Real-time rendering笔记
Chapter 1 Introduction
1. 实时渲染---图像在计算机上快速的显示
2. 15fps --- 实时渲染的基本fps. 72fps以及更大的fps观察者无法发现其中的差别 60fps 对反应时间来说太小了, 只有15ms的时间用于用户反映.
3. 实时渲染的三个条件: 互动, 三维空间, 图形加速
1.1 Contents Overview
4. 各章节介绍
-
Chapter 2 The Graphics Rendering Pipeline: 实时渲染的核心概念
-
Chapter 3 The Graphics Processing Unit: 现代GPU使用固定功能单元和可编程单元实现渲染管线的各个阶段
-
Chapter 4 Transform
-
Chapter 5 Visual Appearance: 材质和光照, 反锯齿, gamma修正
-
Chapter 6 Texturing
-
Chapter 7 Advanced Shading 正确表现材质和点光源的理论和实践
-
Chapter 8 Area and Environmental Lighting
-
Chapter 9 Global Illumination 阴影, 反射, 折射算法, 辐射, 光线追踪, 预处理光照, 环境封闭
-
Chapter 10 Image-Based Effect: lens flares, fire, motion blu, ....
-
Chapter 11 Non-Photorealistic Rendering: cartoon shading
-
Chapter 12 Polygonal Techniques: 讨论多边形数据, 并优化和简化其数据
-
Chapter 13 Curves and Curved Surfaces
-
Chapter 14 Acceleration Algorithms: culling 和 LOD渲染的不同形式
-
Chapter 15 Pipeline Optimization 发现和解决瓶颈
-
Chapter 16 Intersection Test Methods 相交检测
-
Chapter 17 Collision Detection 碰撞检测
-
Chapter 18 Graphics Hardware 颜色深度, 帧缓存, 基本结构体类型, 一些有代表性的图形加速器研究
-
Chapter 19 The Future
1.2 Notation and Definitions (记号和定义)
-
向量使用列向量格式
-
v = {x, y, z, 0} 表示向量, v = {x, y, z, 1} 表示一个点
Chapter 2 The Graphics Rendering Pipeline
-
Bresenham's line-drawing algorithm[142], symmetric double-step algorithm[1391]
-
渲染管线的速度取决于管线中最慢的环节, 无论其他的环节速度多快
-
粗略的将实时渲染管线划分为三个环节: application, geometry, rasterizer
-
概念环节(application, geometry, rasterizer) conceptual stages, 功能环节 functional stages, 管线环节 pipeline stages的区别
-
功能环节 ---- 执行特定的task, 不管如何在管线中实现
-
管线环节 ---- 和其他的管线环节同步
-
也许多个功能环节合并成一个管线环节, 也许一个功能环节分割成多个管线环节
-
-
两个用来表示渲染速度的方式: fps 和 Hertz(Hz)
-
例子: 计算渲染速度
-
假设输出设备的最大更新频率为 60 Hz, 渲染管线的瓶颈环节已经发现, 为62.5ms.
-
渲染速度的最大值为 1/0.0625 = 16fps
-
60/1 = 60Hz, 60/2 = 30Hz, 60/3 = 20Hz, 60/4 = 15Hz, 60/5 = 12Hz
-
15Hz 是小于16fps之下的最大值, 所以最后预计渲染速度为15fps.
-
-
-
-
application stage --- 运行于 CPU, 常处理 碰撞检测, global acceleration algorithm, 动画, 物理模拟以及其他
-
geometry stage --- 通常使用GPU, 常处理 transforms, projections
-
rasterizer stage --- 渲染前面生成的图像, 完全在GPU上处理.
2.2 The Application Stage
-
开发者可完全控制该阶段
-
为了提供性能, 在多核处理器上平行运算, superscalar construction. 见15.5介绍的利用多核处理器的方法
-
该阶段常处理碰撞检测. 处理输入(键盘, 鼠标, ...), 纹理动画. 以及其他阶段不会执行的计算.例如 Chapter 14 介绍的 hierarchical view frustum culling.
2.3 The Geometry Stage
-
处理大部分的顶点和多边形操作.分为以下几个功能环节: model and view transform, vertex shading, projection, clipping, screen mapping
-
模型转换后, 模型处于世界空间/世界坐标系中.
-
视图转换, 让相机处于原点, 且朝向为z负轴, 向上的方向为y轴, x轴为向右.
-
确定材质上光照效果的操作为 shading. 其包含在对象的顶点上计算 shading equation. 该计算有一部分在geometry环节执行, 另一部分在每个像素的光栅化(rasterization)执行, 存储在每个顶点上的一系列材质数据如位置, 发现, 颜色以及其他用于计算shading equation的信息. Vertex shading的结果发送给rasterization环节进行插值. (结果可为颜色, 向量, 纹理坐标以及其他类型的shading数据)
-
Shading 计算通常在世界空间中进行, 实际上, 为了方便有时转换相关实体(如相机和光源)到其他的空间(模型或视觉空间), 并在该空间进行计算.`
-
这是由于光源, 相机和模型的相对关系在转换至其他空间时仍会保持相同的相对关系.
-
-
shading之后就是执行 projection, 主要将视图锥转换至一个单元立方体, 范围为[-1, -1, -1]到[1, 1, 1]. 该单元立方体称为 canonical view volume.
-
两种projection方法: 正交和透视投影
-
投影之后, 模型位于 normalized device coordinates.投影之后, z坐标春处于 z缓存(深度缓存)中.
-
对部分在视图锥之内, 部分在视图锥之外的图元进行裁剪,
-
用户可以定义额外的裁剪平面. 在可编程处理单元(programmable processing units)进行
-
裁剪环节和屏幕映射环节(screen mapping stage)通常有固定操作硬件处理.
-
screen mapping环节, 将裁剪坐标x,y转换成屏幕坐标.
-
像素整数值和浮点值之间的关系: 一个像素的中心坐标为(0.5, 0.5), 所以像素范围[0, 9]可取值[0.0, 10.0)
-
Opengl将左下角的坐标作为最小值, DX将左上角的坐标作为最小值
2.4 The Rasterizer Stage
-
光栅化 --- 计算和设置绘制对象的像素颜色. 将屏幕空间中的二维顶点(带z值)以及每个顶点关联的各种shading信息转换至屏幕上的像素.
-
Rasterizer stage 划分为几个功能环节: triangle setup, triangle traversal, pixel shading, merging
-
triangle setup --- 计算三角形表面的差异和其他数据. 这些数据用于 scan conversion和各种各样shading数据的插值, 由固定操作硬件完成该功能.
-
triangle traversal --- 检查一些像素, 这些像素的中心点被三角形所覆盖. 并生成用于三角形上像素的片段.
-
查找在三角形之内的样本(sample)或像素的操作成为 triangle traversal 或 scan conversion.
-
通过三角形三个顶点的数据插值生成三角形片段(fragment)的性质. 这些性质包括片段的深度以及有geometry环节生成的shading 数据
-
Pixel shading --- 每个像素的shading计算, 输入数据为shading数据的插值结果, 输出数据为一个或多个颜色.该环节由可编程GPU来执行.
-
pixel shading环节可运用许多技术, 其中最重要的为texturing, 即将图片粘贴至模型上
-
Merging环节 --- 将shading环节产生的片段颜色和存储在color buffer里的颜色组合起来, 执行该环节的GPU子单元并非可完全编程的. 但其可进行各种配置, 实现各种效果.
-
Merging 环节还解决对象是否可视问题, 当渲染整个场景之后, 颜色缓存应当存储相机视图在该点可见图元的颜色. 对大多数图形硬件来说, 这点是由Z-buffer 算法完成. 每个像素存储距离相机最近图元的z值,
-
Z-buffer算法可以以任意顺序渲染大多数图元, 然而对于半透明图元则不能够任意顺序绘制, 必须绘制所有不透明图元之后, 以back-to-front顺序绘制.
-
除了 Z-buffer, color buffer缓存, 还有 alpha channel, 可进行 alpha test.在 depth test之前进行. 该测试的典型用法是确保完全透明的fragment不会影响到Z-buffer.
-
stencil buffer --- 记录渲染图元的位置, 每个像素八位数据.使用不同的函数图元渲染至stencil buffer.并且buffer的内容可用于控制是否渲染至color buffer 和 Z-buffer.
-
accumulation buffer -- 累积缓存.使用一系列操作对图像进行累积. 例如通过平均和累积图像可以生成 motion blur., 其他效果如 depth of field, antialiasing, soft shadow, etc.
-
double buffer --- 在 back buffer 进行渲染, 而后和 front buffer进行交换, 在 vertical retrace(真扫描)时进行交换.
2.5 Through the Pipeline
-
想象一个互动的CAD应用程序, 用户检查一个移动手机的设计, 透视投影. 手机模型有线条(边缘), 有三角形(表面), 有纹理(显示键盘和屏幕). 在geometry 环节计算 shading, 除了纹理部分, 该部分在 rasterization 环节发生.
-
Application 环节: 设置旋转矩阵进行手机翻盖操作, 设置相机以不同的位置和视角来浏览手机, 形成一个动画.
-
Geometry 环节 --- 模型矩阵和视图矩阵结合成模型视图矩阵, 将对象所有的顶点和法线转换至视图空间, 计算顶点的shading, 使用材质和光源属性.执行投影, 转换对象之单元立方体空间. 而后进行裁剪. 将顶点映射至屏幕上的窗口. 最后进行光栅化
-
Rasterizer 环节 --- 所有的图元进行光栅化, 转换成为窗口上的像素.进行纹理操作, 通过Z-buffer算法查看对象的可视性, 还有alpha测试, stencil 测试等.
Conclusion
-
offline rendering pipelines 也有不同的发展, 用于电影产品的渲染常使用 micropolygon pipelines,
-
本书默认使用可编程功能管线,
Further Reading and Resources
-
A Trip Down the Graphics Pipeline.
Chapter 3 The Graphics Processing Unit
-
相对于软件, 专用硬件可以提高速度
-
渲染管线的GPU实现: Vertex Shader()->Geometry Shader()-->Clipping(*)-->Screen Mapping(&)-->Trangle Setup(&)-->Triangle Traversal(&)-->Pixel Shader()-->Merger(**)
-
(*) 表示可完全编程的环节
-
(**) 表示可配置但不可编程的环节
-
(&) 表示完全固定功能的环节
-
3.1 GPU Pipeline Overview
-
vertex shader是完全可编程环节, 处理"Model and View Transform", "Vertex Shading" 和 "Projection" 功能环节.
-
geometry shader 是可选的, 完全可编程的环节, 操作图元上的顶点(点, 线, 三角形), 用于执行图元shading操作, 销毁图元, 创建图元
-
clipping, screen mapping, triangle setup, triangle traversal 环节都是固定功能环节.
-
pixel shader为可编程环节, 执行"Pixel shading".
-
merger 环节则为可编程和固定功能之间, 可进行很多配置来完成各种操作. color buffer, Z-buffer, blend, stencil和其他相关缓存.
3.2 The Programmable Shader Stage
-
现代shader环节(支持Shader Model 4.0)使用 common-shader core. 这表示 vertex, pixel, geometry shader 共享一个程序模型(programming model)
-
早期的 GPUs 在顶点和像素 shaders 有很少的共同点, 并且没有 geometry shader.
-
类C语法的着色语言: HLSL, Cg, GLSL, 这些语言编译至无关机器的汇编语言, 即 intermediate language(IL), 该汇编语言通常在驱动中转换至机器语言.该汇编语言可看成虚拟机. 该虚拟机是一处理器, 可处理不同的register类型和数据类型, 通过一系列的指令编程. 有 4路 SIMD(single-instruction multiple-data)能力. 每个register也有四个独立的值. 基本数据类型为32位单精度浮点数和向量. 支持32位整数.
