python3 实现火车票查询 代码+知识点
一. prettytable
1. 简介:可以将输出内容按照表格方式整齐输出。
2. 安装:pip install prettytable
3. 导入:from prettytable import PrettyTable
4. 示例:
from prettytable import PrettyTable
table = PrettyTable(["id", "name"])
table.add_row([1, "lili"])
table.add_row([2, "rose"])
table.add_row([3, "nancy"])
table.add_row([4, "puppet"])
print(table)
效果:

5. 使用
5.1 创建表
pt = PrettyTable()
5.2 按行/列添加
pt.add_row() # 行
pt.add_column() # 列
6. 输出
6.1 直接输出
print(pt)
6.2 无表格框输出
print(pt.get_string())
二. split
1. 作用:切分字符串
2. 示例:
"2:3:4:5".split(":")
"|a|b|c".split("|")
结果
["2", "3", "4", "5"]
["", "a", "b", "c"]
三. \u4e00”和“\u9fa5
1. 简介:判断字符串中是否包含中文
“\u4e00”和“\u9fa5”是unicode编码,是unicode表中的汉字的开始和结束。[\u4e00-\u9fa5]+,[]表示内容,+代表至少出现一次。
四. print和pprint区别
1. 简介:
大致相同,但pprint打印更加完整,每行为一个数据结构,方便阅读,对于较长的数据,print打印都在一行,pprint分行打印
五. colorama
1. 简介:给字体着色
2. 安装:pip install colorama
3. 导入:from colorama import init, Fore, Back, Style
说明:
init():初始化,其中可以传入参数,autoreset 。默认值为 False ,如果设置为 True,它就会在每一次输出语句之后自动清空格式。
Fore:前景色(即字体颜色)
Back:背景色
Style:改变字体的显示模式。
三个属性可设置的参数如下:
Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
Style: DIM, NORMAL, BRIGHT, RESET_ALL
4. 示例
from colorama import init, Fore, Back, Style
init()
print(Fore.LIGHTGREEN_EX + "some red text")
print(Back.RED + "and with a green background")
print(Style.BRIGHT + "and in dim text")
print(Style.RESET_ALL)
print("back to normal now!!")
效果

