, refer_file_element in enumerate(refer_file_list): # 对参考组的数据进行迭代
refer_co = refer_file['glyf'][refer_file_element].coordinates
if analys(coordinate, refer_co):
trans_dict[trans_file_element] = shuzi[i]
break
我们要将二者的关系用正确的对应起来------通过比较坐标之间的关系,analys是一个比较函数,因为猫眼的这项数据的反爬有点恶心,两组数据对应相同的数字,该数字的每个点的坐标也是有所不同的,会实时发生变化。因此之前各位大佬直接比较的==号对猫眼来说已经失效了。
我们直接进入analys函数来看看
def analys(a,b):
# 判断参考码和验证码是否统一
found = False
n = 0
if abs(len(a) - len(b)) >= 5 :
return found
for i in range(min(len(a),len(b))):
if abs(a[i][0] - b[i][0]) <=30 or abs(a[i][1] - b[i][1]) <= 30:
n += 1
x = abs(len(b)-len(a))
for i in range(min(len(a),len(b)),x+max(len(a),len(b))):
if len(a) == len(b):
break
elif len(a) > len(b):
if abs(a[i-x][0] - b[i-2*x][0]) <= 10 or abs(a[i-x][1] - b[i-2*x][1]) <= 10:
n += 1
elif len(a) < len(b):
if abs(a[i-2*x][0] - b[i-x][0]) <= 10 or abs(a[i-2*x][1] - b[i-ax][1]) <= 10:
n += 1
if n >= min(len(a),len(b)) * 0.30:
found = True
return found
else:
return found
if n >= min(len(a),len(b)) * 0.30:
found = True
return found
传入两个坐标,一个是翻译文件的坐标,一个是用来比较的参考文件的坐标,为什么要搞得这么麻烦,比方说,在参考文件中,数字1包含了10个坐标,但在翻译文件中可能就会有11.12.9个坐标,因为直接跳过一个坐标也能画出图形,所以我们初步就用一个坐标数量来筛选,接着我们看如下

 我们可以很明显看出,这两个5字是用不一样的字体写的,因此他内部的坐标起伏也会特别大,所以我们必须给定一个参考值,经过本弟弟的多次测试,匹配得到误差范围百分30-35内的点即可配出正确数字,百分点设得过高无法匹配完全,因为有些坐标长度不统一,我后面又杀了个回马枪,从后面开始匹配。
我们可以很明显看出,这两个5字是用不一样的字体写的,因此他内部的坐标起伏也会特别大,所以我们必须给定一个参考值,经过本弟弟的多次测试,匹配得到误差范围百分30-35内的点即可配出正确数字,百分点设得过高无法匹配完全,因为有些坐标长度不统一,我后面又杀了个回马枪,从后面开始匹配。
这时候,我们得到的是Unicode和数字之间的对应关系,还不够!!!最后!! 我们终于要把两个库直接的映射关系建立好了,接下来就是做一个替换了
# 将该页要翻译的16进制乱码与正确的数字之间的映射关系建立起来
real_dict = {}
for i, j in real_tump.items():
for k, u in trans_dict.items():
if j == k:
real_dict[i] = u
print(trans_dict)
return real_dict
这样,我们就把我们看到的乱码和数字之间的映射关系对应起来啦,接下来就是一个将我们趴下来的源码中的乱码全部替换成数字就可以了。
最后
放个源码,同理,票房数据也可以用此方法拿到,有啥问题大家可以一起交流,我也是个小白,大家一起相互进步
from lxml import etree
import json
from fontTools.ttLib import TTFont
import time
import re
def analys(a,b):
# 判断参考码和验证码是否统一
found = False
n = 0
if abs(len(a) - len(b)) >= 5 :
return found
for i in range(min(len(a),len(b))):
if abs(a[i][0] - b[i][0]) <=30 or abs(a[i][1] - b[i][1]) <= 30:
n += 1
x = abs(len(b)-len(a))
for i in range(min(len(a),len(b)),x+max(len(a),len(b))):
if len(a) == len(b):
break
elif len(a) > len(b):
if abs(a[i-x][0] - b[i-2*x][0]) <= 10 or abs(a[i-x][1] - b[i-2*x][1]) <= 10:
n += 1
elif len(a) < len(b):
if abs(a[i-2*x][0] - b[i-x][0]) <= 10 or abs(a[i-2*x][1] - b[i-ax][1]) <= 10:
n += 1
if n >= min(len(a),len(b)) * 0.30:
found = True
return found
else:
return found
def find_secret_type(res):
# 查找加密字体源文件并下载
woff = re.findall(r'//vfile.*?woff', res)[0]
woff_url = 'http:' + woff