-
一个 draw call 请求图形API绘制一组图元. 引起图形管线的执行. 每个可编程shader环节有两个类型的输入: uniform input 和 varying input.
-
uniform inputs 在整个 draw call中保持不变. (但在 draw calls之间可以变化)
-
varying inputs 则不同
-
纹理可看成 uniform input, 但是其也可以作为其他纹理的索引数组数据.
-
可通过只读的constant register 或 constant buffers来访问 Uniform inputs.
-
-
虚拟机还有通用的 temporary registers, 用于 scratch space. 所有registers的类型都可以用temporary registers中的整数值来进行数组下标.
-
最快的操作时标量和向量乘法, 加法, 以及之间的组合, 如点乘. 其他的操作如求倒数(reciprocal), 平方根, sin, cos, 指数和对数都相对耗时.
-
shader支持两种类型的流控制: static流控制用于uniform输入. dynamic流控制用于 varying 输入
-
shader程序可以在程序加载之前或者运行期进行离线编译, 可通过设置选项来生成不同的输出文件, 以及使用不同的优化等级.
-
一个编译的shader存储为一文本字符串. 通过驱动传送给GPU
3.3 The Evolution of Programmable Shading
-
用于shader设计的 visual shader graph system: mental mill
-
2007年发展出Shader Model 4.0, 主要特性有 geometry shader 和 stream output.
-
新的程序模型如NVIDIA的CUDA和AMD的CTM用于non-graphics applications
3.3.1 Comparison of Shader Models
-
表3.1 Shader Model 2.0, 3.0, 4.0的区别
3.4 The Vertex Shader
-
在DX中, Vertex Shader环节之前的数据操作成为 input assembler. 将一些数据流组织成一系列顶点和图元发送给管线.
-
在 input assembler 中支持 使用instancing, 即一个对象使用不同的数据可以通过复制来绘制多次.
-
在DX10中, input assembler 会给每个instance(实例), 图元, 顶点一个唯一的数字作为标记, 以便后来的shader可以访问.
-
对于 triangle mesh而言, 在vertex shader中不关心哪些顶点形成哪些三角形, 只处理那些输入的顶点.
-
vertex shader, 每个传送进来的顶点, 输出所在三角形或线条的一系列插值, 不能创建和销毁顶点, 一个顶点的结果不能影响到另外一个顶点. 所以每个顶点都是独立处理的, 多个shader processors在GPU里可以平行处理输入的顶点数据流.
-
vertex shader 可以实现的效果: shadow volume, 活动关节的顶点混合(见超级宝典), silhouette rendering
-
Lens effect, 屏幕显示鱼眼效果, 水下, 以及其他的扭曲效果
-
Object definition, 创建mesh一次, 并通过 vertex shader变形
-
Object twist, bend, taper operation
-
Primitive creation, 通过发送退化(degenerate)mesh给后面的管线, 并在需要的时候给予这些mesh空间. 这个功能在更新的GPU中被geometry shader替代.
-
Page curls, heat haze, water ripples, 通过将整个帧缓存的内容作为纹理贴在屏幕对齐的mesh上, 而后进行程序变形操作.
-
Vertex texture fetch. 用于将纹理作用于顶点mesh, 这样可以让海洋表面, 地形高度图的渲染耗费更小.
-
-
Vertex shader的输出有几个用法, 常用的方法是生成和光栅化每个实例(instance)的三角形, 产生的各自像素片段发送给像素着色器程序. Shader Model 4.0则可将vertex shader的输出发送给geometry shader.
3.5 The Geometry Shader
-
geometry shader 位于 vertex shader之后, 可选的.
-
geometry shader 的输入是 单个对象和它的顶点. 对象通常为一个网格内的一个三角形, 一个线段或者一个点. 另外, 可以额外传送三个三角形外的三个顶点, 在一个多边形可用2个相邻的点.
-
geometry shader 的输出是另个或多个图元, 形式为点, polylines, 三角形带, 多个三角形带. 一个mesh可以被有选择的修改. 方法是编辑顶点, 添加新的图元或者移除其他的图元.
-
geometry shader 对象的输入输出类型不一定需要匹配, 比如输入一个三角形, 而后以点的形式输出三角形的重心, 即使类型符合, 也可以忽略或者扩展每个顶点上的数据. 例如给每个输出后的顶点添加上其所在三角形平面的法线,
-
同 vertex shader, geometry shader 输得的每个顶点都位于裁剪空间位置上.
-
geometry shader 确保图元的输出次序和输入的次序一样. 这个会影响到性能. 为了性能和效率之间的平衡, 每次执行的限制总数为1024 32位值.所以不推荐大量拷贝一个模型, 或者将tesselation表面转换成详细的三角形mesh. geometry shader 环节更多用于修改输入的数据或者进行有限的拷贝. 而不要用于大量的拷贝或扩充.
-
geometry shader 算法: 根据点的数据创建不同大小的粒子, extruding fins along silhouettes, 阴影算法中的查找对象边缘
-
Shader Model 4.0 提出一个专用词 stream output, 在顶点被vertex shader(和 geometry shader)处理之后, 可以输出至流(stream)中, 例如, 一个有序数组, 除了可以发送至光栅化环节, 还可以完全关掉光栅化, 管线使用non-graphical stream processor. 数据通过这样的方法发送回管线, 这样就可以进行迭代重复处理. 这类型的操作对于模拟流水或者其他粒子效果很有用.
3.6 The Pixel Shader
-
在 vertex 和 geometry shader 之后, 图元被裁减并开始光栅化, 这部分在管线中相对固定了功能, 而不是可编程部分. 每个三角形处理其内的区域, 该区域内进行插值得到顶点数据. 下一步是进行pixel shader环节, OpenGL也称之为 fragment shader. 这是由于每个三角形完全或者部分覆盖了pixel's cell. 并且材质为不透明或者透明的. 在merging环节中, fragment的数据用于修改存储与像素中的内容.
-
vertex shader程序的输出为pixel shader程序的输入, 总共16个vector(每个有4个值)从vertex shader发送给pixel shader, 如果是 geometry shader, 则输出16个vector发送给pixel shader.还可以输出额外的内容给pixel shader, 例如用输入flag表示三角形的那一面可见, 片段的屏幕位置.
-
pixel shader程序执行后, 它不能将它的结果直接发送给相邻的pixel, 它使用来自顶点的插值数据和存储的常量和纹理数据, 计算只影响单个像素的结果.不过这个限制并非非常严格, 可使用图像处理技术来影响相邻像素, 见10.9
-
pixel shader 可以访问用于相邻像素的信息, 该信息是 gradient 或 derivative信息的计算.通过沿屏幕的x轴和y轴改变每个像素, 就可以得到任意值以及计算其总量. 对于不同的计算和纹理寻址非常有用. 这些 gradients 对于一些操作非常重要, 例如 filtering. 大多数GPU通过处理2x2一组像素来实现这个功能. 当 pixel shader 请求一个 gradient 值时, 返回相邻像素的差异值. 这个实现的一个结果是不能够被动态流控制(dynamic flow control)影响的部分访问gradient 信息---一组中的所有像素必须由相同的指令(instructions)处理. 即使在离线(offline)渲染系统, 也有着这基本限制. 只有 pixel shader 能够访问gradient 信息.
-
Pixel shader 程序设置用于在merging环节中merging(融合)的片段颜色. 在pixel shader中可以修改光栅化环节生成的深度值, 但不能修改stencil缓存的值,但stencil值可以传递给merge环节. 在pixel shader 执行雾计算和alpha测试.
-
multiple render targes(MRT), 每个片段可以生成多个向量, 并将其保存至不同的缓存中. 这些缓存必须有相同的尺寸大小, 一些结构(architectures)要求这些缓存有相同的位深度(bit depth), 与颜色缓存不同, 对于这些额外的内容会有一些限制. 例如不能执行反锯齿.
3.7 The Merging Stage
-
merging 环节 --- 各个片段的颜色和深度值与帧缓存组合在一起. 该环节可进行 stencil-buffer 和 z-buffer 操作, 颜色混合操作. 该环节可以进行高度配置, 例如颜色混合的方式, DX10增加了一个功能, 两个来自pixel shader的颜色可以和帧缓存颜色混合, 称之为 dual-color blending.
-
如果MRT功能可使用, 则混合可以发生在多个缓存中. DX10.1 可以对每个MRT缓存实行不同的混合操作.
3.8 Effects
-
shader都不是孤立使用的, 要配合其他shader和固定功能管线部分.
-
一些组织开发了不同的effects language, 例如 HLSL FX, CgFX, COLLADA FX, 每个effect file包装了所有需要的相关信息用于执行特定的渲染算法. 其定义了可供应用程序使用的全局参数.
-
Figure3.8 Gooch shading.
-
NVIDIA's FX Composer 2 effects system
-
DirectX 9 HLSL effect file
-
一个 Gooch shading 的简单实现
-
Gooch shading 的一部分是用表面法线和光源的位置进行比较. 如果法线朝向光源, 则使用 warm tone 着色, 否则使用 cool tone.
-
在两个用户定义的颜色进行插值. 这是non-photorealistic 渲染的一种形式.
-
Effect 变量定义于文件的开头部分, 关于相机位置的参数会自动跟踪. float4x4 WorldXf : World; float4x4 WorldITXf : WorldInverseTranspose; float4x4 WvpXf : WorldViewProjection;
-
语法形式为 type id : semantic
-
float4x4为用户定义, 用于矩阵. id 则是内置名称. WorldXf 是模型至世界转换矩阵, WorldITXf 则是前者矩阵的逆矩阵. WvpXf 为模型空间至相机裁剪空间的矩阵, 这些值由应用程序提供, 不显示于用户接口
-
用户定义变量 float3 Lamp0Pos : Position < string Object = "PointLight0"; string UIName = "Lamp 0 Position"; string Space = "World"; > = {-0.5f, 2.0f, 1.25f}; float3 WarmColor < string UIName = "Gooch Warm Tone"; string UIWidget = "Color"; > = {1.3f, 0.9f, 0.15f} float3 CoolColor < string UIName = "Gooch Cool Tone"; string UIWidget = "Color"; > = {0.05f, 0.05f, 0.6f}
-
尖括号内为注释. 大括号内为缺省值, 注释对于effect或shader编译器无效果, 但可被应用程序查询. 描述如何在用户接口内显示这些变量
-
用于shader输入和输出的数据结构定义 struct appdata { float3 Position : POSITION; float3 Normal : NORMAL; }; struct vertexOutput { float4 HPosition : POSITION; float3 LightVec : TEXCOORD1; float3 WorldNormal : TEXCOORD2; };
-
appdata定义模型上每个顶点上的数据, 用于vetex shader的输入. vertexOutput 则是vertex shader的输出和pixel shader的输入.
-
vertex shader 程序如下: vertexOutput std_VS(appdata IN){ vertexOutput OUT; float4 No = float4(IN.Normal, 0); OUT.WorldNormal = mul(No, WorldITXf).xyz; float4 Po = float4(IN.Position, 1); float4 pW = mul(Po, WorldXf); OUT.LightVec = (Lamp0Pos - Pw.xyz); OUT HPosition = mul(Po, WvpXf); return OUT; }
-
pixel shader 程序如下 float4 gooch_PS(vertexOutput IN) : COLOR { float3 Ln = normalize(IN.LightVec); float3 Nn = normalize(IN.WorldNormal); float ldn = dot(Ln, Nn); float mixer = 0.5 * (ldn + 1.0); float4 result = lerp(CoolColor, WarmColor, mixer); return result; }
-
一个 effect 文件可以有一些函数组成, 也可包括其他 effects 文件的函数
-
一个通道pass由一个vertex和一个pixel shader 组成, 以及一些用于该通道的状态设置. 一个技术technique则有一个或多个passes产生想要的效果.下面的文件则有一个technique, 该technique有一个pass technique Gooch
{ pass p0 { VertexShader = compile vs_2_0 std_VS(); PixelShader = compile ps_2_a gooch_PS(); ZEnable = true; ZWriteEnable = true; ZFunc = LessEqual; AlphaBlendEnable = false; } } -
多个 technique 可存储于相同的effect文件.用于不同的shader model(SM2.0, SM3.0等)
-
一个effect包装了相关的techniques, 一系列的方法已发展出来用于管理一系列shaders.
