(对于图像分割多类别输出通道的理解)Keras 实现 FCN 语义分割并训练自己的数据之多分类
原文链接:https://blog.csdn.net/yx123919804/article/details/104826643
Keras 实现 FCN 语义分割并训练自己的数据之 多分类
- 一. 数据标注
- 二. 标签图像数据处理
- 三. 网络输出层处理
- 四. 预测类别判断
一. 数据标注
在 Keras 实现 FCN 语义分割并训练自己的数据之 FCN-32s 中我们提到了二分类的数据如何标注, 多分类其实基本一至, 标记完成一个区域后, 要输入不同的类别名称, 比如前面是 balloon, 第二个类别为 cat, 那你就输入 cat 就好了, 这个没有难度. 标记的同时注意标记的颜色, 这个颜色是有固定顺序的, 就是索引图像的颜色表中的顺序
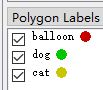
大家有疑惑的是 假如在第一张图像中有 balloon, dog, cat. 也是这个先后顺序, 那这三个的序号分别是 1, 2, 3(因为 0 是背景). 在第二张图中只有两类, 分类是 dog, cat. 那 dog 还是 2, cat 还是 3 吗? 马上验证一下
- 第一张图中三类目标的颜色
- 第二张图中两类目标颜色
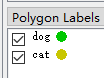
可以看出, 就算是类别数据不一样, 也是按照标记的顺序来依次排列的, 所以放心标记就好了, 完成之后一样生成数据集就好了
二. 标签图像数据处理
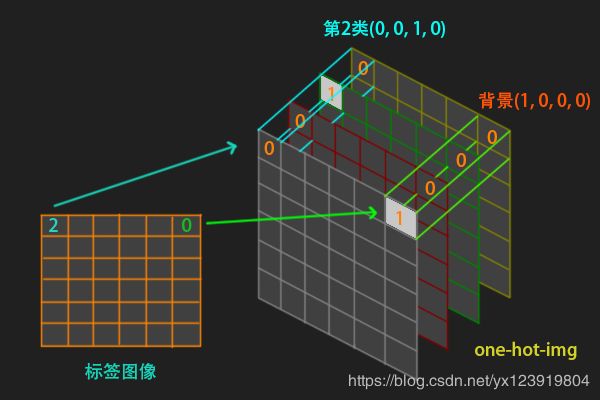
二分类时标记的类别只有背景和目标, 目标像素值是 1, 所以处理很简单, 转换成 float 类型就可以了. 对于多分类, 处理方式不一样. 首先多分类激活函数是 softmax, 用的是 one-hot 编码. 我们标注的数据是单通道, 像素值分别是 0(背景), 1, 2, 3…, 怎么转换成 one-hot 的形式呢?
可以新建一张和标签图像同样大小全是 0 的图像, 暂且取名为 one_hot_img, 但是通道数是 类别 数(包括背景), 现在知道该怎么弄了吧. 依次判断标签图像每个位置的像素值, 如果是 0, 就把 one_hot_img 第 1 个通道对应位置的值设为 1, 如果是 3, 就把第 4 个通道对应位置的值设为 1. 这样, one_hot_img 的每个像素位置所有通道就组合成了一个 one-hot 编码的 vector. 相信下面这张图够清楚了吧
这个代码与容易实现
project_path = osp.join("E:\\Jupyter_Files", project_name)
file_path = osp.join(project_path, "dataset")
folders = os.listdir(file_path)
class_num = 4 # 类别数量, 包括背景
class_vec = np.identity(class_num, dtype = np.float) # 类别向量, 如下
‘’’
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
‘’’
img_data = [] # 图像
label_data = [] # 标签
for i in folders:
img = Image.open(osp.join(file_path, i, “img.png”), ‘r’)
img_data.append(img)
# 这里多用了 np.array, 要不然又是三通道的了
img = np.array(Image.open(osp.join(file_path, i, "label.png"), 'r'))
one_hot = np.zeros((img.shape[0], img.shape[1], class_num), dtype = np.float)
for r in range(one_hot.shape[0]):
for c in range(one_hot.shape[1]):
one_hot[r][c] = class_vec[img[r][c]]
label_data.append(one_hot)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
这样读入的标签就成了 one-hot 的格式了
在不做 one-hot 处理的情况下, 读入的标签图像如下, 可以看到 gound_truth 各个类别的值是不一样的, 就是索引图像的值, 实际上标签图像看起来是全黑的, 因为像素值比较小, 下图看起来很清楚是因为 matplotlib.pyplot 在显示的时候把值放大了

其他如数据范围和 Crop 可以参考 Keras 实现 FCN 语义分割并训练自己的数据之 FCN-32s , 都不用修改
三. 网络输出层处理