六. 正文
有了上面的基础铺垫,再看代码会简单很多
tickets.py
"""Train tickets query via command-line.
火车票通过命令行查询。
Usage:
tickets [-gdtkz]
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets beijing shanghai 2020-01-25
"""
import json
import colorama
from prettytable import PrettyTable
from colorama import init, Fore, Back, Style
from station import station
import requests
from colorama import init, Fore
from docopt import docopt
init() # 使用colorama前的初始化
def cli():
arguments = docopt(__doc__)
from_station = station.get(arguments['' ]) # station是个字典
to_station = station.get(arguments['' ])
date = arguments['' ]
# 构建url,输入车站名字,直接从station字典中获得相对应的字母代码
url = 'https://kyfw.12306.cn/otn/leftTicket/queryO?leftTicketDTO.train_date={}' \
'&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(date, from_station, to_station)
# print("这是网址:", url)
options = ''.join([
key for key, value in arguments.items() if value is True])
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'Cookie': 'JSESSIONID=0FCBD07FA01EA1713255920101896AC0;'
' route=c5c62a339e7744272a54643b3be5bf64;'
' BIGipServerpool_passport=384631306.50215.0000; RAIL_EXPIRATION=1582955512068; '
'RAIL_DEVICEID=qUANl2BZU-iRhsSMlPYc2Ut5AU-XbI_'
'XGAWLMc6T1MVYaIeLtvh3KoZuNsAM4fIIznGMn7Z5bx246WADUQl2C2AZhqvnwJmYH-3DRnXMvWRItWlMtwfayV6YckM8VU7UMhb5'
'R6cJChWUeBOyEDz-LP_GYdUBPGZ7; '
'_jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; '
'_jc_save_toDate=2020-02-26; '
'_jc_save_wfdc_flag=dc; BIGipServerotn=2062024970.64545.0000; _jc_save_fromDate=2020-02-27'
}
r = requests.get(url, verify=False, headers=headers) # 添加verify=False参数不验证证书
available_trains = r.json()['data']['result'] # 返回列表
station_map = r.json()['data']['map'] # 返回的是字典形式,地名和代号一一对应,下面要用到
# print(station_map) # {'AOH': '上海虹桥', 'VNP': '北京南', 'SNH': '上海南', 'BJP': '北京', 'SHH': '上海'}
# 做表格,设置表头
table = PrettyTable(["车次", "出发站", "到达站", "出发时间", "到达时间", "历时", "特等座", "一等座", "二等座", "软卧",
"硬卧", "软座", "硬座", "无座"])
for data in available_trains:
list = data.split("|") # 按照“|” 切分
# print(list)
if list[1] == '列车停运': # 以列车停运开头的那几行均不是
continue
line_nun = list[3] # 车次
from_sta = list[6]
to_sta = list[7]
start_time = list[8]
stop_time = list[9]
cost_time = list[10]
TDZ = list[32] or "--" # 特等座 # 如果没有信息,用--显示
YDZ = list[31] or "--" # 一等座
EDZ = list[30] or "--" # 二等座
RW = list[23] or "--" # 软卧
YW = list[28] or "--" # 硬卧
RZ = list[27] or "--" # 软座
YZ = list[29] or "--" # 硬座
WZ = list[26] or "--" # 无座
# 表格添加列 按照表格方式整齐地输出+对输出的每个字符和“|”进行着色
table.add_row([line_nun, Fore.LIGHTRED_EX+station_map[from_sta]+Fore.RESET,
Fore.LIGHTBLUE_EX + station_map[to_sta]+Fore.RESET,
Fore.LIGHTRED_EX+start_time+Fore.RESET, Fore.LIGHTGREEN_EX+stop_time+Fore.RESET,
cost_time, TDZ, YDZ, EDZ, RW, YW, RZ, YZ, WZ])
print(table)
if __name__ == '__main__':
cli()
parse_station.py
"""提取地址及其对应的代号"""
import re
import requests
from pprint import pprint
# 地址和代号网址
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8955'
# 获取url
response = requests.get(url, verify=False) # 移除SSL认证
# 正则提取中文和代号 格式:列表 内包含多个元组,元组形式 (‘上海’,‘SHH’)
station = re.findall(u'([\u4e00-\u9fa5]+)\|([A-Z]+)', response.text) # 解析页面中中文和大写字母
# 定义打印信息 缩进4个空格
pprint(dict(station), indent=4)
1. 其实全程用到两个url
url1:根据输入的“起始站”+“终点站”+“日期”来查询结果的页面,所以需要模拟这个url。
url2:解析地名和地名代号的页面。
2. available_trains的打印结果如下

“列车停运”部分不是我们需要的,黄色框选的地方才是
3.for data in available_trains:
list = data.split("|")
print(list) 将available_trains分割后,打印结果如下:
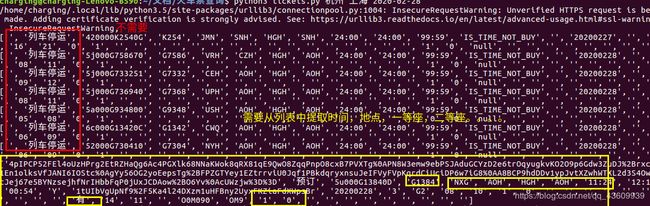
其余不解释了,代码很简短。
最终效果(都能对的上,配色可以自己调,green/red/blue)
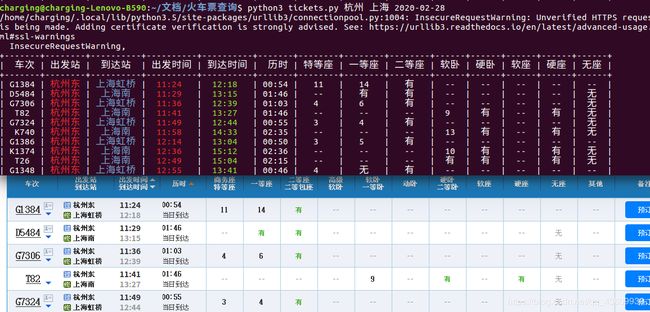
文件下载
https://github.com/Charging01/ticket-query.git