正则表达式浅谈
什么是正则表达式
菜鸟解释
对字符串操作的一种逻辑公式,用事先定义的特定字符和某些元字符,组成的一个“规则字符串”,这个“规则字符串”表达对字符串的一种过滤逻辑,已达到对目标字符串检索是否存在“规则字符串”,以及对匹配到的“规则字符串”进行提取,替换,删除等操作。
简单来说就是对字符串进行处理的。
优点
1,灵活性,逻辑性和功能性非常强大
2,可以迅速的用极其简单的方式达到字符串复杂的操作
缺点
1,对于刚接触的人来说比较复杂,晦涩难懂
2,具有贪婪性,懒惰性【可避免】
用一个例子简单来介绍其强大之处
查找出现最多的字符,不分大小写
//输出为fhsv,10次
从代码上看来,利用正则表达式会更加的简便且易于维护,虽然开始对其可能是一脸蒙蔽,什么火星文字,但是学习它还是有必要性的。
正则表达式创建方式
pattern----正则表达式(模式:由自定义的特定字符和已定义的元字符组成)
flag—标志(标志:)
1,字面量创建方式
var reg = /pattern/flags;
2,实例创建方式
var reg = new RegExp(pattern,flags);
标识符(flag)
1,i忽略字符串中的所选字符大小
2,g全局匹配
3,m文本中的多行匹配
var str = '123sdbs456jscDs789';
reg = /\d+/;//默认标识符为局部匹配
console.log(str.match(reg));//输出“123”
reg = /\d+/g;//输出为“123”,“456”,“789”
reg = /d+/ig;//输出为“d”,“D”
文本就不展示了。。。
元字符
常用特殊字符
\d : 0-9之间的任意一个数字 \d只占一个位置
\w : 数字,字母 ,下划线 0-9 a-z A-Z _
\s : 空格或者空白等
\D : 除了\d,相当于[^\d]
\W : 除了\w,相当于[^\w]
\S : 除了\s,相当于[^\s]
. : 除了\n之外的任意一个字符
\ : 转义字符
| : 或者
() : 分组
\n : 匹配换行符
\b : 匹配边界 字符串的开头和结尾 空格的两边都是边界 => 不占用字符串位数
^ : 限定开始位置 => 本身不占位置
$ : 限定结束位置 => 本身不占位置
[a-z] : 任意字母 []中的表示任意一个都可以
[^a-z] : 非字母 []中^代表除了
[abc] : abc三个字母中的任何一个 [^abc]除了这三个字母中的任何一个字符
建议链接
量词符
* : 0到多个
+ : 1到多个
? : 0次或1次 可有可无
{n} : 正好n次;
{n,} : n到多次
{n,m} : n次到m次
正则常用方法
var str = '123hdjs456';
var reg1 = /\d+/g;
var reg2 = new RegExp(/\d+/ , 'g');
test
语法:RegExpObject.test(string)
作用:string存在匹配的正则字段,返回true,否则返回false
console.log(reg1.test(str));//字面创建方式test函数
console.log(reg2.test(str));//实例创建方式test函数
match
语法:strObject.match(searchvalue/regexp)—返回所匹配的值或则null
作用:在strObject中检索指定的searchvalue,或匹配一个或多个regexp
console.log(str.match(reg1));//字面创建方式test函数
console.log(str.match(reg2));//实例创建方式test函数
exec
语法:RegExpObject.exec(string)
作用:返回一个数组,返回匹配的结果
console.log(reg1.lastIndex);//位置为0时开始第一段正则匹配
console.log(reg1.exec(str));//第一段正则匹配,结果为"123"
console.log(reg1.lastIndex);//位置为3时开始第二段正则匹配
console.log(reg1.exec(str));//第二段正则匹配,结果为"456"
console.log(reg1.lastIndex);//位置为10时开始第三段正则匹配
replace
语法:strObject.replace(regexp/substr , replacement)—返回值为匹配完后的新的字符串
substr:【中文意思:字串】
replacement:可以是字符串也可以是返回值为字符串的函数
作用:在字符串中用一些字符替换另一些字符,或则替换一个与正则表达式匹配得字串
var str = '123hhhhhhhhhhhhhhhhhhh456';
console.log(str.replace(reg1 , '0000'));
console.log(str.replace(reg1 , function ( $0 , $1 , $2) {
var Str;
Str = "字符串str被替换数据为:" + $0 + ";起始索引index为:" + $1 + ";字符串str原始总长度为:" + $2.length;
return Str;
}));
结果:

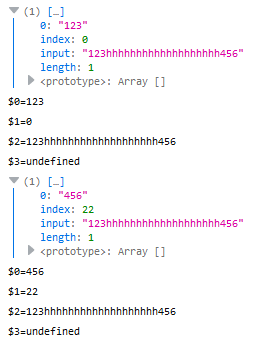
在这里肯定会有人疑惑,$0,$1,$2是什莫,其实这里是exec函数捕获返回的数组中的值与属性。折磨说肯定听不太懂,我们来看代码。
str.replace(reg1, function($0, $1, $2, $3) {
console.log(reg1.exec(str));
console.log("$0=" + $0);
console.log("$1=" + $1);
console.log("$2=" + $2);
console.log("$3=" + $3);
});
结果:
正则的[]分组【如果想知道相关()分组,可自行查找正则分组优先级问题】
我们举个查询年龄问题来看看,平常我们未知查询年龄,我们一般会规定一个范围
例如:查找年龄在16~24岁范围内的,是返回true,不是返回false
var oldObject = {
jack : "17",
tom :"24",
lisa :"34"
}
var arr = new Array ("jack" , "tom" , "lisa");
var reg = /(1[6-9])|(2[0-4])/;
for (var i = 0; i < arr.length; i++) {
var oldstr = oldObject[arr[i]];
console.log(arr[i] + ":" + reg.test(oldstr));
}
有没有注意到我们的范围规定是拆分的,如果我们把reg改成
var reg = /([16-24])/;//报错SyntaxError: invalid range in character class
报错:在特定类中reg是无效范围
所以可得:在[]中不会出现两位及其以上位数的数字
关于regexp的贪婪性【利用量词符解决】和懒惰性【利用全局标志g解决】,在这就不多加累述了。
菜鸟爬行中…