-
Further Reading and Resources
-
David Blythe在DirectX 10上的论文, 关于现代GPU官仙和它们的设计背后的关联
-
访问 ATI和NVIDIA开发者网站访问最新技术的信息, 免费的 FX Composer 2 和 RenderMonkey interactive shader 设计工具来试验我们的shader
-
GLSL, HLSL
-
O'Rorke的文章提供可读的introduction有效的管理shaders.
-
Cg语言提供了一个抽象层, 到处许多主要APIs 和平台. 也提供插件工具用于主要模型和动画包. Sh metaprogramming language更抽象. 为C++库用于映射相关的图形代码至GPU中.
-
如果想要高级 shader techniques, 阅读 GPU Gems 和 ShaderX 系列书籍作为开始. Game Programming Gems 书籍也有一些相关的文章.
-
DirectX SDK 有许多重要的 shader 和算法例子.
Chapter 4 Transform
What if angry vectors veer Round your sleeping head, and form. There's never need to fear Violence of the poor world's abstract storm. --- Rober Penn Warren
-
线性变换是向量加法和标量惩罚 f(x) + f(y) = f(x+y) kf(x) = f(kx) f(x) = 5x; 是一个线性变换, 为缩放变换
-
旋转变换是另一种线性变换. 所有用于3元素向量的线性变换, 可以用 3x3 矩阵表示
-
将一个固定的向量加到另一个向量上是执行一个移动变换
-
仿射变换(affine transform) --- 组合线性变换和移动. 存储与4x4矩阵中.
-
Homogeneous Notation (齐次表示法), p = {x, y, z, w}; w = 1时表示点, w = 0时表示为向量. 如果w!=1且w!=0, 则需要进行齐次化才能得到该点, 即所有的元素除以w. (x/w, y/w, z/w, 1) 矩阵为 4x4形式. 具体内容见 P905 A.4 Homogeneous Notation
-
仿射矩阵 translation, rotation, scalling ,reflection, shearing(切变矩阵), 在变换前后平行的线条依然保持平行. 至于大小和之间角度可能有所变化.
-
本章主要内容: 基本的仿射变换, 更加特殊的矩阵, 四元组, 顶点混合和变形, 投影矩阵.
-
表 4.1 T(t) 移动矩阵 Rx(p) 旋转矩阵 绕x轴旋转 R 旋转矩阵 S(s) 缩放矩阵 Hij(s) 切变矩阵 E(h, p, r) 欧拉变换 Po(s) 正交投影 平行投影至一平面或一锥体 Pp(s) 透视投影 slerp(q, r, t) slerp transform 建立一四元数的插值函数
4.1 Basic Transform
-
基本变换 translation, 旋转, 缩放, 切边, 转换链接(transform concatenation), 缸体变换, normal transform, 逆变换.
-
orientation matrix 是一个旋转矩阵.
-
trace 定义 p898
-
一个矩阵M的trace, 表示为 tr(M), 为一个矩阵对角线元素的和.
-
旋转矩阵3x3中, tr(R) = 1 + 2cos(a)
-
-
旋转矩阵的行列式为1, 且相互正交.
-
uniform(isotropic) scaling, nonuniform(anisotropic) scaling.
-
实现 uniform scaling方法, 除了修改m11, m22, m33元素, 还可以通过修改m44元素来实现. 只需要是缩放的倒数放在该处即可实现uniform scaling. 不过如果后面有 homogenization 操作, 由于产生除法所以很没有效率
-
缩放矩阵, 如果s为辅助, 则表示为反射矩阵或者镜像矩阵. 注意反射矩阵会导致一个三角形的顶点顺序由逆方向变为正方向从而导致错误的光照和backface culling. 检查一个矩阵是否有反射, 只需要检查 3x3矩阵的行列式是否小于0.
-
沿任意基本坐标系进行缩放的变换, 有三个轴fx, fy, fz表示进行缩放的标准轴, 具体方式见 P59
-
Shearing(切边)用于扭曲整个场景产生一个迷幻(psychedelic)的效果或者根据jittering创建一个 fuzzy reflection.
-
有六个基本切变矩阵: Hxy(s), Hxz(s), Hyx(s), Hyz(s), Hzx(s), Hzy(s), 第一个下标表示那个坐标被改变,第二个下标表示用于改变其他坐标的坐标
-
这个切变矩阵和3D数学图形基础的切边不同, 3D数学图形基础是一个坐标改变两个坐标.
-
Hij(s)的逆操作为 Hij(-s)
-
注意切变矩阵的行列式 |H| = 1, 便是模型在切边前后的体积不变
-
变换矩阵的乘法, 次序很重要.
-
刚体变换(rigid-body transform), 变换前后保持长度, 角度, 和旋向性(handedness)
-
与其他的转换不同, 法线的转换需要乘以伴随矩阵的转置矩阵. 伴随矩阵能够保证存在, 但是法线不能保证在之后仍然为单元长度, 所以需要单元化!
-
法线的转换是乘以变换矩阵逆矩阵的转置矩阵. 由于法线是向量, 所以平移矩阵不影响法线. 需要关心的是左上3x3的矩阵. 均匀缩放只影响法线的长度. 剩下的就是旋转矩阵, 由于旋转矩阵的逆矩阵就是转置矩阵, 转置矩阵的转置矩阵就是原矩阵. 所以直接使用原来的旋转矩阵进行变换. 如果只有平移和旋转矩阵, 则法线不需要进行单元化. 如果是均匀缩放, 则最后的法线直接除以该缩放因子, 可以将除以缩放因子的操作直接在法线变换矩阵中进行.
-
计算逆矩阵:
-
如果矩阵只是一些简单变换的相连, 则通过转换参数和改变矩阵次序来求出逆矩阵. 例如M=T(t)R(a), 则M' =R(-a)T(-t)
-
如果矩阵是正交的, 则逆矩阵为其转置矩阵
-
如果不知道具体情况, 则使用伴随矩阵. 可用Cramer'rule(常用), LU decomposition, Gaussian elimination 来计算逆矩阵
-
-
如果只是对向量进行变换, 则逆矩阵的计算仅仅考虑左上的3x3矩阵.
4.2 Special Matrix Transforms and Operations
-
Euler Transform: head(沿着y正轴), pitch(沿着x正轴), roll(沿着z负轴). 欧拉变换是三个矩阵的长发. E(h,p,r)=Rz(r),Rx(p)Ry(h)
-
万向锁问题, 旋转一定的角度造成一个自由度缺失. 例如E(h, p, r) 中的p为Pi/2 大小, 则其中的 h, r则会合并为一个, r为多余的度.
-
hairy ball theorem
-
Euler角可以使用其他的次序进行旋转, 例如 x/y/z次序, z/x/y次序用于动画, z/x/z次序用于动画和物理. 对于z/x/z, 当绕x轴旋转Pi角度时就会产生万向锁.
-
两个 欧拉角的插值很难实现
-
从一个正交矩阵中得到欧拉参数 h, p, r.
-
matrix decomposition --- 返回一个连续矩阵(concatenated matrix`)中里面不同的变换矩阵.
-
matrix decomposition 返回一系列变换的原因:
-
提取一个对象的缩放因子
-
返回特定系统需要的变换.
-
决定一个模型是否仅仅需要刚体变换
-
动画中关键帧的插值
-
从一个旋转矩阵中移除切变.
-
-
我们已经有了连个 matrix decomposition, 从一个刚体变换中得到平移矩阵和旋转矩阵, 从一个正交矩阵中得到欧拉角. 从4x4矩阵的最后一列得到平移矩阵, 从矩阵的行列式是否小于0得到其是否含有镜面变换. 从矩阵中分离出旋转矩阵, 缩放矩阵, 切变矩阵需要更多的工作.
-
Thomas 和 Goldman 提出了方法用于变换的各种类来解决matrix decomposition问题. Shoemake 改进了他们的方法用于放射矩阵. 且他的算法独立于相关的框架, 并分解(decompose)一个矩阵得到刚体变换.
-
围任意轴旋转, 假设有旋转轴 r(rx, ry, rz), 旋转角度a. 首先球基本坐标系r, s, t, 第二个轴s, 方法为取出r中最小的坐标设为0, 另外两个坐标交换, 并将第一个符号取反. 这样s点乘t 等于0, 第三个轴t由这两个轴叉乘得到. 三个轴作为行向量组成矩阵M, 表示从基本轴r, s, t旋转至标准基本轴. 三个轴作为列向量组成矩阵M', 表示从标准基本轴旋转至基本轴r, s, t. 这样得到矩阵 M'Rx(a)M, 就可以进行任意轴的旋转
-
求任意轴的旋转矩阵还有Goldman创建的方法, 具体见3D数学基本这本书.
4.3 Quaternions
-
四元数主要用于旋转和方位. 一个旋转轴和旋转角度的表示方法很容易转换至一四元数. 且四元数可用于方位间的插值.
-
四元数的定义:
-
q = (qv, qw) = iqx + jqy + kqz + qw = qv + qw
-
qv = iqx + jqy + kqz = (qz, qy, qz)
-
i2 = j2 = k^2 = -1, jk = -kj = i; ki = -ik = j; ij = -ji = k;
-
qw成为实部, qv称为虚部
-
q和i的乘法: qi = (qv X rv + rwqv + qwrv, qwrw - qv*rv), X表示叉乘, *表示点乘
-
q和i的加法: q+r = (qv+rv, qw+rw)
-
q的共轭: q^* = (-qv, qw)
-
值: n(q) = (qx2 + qy2 + qz2 + qw2)^(1/2) (平方根)
-
单元四元数: i = (0向量, 1)
-
四元数的逆: q-1 = q*/n(q)^2; --- q的共轭除以q模的平方
-
共轭规则 (q) = q; (q + r)* = q* + r; (qr) = rq
-
模规则: n(q^*) = n(q); n(qr) = n(q)n(r)
-
乘法的线性 p(sq + tr) = spq + tpr; (sp + tq)r = spr + tqr; p,q, r为四元数, s,t为标量.
-
乘法的结合律: p(qr) = (pq)r
-
单元四元数 q表示 n(q) = 1, 表示方法为 q = (sin(a)uq, cos(a)); 其中uq为单元三元素向量, 单元四元数可用于创建旋转和方位.
-
对数: log(q) = (a)uq
-
指数: q^t = sin(at)uq + cos(at)
-
-
单元四元数q, 四元数p表示进行的旋转.qp(q^-1) 表示可以进行任意轴的旋转.
-
-q和q的区别, 旋转相同的量, 但是轴的方向相反
-
两个单元四元数q,r, 用q'表示q的共轭, 则, r(qpq')r' = (rq)p(rq)/ = cpc', c = rq, 为单元四元数, 表示单元四元数q和r的连接
-
四元数转换至矩阵的公式和矩阵转换至四元数的公式见3D数学基础和笔记.
-
四元数的插值工具 s(q, r, t) = (rq-1)tq, 其中r,q为四元数. 更好的方法 slerp(q,r,t)=sin(a(1-t))*q/sin(a)+sin(at)*r/sin(a), 其中cos(a)=qxrx+qyry+qzrz+qwrw
-
由于插值算法包含三角函数运算, 效率不高, 可使用Li[771,772]来进行更快的计算方法.
-
一个曲线, 拥有恒定的速度和加速度为0, 则成为 geodesic 曲线.