在二分类的时候, 输出层只有一个通道, 多分类就需要有 class_num(类别数, 包括背景) 个通道, 所以最后一个卷积时需要有 class_num 个 Filer, 还要修改激活函数为 softmax . 修改如下
# Keras 实现 FCN 语义分割并训练自己的数据之 FCN-32s 中用的代码
# 第 5 组 MaxPool2D
model.add(keras.layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2), name = "max_pool_5"))
model.add(keras.layers.UpSampling2D(size = (32, 32), interpolation = "nearest", name = "upsamping_6"))
model.add(keras.layers.Conv2D(class_num, kernel_size = (3, 3), activation = "softmax",
padding = "same", name = "conv_7"))
# Keras 实现 FCN 语义分割并训练自己的数据之 FCN-16s、FCN-8s 中用的代码
conv_7 = keras.layers.Conv2D(class_num, kernel_size = (3, 3), activation = “softmax”,
padding = “same”, name = “conv_7”)(up7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
除了输出层, 还有损失函数修改为 categorical_crossentropy
model.compile(optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy"])
- 1
- 2
- 3
接下来的训练没有什么差异了
四. 预测类别判断
预测输出是一张 class_num 通道的图像, 只要判断 每个像素位置哪一个通道的值最大, 就把此通道的通道序号作为最后的类别, 把上面转换成 one-hot 图像的顺序反过来应用, 预测代码还是不变, 誊写下来
# 测试新数据
test_start = 0
test_images = 8 # 依情况自己修改
# 使用最好的参数
model.load_weights(osp.join(project_path, “train_log\fcn_weights.h5”))
y = model.predict(np.array(x_test[test_start: test_start + test_images]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
类别判断
img_res = [] # 结果图像
for i in range(test_images):
mask = np.zeros((y[i].shape[0], y[i].shape[1]), np.uint8)
for r in range(y[i].shape[0]):
for c in range(y[i].shape[1]):
mask[r][c] = np.argmax(y[i][r][c])
img_res.append(mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
img_res 中存放的是每一张预测图的结果图像, 单通道, 其像素值就是类别序号
如果想把预测结果标记到原图的话, 把需要标记的颜色做一个索引表, 用结果图像的像素值去索引取出 RGB 值, 这个 RGB 值就是对应目标标记的颜色. 这一步可以在类别判断的时候做, 也可以用 img_res 来做, 下面假设你要标记颜色的图像名称名 img_src, 三通道, 预测结果图像名称为 predict
# 标记颜色表, 这个颜色选你喜欢的就好
mark_rgb = [[0, 0, 0], # 背景
[128, 0, 0], # 类别 1
[0, 128, 0], # 类别 2
[128, 128, 0]] # 类别 3
# 假设你要标记颜色的图像名称名 img_src, 三通道, 预测结果图像名称为 predict, 则标记如下
for r in range(img_src.shape[0]):
for c in range(img_src.shape[1]):
img_src[r][c] = mark_rgb[predict[r][c]]
# 如果在判断时做就是
# img_src[r][c] = mark_rgb[np.argmax(y[i][r][c])]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
至此, FCN 基本原理的代码就完成了, 针对不同的任务, 网络结构需要优化, 不是一个网络走天下, 什么都通吃. 所以要分析问题的特点以选择不同的方式