woff_resp = requests.get(woff_url, headers=headers).content
with open('movie.woff', 'wb') as fi:
fi.write(woff_resp)
# 打开参考文件和要翻译的文件
trans_file = TTFont('movie.woff')
refer_file = TTFont('maoyan.woff')
# 打开参考和翻译的Unicode列表,以及参考表Unicode对应的数字
trans_file_list = trans_file.getGlyphOrder()[1:]
refer_file_list = refer_file.getGlyphOrder()[1:]
shuzi = ['', '1', '0', '5', '3', '6', '8', '2', '7', '4', '9']
# 编写源代码中的16进制乱码与Unicode的映射关系,翻译组:trans_tump为十进制数字和Unicode之间的映射关系,real_tump为十六进制乱码和Unicode之间的
# 映射关系
trans_tump = trans_file.getBestCmap()
real_tump = {}
trans_dict = {}
for i, j in trans_tump.items():
real_tump['&#' + hex(i)[1:]] = j
# 寻找参考组和翻译组间的对应关系并用trans_dict字典联系起来,其中字典内容为翻译的数字和Unicode之间的映射关系
for trans_file_element in trans_file_list: # 对翻译组的Unicode进行循环
coordinate = trans_file['glyf'][trans_file_element].coordinates # 坐标
for i, refer_file_element in enumerate(refer_file_list): # 对参考组的数据进行迭代
refer_co = refer_file['glyf'][refer_file_element].coordinates
if analys(coordinate, refer_co):
trans_dict[trans_file_element] = shuzi[i]
break
# 将该页要翻译的16进制乱码与正确的数字之间的映射关系建立起来
real_dict = {}
for i, j in real_tump.items():
for k, u in trans_dict.items():
if j == k:
real_dict[i] = u
print(trans_dict)
return real_dict
def save_data(title,watch_people,intor):
# 保存数据
print('正在保存%s的数据当中' % title)
save_data = {}
save_data['电影名称'] = title
save_data['想看人数'] = watch_people
save_data['内容简介'] = intor
datas = json.dumps(save_data,ensure_ascii=False)
with open('近期电影详情.json','a',encoding='utf-8') as fi:
fi.write(datas+'\n')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'Referer': 'https://maoyan.com/board',
}
session = requests.session()
session.get('https://maoyan.com/films',headers=headers)
cookies = session.cookies
for i in range(0,120,30):
# 访问页面 获取详情页的url
url = 'https://maoyan.com/films?showType=2&offset='+str(i)
resp = requests.get(url,headers=headers,cookies=cookies).text
time.sleep(1)
content = etree.HTML(resp)
detail_urls = content.xpath('//dd/div[2]/a/@href')
for detail in detail_urls:
detail_url = 'https://maoyan.com'+detail
res = requests.get(detail_url,headers=headers).text
time.sleep(0.5)
real_dict = find_secret_type(res) # 破解加密字体,获得映射关系字典
for k,u in real_dict.items(): # 将加密字体全部替换掉
res = res.replace(k,u)
content = etree.HTML(res)
title = content.xpath('//h1/text()')[0]
intor = content.xpath('//span[@class="dra"]/text()')[0]
people = content.xpath('//span[@class="stonefont"]/text()')[0]
# 处理加密字体
watch_people = ''
for i in range(0,len(people),2):
watch_people += people[i]
# 保存数据json
save_data(title,watch_people,intor)
还有那个font creator文件,大家自己百度搜下破解版的就行啦,还是比较好找的,如果找不到也可以来找我拿。
纯原创,仅用于学习交流使用~~ 转载请注明出处,写第一篇博客还是有点小激动的~~