-
对于多个四元数进行插值, 每一次使用下一个四元数时, 图形可能会产生巨大的变换, 造成很陡的曲线. 解决方法可以使用某种类型的spline(样条), 具体实现可见3D数学基础p159
-
求方向s至方向t的旋转路径, 1) 单元化s和t, 求出u, u=sxt/|sxu| (叉乘) 2) e = s*t = cos(2a), |sxt|=sin(2a), 而后得到四元组q=(sinauq, cosa), 2a为向量s至向量t的旋转角度, 具体公式见笔记
4.4 Vertex Blending
-
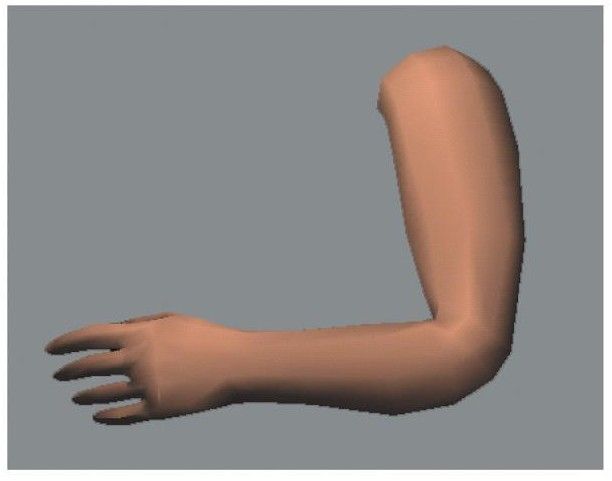
前肢和上臂之间的关节模拟, 使用Vertex blending, 注意缺点在关节的内侧会有折叠部分, OpenGL Superbible有这部分代码的实现.
-
vertex blending 还有其他的名字, skinning, enveloping 和 skeleton-subspace 变形. 最简单的形式, 前肢和上臂各自完成自己的运动. 在关节处则通过塑性"皮肤"来连接, 该处皮肤的顶点分成两部分, 分别由前肢和上臂的转换所影响. 这个技术有时也称为 stitching. 更复杂的形式中, 关节处的顶点同时被多个转换矩阵进行转换, 然后将结果通过权重值混合. 对于这样骨骼上的mesh, 成为skin(over the bones).
-
图4.11: 一个顶点混合的真实例子. 左上角图像显示了一个伸展手臂的两个骨头. 右上角显示了mesh. 图上的颜色显示该顶点被哪个骨头控制. 下面的图像显示了手臂上着色的mesh. (shaded mesh)
-
Mohr和Gleicher[889]提出了一个想法, 通过添加额外的关节实现类似 muscle bulge的效果. James 和 Twigg[599]则讨论animation skinning using bones that can squash and strtch.
-
Vertex Blending使用的公式见笔记
-
mesh中的顶点可以存储于静态缓存, 而后一次发送给GPU并重复使用. 在每一帧中, 只有bone matrices发生变化, vertex shader则计算它们作用于mesh上顶点的效果. 这种方式, 可以最小化GPU中处理和传输的数据, 并有效率的渲染这些mesh. 当整个模型的bone matrics可以统一使用时很简单. 否则整个默病必须进行分割并写复制某些bones.
-
使用 vertex shader时, 可以设置权重值在[0, 1]范围之外, 或者不需要权重总和为1. 这只能用于一些混合算法, 如 morph targets.
-
vertex blend 的缺点是会产生折叠, twisting 和 self-intersection, 一个最好的解决方法是使用 [dual quaternions]. 该方法保持原有转换的rigidity效果, 并避免"糖果纸"的扭曲形状出现在肢体上. 代价是linear skin blending的1.5倍以下, 但产生了极好的效果. 有兴趣者可查看其论文.
4.5 Morphing
-
用于动画, 一个t0时刻的3维模型和t1时刻的模型, 在t0和t1时间内, 使用一些算法能够得到其之间的"混合"模型用于过渡. 例子见图4.13
-
Morphing 有两个主要问题: vertex correspondence(顶点对应) 问题和 interpolation 问题.
-
假设两个模型之间是点点对应的, 计算morph vertex则很简单, t属于[t0, t1], p0和p1则是两个模型对应的点, 则 s = (t-t0)/(t1-t0), m = (1-s)p0 + sp1. 关于面部表情的动画, 两个表情之间有不同的顶点. 则使用 neutral face, 对不同的顶点使用"加法"操作, 加正数权重值得到一个表情, 加负数权重值得到另一个一个表情.
-
对于面部表情动画, 假设使用一个neutral模型, 标记为N, 使用一系列的表情姿势, 记为Pi i=1, 2, ... k. 有k个表情姿势. 在预处理的过程中, 计算"difference faces"(差异表情) Di = Pi - N. 而后我们可以通过公式得到morphed model M. 见笔记本.
-
morph target 是一个非常有用的技术, 使得动画制作者对动画可进行更多的控制. Lewis et al.[770] 介绍了 pose-space deformation, 组合了 vertex blending和 morph targets 技术. 硬件支持DX10使用stream-out和其他提升的功能来允许更多的target用于单个模型和单独在GPU中计算effects.
4.6 Projections
-
在渲染之前, 所有场景中的objects都必须投影至某种类型的平面或者某种类型的锥体(volume)内, 而后执行裁剪和渲染.
-
向量的w成分用于区分方向和点, 之前的转换矩阵最下面一行通常为(0, 0, 0, 1), 透视投影矩阵的最下面一行包含操作数字和进行齐次处理. 正交投影中w成分没有任何作用.
-
正交投影公式 见笔记, 仅仅抛弃z坐标.
-
正交化更常用的矩阵记为 six-tuple (l, r, b, t, n, f) 分别为, 左, 右, 底, 顶, 近, 远平面, 该矩阵通过缩放和平移AABB(由这六个平面组成)得到一围绕原点且轴对齐的立方体. 该AABB的最小角坐标为(l, b, n), 最大角坐标为(r, t, f).注意其中 n > f. 不过在Opengl的glOrtho函数中, n < f, 可以看成其内部进行了求负操作, 或者看成视觉坐标系中距离原点(眼)的距离. 在OpenGL中, 该轴对齐立方体的最小坐标为(-1, -1, -1), 最大坐标为(1, 1, , 1), 而DX为(-1, -1, 0)至(1, 1, 1). 该立方体称为canonical view volume. 其中的坐标称为 normalized device coordinates(单元化设备坐标), 转换成 canonical view volume 使得裁剪更有效率. 最后的转换矩阵见笔记 公式 4.60.
-
透视投影, 笔记有透视投影矩阵详细的求解
-
透视投影Z坐标和近平面远平面以及深度值变化的关系, 见笔记. 深度值的变化并不是线性变化.
Further Reading and Resources
-
Farin and Hansford's
[333], Lengyel's 用于建立关于矩阵的直觉了解.[761] -
透视投影则有 Hearn and Baker[516], Shirley[1172], Watt and Watt[1330]. Foley et al.[348, 349], 矩阵的基础, Graphics Gems系列[36, 405, 552, 667, 982]则有不同转换的相关算法. Golub and Van Loan's
[419] 则是用来开始矩阵技术的系列学习. -
http://www.realtimerendering.com 有许多转换的代码, 包括四元数.
-
要了解更多 skeleton-subspace deformation/vertex blending and shape interpolation 阅读 Lewis et al's SIGGRAPH paper.
-
Hart et al.[507]and Hanson[498] 提供了四元数的可视化, Vlachos and Isidoro 提供了四元数的插值. Dougan[276]则是关于在一坐标系统沿着一曲线计算四元数插值的问题.
-
Alexa[16] and Lazarus & Verroust[743] 则有许多morphing技术的介绍


下面是图形Figure3-9


下面是Figure4.11

下面是Figure4.12


下面是Figure 4.13



Chapter 5 Visual Appearance
-
大多数时候, 渲染3维模型图像的目标是 photorealism --- 非常接近相片上的真实物体.
-
本章节首先介绍一些光照和材质在真实世界中的表现, 通过使用可编程着色器来显示如何实现一个光照表面的模型. 接下来的章节内容是如何给一个渲染的模型产生一个真实的效果, 如透明, 反锯齿, 合成(compositing).
5.1 Visual Phenomena(视觉现象)
-
通过渲染如同Figure5.1那样的场景, 可有助于理解相关的physical phenomena. 如下:
-
通过太阳或者其他来源发射光(自然或人工)
-
光和其他物体之间的关系, 一部分被吸收, 一部分发散和传播至新的方向.
-
最后, 光被sensor接收(传感器, 即人类眼睛, 电子传感器或者电影)
-
5.2 Light Source
-
类似太阳光的光称为 directional lights. 这种光源的方向由光向量l(世界空间坐标西)表示. 光向量l常常定义为一个点以及和光发射方向相反的方向.
-
有向光的发射量可通过测量单位时间内垂直通过单位面积表面的光能来确定. 该发射量可称为 irradiance. 光有颜色, 所以通过颜色形式表示irradiance. 不同于绘制应用程序的颜色. RGB irradiance 的值可以超过1, 以及理论上可以取任意大的值.
-
ambient lights 环境光
-
一个表面接收的irradinance等于垂直于光的平面接收的irradinance乘以cos(a). 角度(a)为表面平面和垂直于光的平面的夹角.或者是光和法线的夹角. 其中光向量的方向定义为光发射方向的相反值, 这样光向量l点乘法线n就可以到两者夹角(a)的cos值
-
使用E表示垂直于法线向量n的 irradiance. El 表示垂直光方向的 irradiance. 则, E = El*cos(a) = El*max(n*l, 0)
-
如果有多个光源, 则表面的 irradiance 则为这些光源的 irradiance 乘以各自 cos(a)结果的和.
5.3 Material(材质)
-
场景中物体的外貌是通过将材质附在模型上来表现. 每个材质可关联至一系列着色程序, 纹理, 以及其他属性.用于模拟光照和物体之间的相互影响.
-
所有的 light-matter interactions 可分为两个结果: scattering 和 absorption(分散和吸收)
-
Scattering 不改变光的总量, 只是改变其方向.(如反射-reflection和折射-refraction, 传输-transmission), absorption 则表示光被吸收, 转换为其他能量且消失.
-
将 surface shading equations 分为两个部分: specular term 表示那些反射的光. diffuse term 表示那些经历了传输, 吸收和scattering(发散)的光.
-
光射进一个表面时, 光照通过表面的 irradiance来测了. 当光从该表面反射和散射出去时, 通过 exitance(出射度, 出射率)测量. 记号为M. exitance和 irradiance两者为线性关系. 双倍的irradiance会产生双倍的exitance. exitance除以irradiance的结果为材质的属性. 该属性值在0和1之间. 表示为RGB向量,这向量称为 surface color C. 为了区分两个不同部分的term, shading equation 分别表示为specular color(Cspec)和diffuse color(Cdiff), 这两者之和为C.表面的specular 和 diffuse colors都依赖于该表面的成分, 例如是钢铁, 颜色塑料, 黄金, 木材, 还是皮肤等等.
-
我们假设 diffuse term 没有方向. 而 specular term 则有方向. spectular term 依赖于表面的光滑度. Shading equation 会根据光滑度参数设置specular term.
-
观察者与对象的距离可以影响到surface detail(表面细节). 在图5.9中, 最坐标的图是一张叶子, 叶片经脉作为一纹理绘制. 下一张图是一簇叶子, 每个叶子作为一个简单的mesh绘制. 叶子经脉不可见, 由于叶子将反射光散射开来, 但我们可减少shading equation的光滑度(smoothness)参数. 下一张图片显示山腰的一批树, 单个叶子不可见, 每棵树作为一个三角mesh, 随机的叶子将光线散射的更加分散, 我们可进一步减少光滑度参数. 最后一张图, 则是一座带森林的山. 单个树不可见, 整个山可能作为一个mesh, shadow equation则可能建立树影重重的效果.
5.4 Sensor
-
图像的传感器有很多: 眼睛的视锥, 数字相机的感光器, 以及电影的dye particles. 这些sensors都可得到那些表面的irradiance值并产生颜色信号. 一个完整的图像系统应当包含一个暗箱和小孔来限制光的进入以及触发各个sensors. 镜头则聚焦光线使得每个sensor只接受一定区域的进入光.
-
sensor不去测量irradiance(光流的强度---所有方向--单个表面面积), 而去测量平均 radiance, Radiance是每个面积和每个进入方向光的强度. Radiance(记为L)可以看成单个光线的亮度和颜色. 表示为RGB向量形式, 理论上其值无限制. 渲染系统也会计算radiance, 但是它们使用更简化和理想化的模型.该模型可见图5.11和图5.12, 在这个模型中, 每个sensor测量单个radiance样本, 该radiance 样本沿着光线到达点p, p为透视投影转换中的中心点(个人认为可以看成观察点), 这个光线在shading equation中表示为 view vector V. 并且其长度为1.
-
sensor接收的radiance值和sensor产生的图像信号之间的关系是复杂的且非线性的. 依赖于许多因素, 且随时间和空间位置变化, 另外sensor可以感知的randiance范围通常要比显示设备可支持的范围要大得多. 需要采取一个合适的方式映射场景radiance至显示设备的radiance. 图5.10和图5.11显示了物理imaging sensors和渲染系统模型的区别. 物理每个sensors测量一个区域内一定时间间隔radiance的平均值, 这些区域进入的有向光会聚焦于镜头而后到达sensor. 而shader equation则即时地计算单个光线的radiance.
5.5 Shading
-
Shading 使用一个方程计算沿着view ray V的outgoing radiance L0, V基于材质的属性和光源
-
由于有许多公式, 具体介绍见笔记
-
图5.15, Per-vertex evaluation的shading equations 弄出的效果依赖于vertex tessellation. 三个球分别包含256, 1024, 16384个三角形
-
见Shader()着色程序用来实现公式 5.12, 得到outgoing light的radiance Lo
-
当调用Shader()时, 我们应当使用何种 frequancy of evaluation呢? 当使用顶点法线时, 即每个顶点都有其自己的法线, 就不应当使用 per-primitive evaluatio(通常称为flat shading). 这是由于其会产生 faceted look(很多小块的方块, 见图5.17左边的图), Per-vertex evaluation则进行线性插值, 其结果通常称为 Gouraud shading[435]. 在Gouraud shading的实现中, vertex shader应当传递世界空间的顶点法线和位置给 Shade()函数, 而后结果为一个插值结果, 而后pixel shader则会使用该插值结果并将其直接写入到输出中. Gouraud shading会产生合适的粗糙平面, 但是在高亮部分可能会显出人工的痕迹. 见图5.15和图5.17中间的图. 这种人工痕迹是由于线性插值作用于非线性的光照值的结果, 从镜面光的公式来看, 镜面光的结果是非线性的, 其有指数操作.
-
相对于 Gouraud shading 的另一个极端, 则为完全 per-pixel evaluation of shading equation, 称为 Phong shading, 在这个实现中, vertex shader 则会将插值后的世界空间的法线和位置通过pixel shader传送给 Shade() 函数, 在Shade()函数内部计算outgoing light的 radiance. 由于镜面光照部分是在 pixel shader里面计算, 所以不会产生人工的镜面效果. 注意插值后的法线长度可能有所变化(见图5.16), 需要在pixel shader中进行单元化, 这个方法代价昂贵. 另外一种意见就是采取中间方法, 一部分的evaluation执行per-vertex, 另一部分执行per-pixel, 顶点插值的值不会是高度非线性的值.
-
实现一个 shading equation 应当决定那部分可以简化, 计算各种表达式的频率, 以及用户如何能够修改和控制界面.
-
图5.17 Flat, Gouraud, Phong shading. flat-shaded 图像没有镜面部分, 当观察者移动时, 看起来有闪闪的方块. Gouraud shading 则高光部分处理不好.
5.6 Aliasing and Antialiasing
-
图5.18 显示的图表示反锯齿的作用, 最左边没有进行反锯齿操作, 中间的图每个像素使用了4个样本进行渲染, 最右边的图每个像素使用了8个样本(4x4的周围像素).
-
多边形和线段容易产生锯齿.关于锯齿的书籍[422, 1035, 1367]
5.6.1 Sampling and Filtering Theory
-
渲染图像的处理过程就是一个 sampling task(采样任务). 一个图像的生成就是为一个三维场景进行采样处理, 即通过一个图像为每个像素得到其颜色值. 使用纹理映射时, 在各种环境中, 纹素需要进行重采样以得到更好的结果. 在一个动画中生成一系列的图像, 该动画通常在一定时间间隔进行一次采样, 该节介绍采样, 重构造(reconstruction), 过滤(filtering), 为了简化, 大多数内容使用一维方式来解释原理, 这些概念原理也可以扩展到二维来处理二维图像.
-
图5.19 显示了一个连续的信号被采样以及采样之后通过重构进行恢复的过程, 一个连续的信号在相同的间隔中进行采样, 这样可以以数字形式描述信息, 大大减少了信息量, 而后通过重构恢复信息, 这个过程称为 filtering the sampled signal.
-
图5.20显示了一个旋转的车轮被采样的过程, 第一行的车轮是以原始信号显示出来, 第二行的采样使得车轮看起来以相反方向滚动. 第三行的采样的车轮看起来有两种方向都可以进行滚动, 第四行的车轮方向看起来和第一行一致. 这四行的采样率(sampling rate)越来越高. 图5.21显示了一个正弦波在不同的采样率下并重构之后的曲线样本. 这些采样造成的 aliasing 可称为 temporal aliasing.
-
计算机图形学的aliasing 发生在线段或多边形边缘, 闪烁的高亮光(flickering highlights), 以及当一个棋盘图案的纹理被缩小时.
-
为了能够正确采样一个信号, 这采样频率(sampling frequency)需大于被采样信号本身最大频率的两倍. 这通常称为 sampling theorem(采样定律). 而该采样频率称为 Nyquist rate 或 Nyquist limit. 其中最大频率"maximum frequency"表示该信号是bandlimited. bandlimited的意思就是有一个频率值使得该信号没有任何频率大于该值. 即在两个相邻样本之间, 信号有足够光滑的曲线.
-
当渲染点的样本时, 一个三维空间通常不可能 bandlimited. 多边形的边缘, 阴影边界, 以及其他的现象产生一个信号不连续的变化. 导致频率根本上是无限的. 即无论将样本包装的如何紧凑, 对象仍可足够的小到以至于他们根本不需要进行任何采样. 然而, 当使用点样本渲染一个场景时, 不可能完全避免 aliasing 问题. 然后, 有时我们可能知道信号何时信号是 bandlimited. 其中一个例子是当将一个纹理应用于一个表面时, 可以计算出纹理采样的频率(frequency of texture sample)以及像素的样本率(sampling rate), 如果纹理采样频率低于 Nyquist limit, 对于采样该纹理不需要进行任何特别的操作, 如果该频率太高, 则 schems to bandlimit the texture 就需要被使用 (具体见 章节 6.2.2)
-
Reconstruction (重构), 图5.22 显示了3个常用的filter. 注意所有filter和x轴包围的面积大小都为1. box filter将其最高点的值乘以样本值, 然后多个样本的结果相加得到恢复后的signal.tent filter, 则在0.0处的最大值乘以样本值, 而后多个样本的结果相加. sinc filter 也是如此, 最大值乘以样本值
-
图5.22: 左上图显示了一个 box filter, 右上则是 tent filter, 下面则是 sinc filter(需要在x轴上进行裁剪)
-
图5.23: 显示的是一个box filter用来重构一个样本信号. 这是最糟糕的 filter.最终的图形形成一个梯状的图. 使用样本点的值作为y的高度.
-
图5.24: tent filter, 也成为 triangle filter, 在相邻的点中实现了一个线性插值, 但是其显得并不光滑.
-
使用 lowpass filter来进行重构, 假设信号是一个sine波: sin(2*Pi*f), f为信号的频率. lowpass filter 移除所有高于某个频率的频率, 即该filter移除了所有信号尖锐的部分, 过滤器公式: sinc(x) = sin(Pi*x) / (Pi*x) 公式5.15, 图5.22则表述了该公式, 在[-1, 1]之间是一个高峰波, 其余范围曲线则越来越平缓. 使用sinc filter的结果见图5.25
-
在 sinc filter 中, 那些信号中的高频部分会被移除, 所有频率高于sampling rate的1/2的部分都会消除. 公式5.15中, 如果sampling frequence为1.0时, 则为perfect reconstruction filter.(采样的信号其最大频率小于1/2). 信号的频率=1/(一个波长经历的x宽度), 这里一个波长经历了2单元x轴长. 采样频率 sampling frequency 为 fs, 表示两个相邻样本的距离为 1/fs. 则 reconsturction filter 为 sinc(fs*x), 消除了所有大于 fs/2 频率的频率部分. 注意, 有图中可知, sinc filter中, sinc的filter宽度为无限长, 且有时有负数部分. 所以实际中不会采取这个filter.
-
由于box和tent filter的质量差, 以及sinc filter 不实用, 所以被广泛使用的filter functions是这些filter权衡的结果. 这些filter function 都有一部分接近于 sinc function. 但是限制了其影响的像素数, 而非上面的无限延长. 该filter十分接近sinc function的部分, 由于sinc function有负值部分, 即大于0.5和小雨-0.5处的负值部分. 由于应用程序不适合使用负的filter值, 不带 negative lobes的filter(通常关联至 Gaussian filter, 从Gaussian曲线派生或者类似该曲线)常被使用..
-
通过filter, 得到一系列连续的信号后, 在计算机图形中我们不能直接显示连续的信号. 我们可以重采样连续的信号为另一种形式, 例如放大, 或者消减信号.
-
Resampling 用于放大和缩小采样的信号. 假设初始样本点位置坐标为(0, 1, 2, ...), 两个样本点的位置间隔为单元1. 假设我们重采样后的新样本点之间间隔为a, 如 a > 1, 则为缩小信号(minification, downsampling), 如 a < 1, 则为放大(magnification, upsampling)
-
图5.26 显示了如何放大采样信号. 左边的图显示了如何通过sinc filter进行重构. 将sinc wave的最高点设置在样本点, 而后将所有的样本点形成的sinc 波相加形成的最后图案会恢复的连续信号. 右边的 resampling很简单, 只需要在所需的间隔上进行采样即可.
-
这个放大的方法不适用于缩小, 此处为缩小的公式, 其filter使用 sinc(x/a) 来创建一个连续信号. sinc(x/a) = sin(Pi*x/a) / (x/a). 单位波长的宽度为原来的a倍, 表示更多信号的高频部分被移除. 这个技术同样可用于数字图像, 用于在更低的分辨率中blurring和重采样图像. 这一点可以对照OpenGL纹理参数部分的 GL_TEXTURE_MIN_FILTER 和 GL_TEXTURE_MAG_FILTER. 放大图像时需要进行模糊化处理, 缩小图像相对简单.
-
这里的放大是指采样频率增加, 缩小是采样频率减少
-
图5.27 显示了缩小采样信号, 注意右边的 filter width 为原来的2倍, 这是由于样本的间隔也为原来的两倍.
5.6.2 Screen-Based Antiliasing
-
如果不进行采样和过滤, 多边形边缘, 阴影边缘, 镜面高亮, 以及其他颜色快速变化的地方都会产生引人注意的锯齿. 本章节讨论的算法用于提高这些情况的渲染质量, 这些算法都是基于屏幕的(screen based), 即只操作管线的输出样本, 而不需要知道渲染什么对象.
-
一些 antialiasing scheme 着重于特定的渲染图元, 有两个特殊例子就是 texture aliasing 和 line aliasing. 前者在 6.2.2 进行讨论. Line aliasing则有多种方法:
-
将线看成一个一像素宽的四边形.而后与其背景进行混合.
-
把线看成足够细, 足够透明, 其带一个 halo 的对象
-
按照 antialiased texture 那样渲染线条.
-
-
虽然有这些方法用于 line aliasing, 但是专用于 line-aliasing的硬件可以提供更快, 更高质量的渲染. 要想了解这个论题, 可以看一些文章, 如 Nelson's article[923, 924], Chan and Durand[170] 提供了 GPU-specific的方案用于 prefiltered lines(预过滤线条).
-
对于图形, 最简单的采样就是每个像素为其自身网格单元. 例如黑色三角形白色背景, 则判断其是否包括该网格的中心点, 如包括, 则该像素点为黑色, 否则为白色. 屏幕上每个网格单元使用的样本越多, 并按照一定的方法进行混合, 则能计算出更好的像素颜色.见图5.28. 右边的图一个网格单元采样四个点, 两个点在三角形外, 两个在三角形内, 则颜色为中间颜色. 注意一个网格单元为nxn大小的更小网格集合, 然后样本为这个子网格集合的子集合(个人理解). (一个网格单元看成屏幕的网格单元)
-
一般 screen-based antiliasing 方案为使用一个采样模式, 而后根据权重值将这些采样值相加得到最终的像素颜色. p(x, y) = wi*c(i, x, y) +..., i = 1, 2, 3, ..., n. n为样本数, wi为权重, c(i, x, y)为样本颜色, 对于网格上每个样本如何得到其位置都有不同的方法, 像素之间其sampling pattern可能会有不同. 在实时渲染中, 样本通常为点样本. 所以该公式的c() 函数可以看成两个部分, 第一个部分 f(i, n) 返回样本在屏幕的浮点值位置(xf, yf), 返回在该精确位置的颜色值, 根据每帧(每个应用程序)的设定, 渲染管线进行配置以计算该特定亚像素位置(particular subpixel locations)的样本, 对于wi, 所有的权重值之和为1, 实时渲染系统的大多数方法都是使用常量权重值. 例如 wi = 1/n.
-
Antiliasing 算法, 对于每个像素都计算一个或大于一个样本的算法称为 supersampling(oversampling)方法.full-scene antialiasing(FSAA)在一个高分辨率下渲染一个场景, 而后平均相邻样本值来创建一个图像. 例如, 你想要一个1000x800像素的图像, 如果你绘制一个2000x1600的无屏图像并平均每个2x2像素值于屏幕上. 这样你每个像素就有4个样本. 这个方法代价昂贵, 必须要将中间的2000x1600像素绘制出来, 且每个样本还带有Z深度缓存值. FSAA的优点是简单.另外, 还可只沿一个轴方向进行平均, 例如 1x2和2x1 supersampling. FSAA方法, 如果有nxn样本, 且要绘制一图像, 则需要绘制offscreen图像的大小为该图像的nxn倍.
-
图5.29 一些 pixel sampling scheme 的比较. 由图可知, 一个旋转的 2x2样本比直接的2x2样本效果更好, 8x8 checker样本比8x8 grid 样本更好
-
还有一种相关方法是 accumulation buffer[474, 814]. 不需要用一个巨大的无屏(offscreen)缓存, 该方法使用一个相同分辨率的缓存, 使用比所需图像更多位数的颜色. 如要得到2x2样本, 需要生成四个图像, 分别将视图在x和y方向上移动半个像素. 在网格单元中, 每个图像会生成不同的样本位置. 而后将这些图像相加并平均, 将结果发送至显示器. Accumulation buffer 是OpenGL API的一部分. 可用于实现如 motion blur的效果. 但是每一帧都需要进行渲染多次, 且将结果拷贝至屏幕, 对于实时渲染而言代价昂贵.
-
Modern GPUs 不一定有 accumulation buffer 硬件, 但我们可以通过使用像素操作混合多个图像来模拟. 如果只是用8位颜色通道用于accumulated图像, 则图像的低位字节可能会在混合中失去. 可能会导致 color banding. 使用高精度缓存(大多数硬件支持每通道10或16位)可避免该问题. 相对于FSAA, accumulation buffer还有一个优点, 就是每个像素网格单元不一定需要一个直角模式(orthogonal pattern), 每个pass对于其他pass都是独立的, 所以可以交替使用 sampling pattern, 例如使用一个旋转的正方形 pattern 如(0, 0.25), {0.5, 0}, {0.75, 0.5}, (0.25, 0.75), 有时称呼这个为 rotated grid supersampling(RGSS), 该方法对于接近于垂直和水平的边沿的反锯齿效果更好.
-
supersampling 技术生成的样本带有各自计算的shades, depths, 和 locations. 代价昂贵. 尤其是在pixel shader进行采样. 所以 DirectX不直接支持 supersampling作为反锯齿的方法. Multisampling 方法则减少这些计算的高额代价. 通过不同的频率(at differing frequancies)采样不同的数据类型. 一个multisampling算法在每个pass中每个像素都有多个样本. 并且在样本之间共享计算结果. 该技术在GPU硬件中称为 multisample antialiasing(MSAA), coverage sampling(CSAA). 在对象边沿, 高亮, 锐利的阴影中会导致颜色突然变化时, 需要额外的样本. 阴影部分可以使得其柔和, 高亮部分可以让其更宽大一些, 但是对象的边沿仍是主要的采样问题. MSAA通过每个片段计算更少的shading samples节省了时间. 所以生成的图像每个像素可能会有4个样本位置, 颜色, 和z深度值, 但是每个片段仅仅计算一次该shade.
-
如果所有MSAA positional samples之上有fragment. 该shading sample则为像素的中心点. 如果片段仅仅覆盖了一些positional samples. 则shading sample的位置需要移动(shift), 避免shade sampling离开纹理的边沿. 该位置修正成为 centroid sampling或者 centroid interpolation, 由GPU自动执行. (计算一个像素的中心点 shade sampling)
-
图5.30, MSAA sampling patterns, 用于 ATI和NVIDIA图形加速器. 绿色正方形为 shading sample的位置, 红色正方形为计算出来的样本位置, 而后该位置上的样本用于采样并保存. 分别为2x, 4x, 6x, 8x sampling. (由D3D FSAA Viewer生成)
-
MSAA的运行要比 supersampling schem 快, 这是由于 fragment 只需要被着色(shaded)一次, 它着重于在比较高的rate下对 fragment 的覆盖区域进行采样, 并共享计算出来的shade. 然而, 为每个样本存储单独的颜色和Z缓存没有必要, CSAA 的优点在更高的sampling rate下仅仅存储片段的覆盖区域. coverage for the fragment. 每个子像素(subpixel)存储其关联的片段索引. 一个有限数目entry(大小为四个或八个)的表格存储每个片段关联的颜色和z值. 例如, 一个表格存储了4个颜色和z-depth值, 每个subpixel需要有两位大小的数字来索引该表格, (个人理解, 该表格可被多个subpixel共享). 理论上, 一个像素如有16个样本, 可有16个不同的fragment. 这种情况下 CSAA可能不能正确地存储需要的信息. 可能导致人工痕迹的效果. 对于大多数数据类型来说, 在一个像素的可见shade中(in shade visible in a pixel)很少有超过4个片段是完全不同的.
-
分开存储 shading 和 depth类似于 Carpenter's A-buffer, multisampling的另一个形式, 常用于软件生成高质量的渲染. 但是没有交互速度. 在A-buffer中, 每个多边形的渲染会创建一个 coverage mask 用于每个屏幕网格单元, 表示其完全或者部分覆盖该网格单元, 见图5.31, 类似于 MSAA, 在片段的重心位置只计算一次该多边形的shade和coverage mask, 并被所有的样本所共享. 同样的方式可用于z-depth的计算. 一些系统计算两个深度值: 最小值和最大值. 还有一些会保留该多边形的坡度(slope). 所以可以在任意的样本位置推算出其确切的z-depth值. 因此两个相互相交的多边形可以被正确地渲染(coverage mask), shade, z-depth和其他信息组成一个 A-buffer片段. A-buffer不同于Z-buffer的主要地方在于一个屏幕网格单元可以一次有多个片段. 多个片段如果被隐藏则可以抛弃这些片段. 例如一个不透明的片段A有一个coverage mask表示完全覆盖片段B, 并且A的最大z-depth值小于B的最小z-depth值, 此时片段B可以完全抛弃掉. Coverage mask也可以合并起来并一起使用. 例如一个不透明片段覆盖了一个像素的一部分, 另外一个不透明片段覆盖了另一部分, 则他们的mask可以逻辑上联合起来, 并使用两者较大的那个 maximum z-depth来形成一个更大的覆盖区域. 由于该合并机制, 片段通常由 z-depth 排序. 当填满一个片段时, 就开始进行合并. 或者合并作为shading和display前的最后一步操作. 一个像素如何计算它的颜色:当所有的多边形发送给了 A-buffer, 计算了所有要存储在pixel中的颜色. 多少片段的mask确定是否可见, 然后乘以该片段颜色所表示的百分比, 而后结果相加. 见图5.18为multisampling 硬件使用的一个例子. 透明效果, 也是A-buffer的一个长处. (这里一个像素内有多个片段fragment)
-
图5.31 该多边形的一角覆盖的网格, 该图一个网格单元表示一个像素. 该网格单元分割成4x4子网格, 使用0和1表示其覆盖的子网格. 0000 0111 1111 0111
-
虽然这个看起来是一个复杂的步骤, 渲染一个三角形值至一个Z-buffer的许多机制可以重新用于实现在硬件中的A-buffer. 相对于简单的FSAA, 该方法有着更少的存储和计算需求. A-buffer为每个像素存储可变数目的片段. 该方法的一个问题就是存储的半透明片段数量没有上限. Jouppi & Chang[614]发明了Z^3算法, 每个像素有固定数目的片段, 当达到内存限制时进行合并(merge). Bavoil et al.[74, 77]概括了 k-buffer architecture的方法
-
所有的反锯齿方法都是为了每个多边形如何更好地覆盖一个网格单元(grid cell), 这里有一些限制, 一个场景的对象可能会任意的小, 以至于无法进行很好的采样. 一种避免锯齿的方法就是在该像素上随机的分布样本, 每个像素有不同的采样模式(sampling pattern), 这称之为 stochastic sampling,
-
常用的stochastic sampling 为 jittering, stratified sampling的一个形式, 假设一个像素使用n个样本, 将该样本分割成n个等大小的子区域, 且每个样本位于每个子区域的随机位置. 见图5.32, 最终的像素颜色为这些样本的某种平均值. N-rooks sampling方法则是 stratified sampling的另一种形式, n个样本位于nxn的网格内, 且每行和列只有一个样本. 该方法用于 IniiniteReality. 对于接近水平和垂直的边沿效果非常好. 对于这种结构, 每个像素都是该模式, 且样本为子像素的中心点(the same pattern is used per pixel and is subpixel-centered)
-
图5.32, 用于三个像素的典型jitter 模式. 每个像素分割成3x3的子单元, 每一个子单元有且只有一个样本, 样本在子单元内的位置随机
-
AT&T Pixel Machines 和 Silicon Graphics'VGX 以及最近的 ATI's SMOOTHVISION scheme, 使用一种叫 interleaved sampling的技术. 在ATI版本中,反锯齿硬件允许每个像素最多16个样本, 以及最多16个不同的用户自定义样本模式(sampling pattern)用于混合在一个重复的模式中. 使用交错 stochastic samping 可以最小化每个像素使用相同模式形成的锯齿现象. 见图5.33, 这个技术可看成累积缓存技术的一般化形式 例如在有数个像素间隔的像素中使用重复的sampling pattern
-
图5.33, 左边的图案, 带accumulation buffer的antialiasing, 每个像素使用四个样本, 使用重复相同的pattern. 右边, 每个像素的samplilng不都是一样的. 而是交错使用不同的sampling pattern.
-
另外一种sampling和filtering的方法, 其中最好的sampling pattern 为 Poisson(泊松) disk sampling. 不均匀分布的点(点之间的距离有个最小距离).由Poisson disk pattern 安排的无权重采样, 带有 Gaussian filtering 内核
-
一个实时反锯齿的方案就是样本影响多个像素的方案是 NVIDIA's older Quincunx 方法, 也叫做 high resolution antialiasing(HRAA), "Quincunx"意味着分配五个对象, 其中四个位于一个正方形, 第五个位于中心位置.如同六面骰子的五点. 在这个 multisampling antialiasing scheme中, 这个sampling pattern 是一个quincunx(五点形), 四个样本在像素单元的角, 一个样本在像素的中心. 见图5.29, 中心的样本权重为1/2, 角落的样本权重为1/8, 由于像素与像素之间的共享, 平均下来 Quincunx scheme每个像素只需要计算两个样本. 这个结果比每个像素两个样本的FSAA方法有更好的效果.这个模式(pattern)接近于一个两维的tent filter. 胜过box filter. Quincunx方法现在已很少使用, 更新的GPUs重新在像素之间共享单个样本的结果, 用于更高质量的信号恢复(signal reconstruction), 例如, ATI Radeon HD 2000 有 custom filter antialiasing(CFAA), 能够使用窄的和宽的tent filters延伸进其他的像素单元. 其有更好的视觉效果, 从一个更大的区域采集样本, 例如4x4, 5x5像素网格, 在写这本书的时候, Sun微系统的defunct XVR-4000是唯一的图形硬件用于实时执行这种级别的过滤
-
应当注意的是, 样本共享也用于手机图形context的反锯齿. RGSS(图形5.29)的另一种共享形式,为FLIPQUAD, 每个像素仅仅需要计算两个样本, 而RGSS需要计算4个样本. 见图5.34, 将旋转后的四边形样本顶点共享起来.
-
图5.34, 左边, 显示了一个RGSS 采样模型, 每个像素需要计算四个样本, 将样本移动到像素的边缘, 而后像素之间共享样本, 这样的方法称之为FLIPQUAD, 这样每个像素只需要计算两个样本
-
Molnar 提供了一个 sampling pattern 进行了适当的改进. 通过随时间增加样本数目来改进图像. 对于交互应用程序非常有用, 当场景不断变化时, 使用较低的样本数目, 当用户停止交互场景为静态时, 图像使用更多的样本数并显示中间的结果. 可以使用accumulation buffer来实现这个schem.
-
用于sampling的rate可以不断变化, 其依赖于被采样的场景信息, 例如, 在MSAA中, 其着重于提高样本的数量来改进边缘的检测. 同时计算的shading samples在一个很低的rate下. Persson[1007]讨论了pixel shader如何通过收集多余的纹理样本在per-surface basis改进质量, 在这种方法下, 可以选择地应用 supersampling在表面上.
-
相对于颜色的不同, 眼睛更容易感觉到密度的不同, 其中一种应用是微软的 ClearType 技术, 用于液晶显示器. LCD显示器的每个像素由3个垂直的着色矩形组成红, 绿, 蓝.可是用放大镜查看. 这个配置使得其对于水平有3倍的分辨率. 使用不同的shade填充这些subpixels. 眼睛会混合这些颜色, 红蓝的边缘觉察不出来. 见图5.35.
-
图5.35, 放大灰度反锯齿和subpixel 反锯齿版本.
-
总的来说, 用于antialiasing edge的scheme涉及范围很广, 要权衡速度, 质量, 制造成本. 没有解决方案是完美的. 但是MSAA, CSAA提供了速度和质量之间比较合理的权衡方案. 毫无疑问的, 随着时间变化, 制造商会提供更好的采样和过滤方案. 例如2007年的夏天, ATI提供了基于片段边缘检测的高质量(计算代价非常昂贵)反锯齿方案, 为 edge detect antialiasing.
5.7 Transparency, Alpha, and Compositing
-
半透明物体允许光线穿过他们, 用于半透明物体的算法分为两类 view-based effect 和 light-based effect. View-based effect 表示渲染一个半透明物体, Light-based effect 表示该物体导致光线衰减或者转移(diverted), 移植场景中其他对象被光线照射.
-
本节会涉及 view-based 透明的最简单形式, 即半透明物体看起来就像是颜色过滤器或者衰减器. 更多详细的 view-based 和 light-based效果如 frosted glass(磨砂玻璃), the bending of light(光的弯曲, 折射), 透明物体的厚度决定了光的衰减程度. 观察角度决定了光折射和传输的变化
-
Z-buffer中, 一个像素只能存储一个对象, 如果有透明物体在该像素之上, Z-buffer的值很难保证. 解决该问题的accelerator architectures有 A-buffer. A-buffer 有"deep pixels", 在渲染了所有对象之后, 存储了一些fragments, 然后将其解(resolve)成单个像素颜色(个人理解). 由于Z-buffer在加速器市场(accelerator market)中占有主要位置, 所以我们这里介绍一些在z-buffer限制之下的方法.
-
其中一种方法是给出透明的假象, 称为 screen-door transparency. 例如绘制一个透明多边形, 使用一个棋盘填充模式(checkboard fill pattern), 该方法在多边形中每隔一个像素渲染该多边形像素, 其余的像素则绘制位于该多边形之后的物体. 该方法所存在的问题有:
-
该透明物体在50%透明度的情况下效果最好. 除了棋盘模式也可以使用其他的模式, 但这些模式看起来透明效果不那么好. 有些锐利.
-
在一定区域内只有一个透明物体时渲染效果可信, 例如, 如果一个蓝色物体前有红色半透明物体和绿色半透明物体, 则棋盘模式中三种颜色只有两个颜色会显示.
-
-
这个 screen-door transparency方法的优点就是简单, 可以随时以任何次序绘制透明物体, 不需要特定硬件(除了填充模式的支持), 所有的对象为不透明物体. 该技术的思想也可用于截断纹理(cutout textures)的反锯齿, 但是只用于subpixel等级, 使用的技术为 alpha to coverage.
-
用于更一般和弹性的透明效果的方法是将透明物体的颜色和背后物体的颜色混合起来, 即为alpha blending的概念. 当一个物体渲染至屏幕, 每个像素关联至一个RGB颜色和一个Z-buffer depth. 另外一个成分alpha也用于该对象的每个像素. 用来表示该绘制物体的透明度, 公式: Co = AsCs + (1-As)Cd [over operator](5.17), Cs 为透明物体的颜色, As为透明物体的alpha值, Cd为屏幕上的像素颜色(称为 destination), Co 为结果颜色.
-
为了在场景中渲染透明物体应当要有正确的顺序, 首先, 渲染不透明物体, 然后按照从后到前的顺序绘制透明物体. 任意顺序进行混合会导致各种各样的不真实的样式. 这是由于混合公式依赖于顺序. 见图5.36, 可以修改公式, 使得可以按照从前向后的顺序绘制透明物体. 将透明表面渲染至分离的缓存, 而不首先绘制不透明物体, 该混合模式成为 under operator, 其用于 volume rendering technique. 仅当两个重叠的透明表面alpha值都为0.5, 则混合的顺序不重要, 不需要进行任何排序.
-
图5.36 左边的图形使用Z-buffer渲染带透明的模型, 这些mesh以任意顺序绘制, 产生一系列错误. 右边的图形, depth peeling提供了正确的外观. 虽然多花费了额外的通道(additional passes)
-
测试各个对象的图形中心深度并不保证其正确的排序顺序, 如相互交叉的多边形会导致排序的困难, 当GPU通过多边形给定的顺序进行渲染而不排序, 会导致绘制多边形mesh出现排序问题(sorting problems), 如果不可能进行排序或者只能部分排序, 则最好使用 Z-buffer 测试, 但在渲染透明物体时, 不会替换z-depth值. 使用这种方法, 所有的透明物体至少可以看到. 其他的技术也可以避免artifacts, 例如关闭culling, 或者渲染两次透明多边形, 第一次渲染多边形背面, 第二次渲染多边形前面
-
存在不需要应用程序自身进行排序而正确渲染透明物体的其他方法, A-buffer multisampling 方法的一个优点就是通过硬件合并已排序片段以得到高质量的透明度, 一般来说, 一个片段的alpha值可表示透明和该像素单元的覆盖范围(coverage). 而一个multisample片段的alpha值则单纯表示该样本的透明度. 这是由于其存储了单独的coverage mask.
-
透明度可以使用两个或多个depth buffers和多通道(multiple passes)来计算. 首先, 进行一个渲染pass, 以便将不透明表面的z-depth值写入Z-buffer, 而后开始进行透明物体的渲染. 在第二个渲染pass中, 修改这个深度测试, 接受的表面是这样的, 其深度值比第一个缓存中存储的z-depth更接近观察点, 而后在这些深度值取出最远的那个点作为接受的表面. 如此之后可以渲染最靠近不透明物体的渲染对象至帧缓存, 而后z-depth变为第二次pass的Z-buffer, 该Z-buffer用于下一个pass得到最靠近该值的透明表面, 具体见图5.37.
-
图5.37, 每个 depth peel pass渲染一个透明层, 左边为第一个pass, 为眼睛直接可见的层. 中间的图, 第二层(layer), 显示了每个像素上靠近观察点第二近的透明表面, 右边的图, 第三层, 显示了每个像素上靠近观察点第三近的透明表面. 第二层和第三层一次一次的靠近观察点, 前者要比后者离观察点更远, 不可见的透明表面. 最后的结果见P394, Figure 9.47
-
pixel shader 可以通过这样的方法来比较 z-depth 值, 执行 depth peeling, 依次绘制每个可见层, 该方法的一个初始化问题就是需要多少层才能够捕捉所有的透明层. 这个方法通过使用 pixel draw counter 来解决. 其告知了有多少的像素在渲染中被写入. 当一个通道中没有任何像素被渲染, 则完成了所有渲染. 或者, 当一个通道渲染的像素小于某值, 就停止peeling.
-
depth peeling为有效地方法, 由于peeled的每层都是所有透明对象的分离渲染通道(separate rendering pass), 所以该方法速度慢. Mark and Proudfoot 讨论了一个硬件结构扩展如"F-buffer"通过在流中(stream)存储和访问解决片段来该透明问题. Bavoil et al提议一个k-buffer结构也用于解决该问题. Liu et al. 和 Pangerl 则探索multiple render target的使用来模拟四层的deep A-buffer.不过该方法受限于同时读取和写入相同buffer的问题, 该问题会导致渲染的透明fragment无次序. Liu et al.提供了一个方法确保片段永远正确排序, 不过牺牲了性能. 尽管如此, 渲染 depth-peeled 透明层大概快于总帧率的两倍. 也就是说, DX10以及后来者不允许同时对相同的buffer进行读写, 所以这些方法不能够使用新的APIs
-
over operator 也可用于反锯齿边缘(antialiasing edges), 如前面章节介绍, 有一系列的算法用于发现一个像素被多边形边缘所覆盖的百分比. 不再存储coverage mask来表示该区域被对象所覆盖, 而是用一个alpha来存储, 这里有许多方法来生成一个alpha值来表示该边缘, 线条, 点的覆盖率.例如, 一个不透明的多边形覆盖了一个屏幕网格单元的百分之三十, 所以alpha值=0.3. 想象两个相邻多边形的边缘完全覆盖了一个像素, 每个覆盖了百分之50, 如果每个多边形生成了一个alpha值用于它的边缘, 则两个alpha值组合起来可能只覆盖该像素的75%.(两个alpha值都为0.5, 则第一个透明对象使用了0.5, 而后绘制第二个透明对象则为0.5*0.5=0.25), 这样会有25%的背景显示出来. 通过使用coverage mask或者blurring edge outward来解决该排序的错误. 见前面章节所讨论的内容.总的来说, alpha值可用于表示透明度, 边缘覆盖率, 或者两者都有(两个alpha值相乘)
-
例子, 使用反锯齿技术渲染一个茶壶, 表面的着色为灰褐色(0.8, 0.7, 0.1), 背景为淡蓝色(0.7, 0.7, 0.9), 表面覆盖了一个像素的60%, 则颜色为 0.6(0.8, 0.7, 0.1) + 0.4(0.7, 0.7, 0.9) = (0.76, 0.7, 0.42)
-
over operator对于混合照片或对象的合成渲染非常有用. 该过程成为 compositing, alpha值和RGB颜色值同时存储为RGBA值.
-
其他的混合操作, 但大多数不常用语实时程序, 除了一个例外加法混合(additive blending) Co=AsCs+Cd(5.18), 该混合模式的优点如有两个三角形是不需要排序(见前面的例子), 对于背景不会减弱其颜色, 使得其更明亮. 但是该模式对于透明来说, 由于不透明物体不过滤(filtered), 结果看起来不大合理, 如烟和火, 加法混合使得颜色过于饱和.
-
常用存储RGBA图像的方法是 premultiplied alphas, 在存储之前将RGB值乘以alpha值. Co = Cs' + (1-As)Cd(5.19). Cs'为premultiplied源通道(source channel), 在premultiplied RGBA中, RGB的值小于A值. 带premultiplied alpha进行渲染synthetic(人工的, 合成的)图像, 一个反锯齿不透明对象绘制于黑色背景, 假设缺省提供了一个premultiplied值, 一个白色多边形(1.0, 1.0, 1.0)覆盖了一个像素40%, 由于反锯齿, 像素值应当为(0.4, 0.4, 0.4), 该像素则应保存颜色值(0.4, 0.4, 0.4),alpha值为0.4, RGBA值则为(0.4, 0.4, 0.4, 0.4), 另一种存储图像的方式是 unmultiplied alphas. 或者叫unassociated alphas.RGB值不乘以alpha值. 这个很少用于 synthetic image的存储. 这是由于最终像素的颜色不会是多边形的颜色, 而是多边形颜色乘以alpha并和背景混合. 无论是过滤(filtering)还是混合都最好使用premultiplied. 使用unmultiplied alphas线性插值的运行不正确.
-
对于图像操作程序, unassociated alpha则对于mask一个照片非常有用, 其不影响图像内的原始数据. 支持alpha的图像格式有TIFF(两者都支持, unmultiplied, premultiplied), PNG(只支持unmultiplied).
-
一个有关alpha通道的概念是 chroma-keying, 这是来自显示产品的一个专用词, 演员在摄影中对应蓝色, 黄色或者绿色屏幕和背景混合.在电影工业中这种处理叫做 green-screen或者blue-screen matting. 这个概念是某个特定颜色被设定为透明, 一旦检测到该颜色, 背景显示. 这样通过使用RGB颜色来给图像一个外形(outline), 不需要存储alpha. 该scheme的缺点就是对象上的像素是完全非透明或者完全透明, GIF格式允许一个颜色被分配为透明色.
-
over operator 可用于在任何已绘制对象之上绘制半透明物体. 更有代表性的公式用于一个透明物体如何表现, 该公式是过滤和反射的组合. 对于过滤, 该透明物体背后的场景应当乘以该透明物体的光谱不透明度(spectral opacity), 例如, 一个黄色玻璃则用它的黄色乘以场景颜色. 以及该黄色玻璃可能反射一些光进入眼睛, 所以我们需要添加该反射光. 为了模拟这样的alpha混合, 我们需要用RGB颜色乘以帧缓存, 而后加上另一个RGB颜色. 在一个通道内完成这个则不能使用规则的alpha混合. 但可使用双颜色混合(dual-color blending). 这些在DX10中(见章节3.7). 章节7.5.3, 9.4, 9.5讨论物理修正透明度.
-
关于alpha还有一个注意要点: 该通道可以存储任意值, 例如image文件格式, 存储alpha值通常有特定含义, 例如unmultiplied或premultiplied. 在shader计算中, 该通道可以存储其他值, 例如grayscale specular contribution, 指数, 或者其他缩放因子. 理解这些可用的混合模式可以使得大量的效果得到快速的运算
5.8 Gamma Correction
-
计算出像素值之后, 需要在显示器上显示它们, 以前的数码显示使用CRT.CRT在输入电压和显示发光度(display radiance)之间有幂定律关系(Y=AX^k), 刚好和人眼的光感度相反.幸运一致的结论就是CRT输入电压的按比例编码, 其成为 perceptually uniform(感知的一致性)(两个可编码值N和N+1之间的perceptual difference为可显示范围(displayable range)上的常量值), 值的近似优化分布最小化了 banding artifacts, 当distinct值的数目非常小时非常讨厌(颜色缓存每通道存储八位或者更少), 现在CRT显示器很少见, perceptual uniformity 是使用 power-law编码的一个原因, 已有图像对相容性的需求则是另外一个原因. LCDs相对于CRTs有不同的tone response curves. 而弄出硬件修正用于提供相容性
-
transfer function 定义了一个已编码像素值和radiance之间的关系, 该function修改了power curves.(指数曲线) 该函数在0至1范围内接近一个指数曲线. Fxfer(x) 约等于 x^r, 该曲线的指数r(gamma 伽玛)
-
图5.38, 坐标的图想为单元化的场景发光度(scene radiance)和编码像素值(encoded pixel values)的函数曲线, 中间的则为encoded pixel values和单元化的显示器发光度(display radiance)的关系. 两个函数曲线相连就得到 scene radiance 到 display radiance的函数曲线
-
需要两个gamma值来描述一个成像系统(imaging system), encoding gamma描述encoding transfer function, 表示scene radiance值(由一个成像设备如相机捕捉的值)和encoded pixel value之间的关系, display gamma描述了 display transfer function.表示encoded pixel 值和displayed radiance之间的关系. 两个gamma值的乘积可以表述一个成像系统, 描述了一个 end-to-end transfer function(见图5.38), 如果乘积为1, 则dispalyed radiance可以按比例地对应scene radiance.这看起来非常理想. 也许display可以精确地复制原始场景的观察环境(viewing conditions), 然而, 事实上在原始场景的观察环境和displayed version之间有两个重要的不同点. 第一个不同点为不受任何限制的display radiance值为若干数量级, 且少于scene radiance values.(这是由于 display device 技术的限制), 第二个不同点称为 surround effect, 原始的scene radiance值填充了观察者的整个field of view(FOV,观察视角). 而display radiance值受限于一个被室内环境光照影响的屏幕.该环境光照也许非常暗淡(例如在影院里), 模糊(看电视的平均环境), 或者明亮(办公室), 两个不同的view conditions导致和原始场景在感知上的反差戏剧性地减少. 为了减少这个不同点, 使用non-unit end-to-end gamma(推荐值的范围为1.5-暗的电影院到1.125-明亮的办公室).确保display看起来就像原始的场景.
-
用于渲染目的相关gamma为encoding gamma, Rec.709 for HDTV则使用0.5的encoding gamma, 用于电视机显示. 个人计算时则使用一个标准为sRGB, encoding gamma为0.45. 该gamma用于明亮的办公室环境. 这些encoding gamma配合一个2.5的display gamma生成一个end-to-end gamma. 该display gamma为一个典型的CRT显示器.
-
例子: CMMA CORRECTION, 计算出一个像素的相对颜色(0.3, 0.5, 0.6), 要正确显示它, 则需要使用0.45=(1/2.22)的指数.得到(0.582, 0.732, 0.794), 显示时每个通道8位. 乘以255得(148, 187, 203). 其中0.45为伽玛修正.
-
通过适当的转换函数transfer function转换physical radiance值为非线性帧缓存值. 这是渲染器的责任. 在过去经常忽略这个, 导致许多的人工痕迹. 这是由于用于修正physically linear radiance值的shading的计算是在非线性值上执行, 图5.39为其中一个例子. 经过了正确的伽玛修正后, 光的颜色值就会在线性空间中变化, 而不是非线性变化.
-
图5.40, 左边的图, 白色多边形边缘黑色背景, 四个像素分别被该多边形覆盖, 且其上表示了覆盖率. 如果不使用伽玛修正, 则图形看起来如同右边那样扭曲, 看起来更暗淡一些.
-
图5.41 左边图案为经过伽玛修正的反锯齿线条. 中间的为部分修正, 右边的则无伽玛修正.
-
忽略伽玛修正同样会影响到反锯齿边缘. 例如一个多边形边缘覆盖了四个屏幕网格单元(图5.40), 这个多边形单元化的radiance为1(白色), 背景为0(黑色), 从左到有, 多边形分别覆盖1/8, 3/8, 5/8, 7/8, 如果我们使用box filter, 我们希望表示该像素单元化的scene radiance为0.125, 0.375, 0.625, 0.875. 正确的方法是在线性空间中执行反锯齿, 应用encoding transfer 函数得到四个结果值. 如果不这么做, 则所代表的scene radiance则会太暗淡. 造成边缘看起来扭曲. 该人工痕迹称为 roping. 这是由于边缘看起来像扭曲的绳索. 图5.41显示了这个效果.
-
幸运的是, 当将值写入颜色缓存时, 现代GPU可以自动应用 encoding transfer function.(典型的是sRGB transfer function), 虽然GPU能够正确的转换线性radiance值为非线性像素编码(nonlinear pixel encodings), 如果不使用或者误用该功能则会导致人工痕迹. 注意在渲染的最后阶段应用该转换(当最后一次将值写入display buffer中时), 在伽玛修正后进行处理, 则会在非线性空间中处理, 会导致结果不正确且有人工痕迹. 虽然像tone mapping(章节10.11)的操作可以修正图像的亮度平衡(luminance balance). 但是伽玛修正仍应该放在最后的阶段. 这并不意味着中间的缓存不能包含非线性编码(encoding), 但是, 缓存的内容在进行post-processing效果计算之前必须小心的转换回线性空间.
-
将encoding transfer function作用于渲染管线的输出并不足够, 也没有必要转换任何非线性的输入值为线性空间. 许多的纹理(如reflectance maps)包含的值范围为0到1, 且存储为 low-bit-depth格式, 要求非线性的编码用于避免banding. 幸运的是, GPUs可用于设置为自动转换非线性的纹理, 只需设置它们为sRGB纹理. 章节6.2.2, mipmap的生成需要考虑非线性的编码(nonlinear encoding)
-
用于编辑纹理的应用程序通常存储结果于非线性空间, 没必要和用于GPU的转换相同, 当编辑的时候注意使用正确的颜色空间, 包括显示时使用的标准(calibration of the displayed used). 任何相片纹理要求相机的标准(calibration of the camera). Mensell ColorChecker chart为标准的颜色表, 对于这些标准非常有用.
-
纹理之外其他的shader输入也可被编码为非线性地, 以及在用于shading之前要求类似的转换. 颜色常量(Color constant)(例如tint(色彩) value)经常在非线性空间中编辑. 也可以同样地应用于顶点颜色. 注意不要再线性空间中"转换"这些值.
Further Reading and Resources
-
Fundamentals of Computer Graphics, Second Edition[1172] by Shirley et al. 讨论光照, 颜色, 信号处理等
-
Blinn的文章"What Is a Pixel"[111]提供了计算机图形学的一个有趣的浏览. Walberg的书[1367] 则对于采样和过滤有详细的介绍. 还有Foley et al.的书[349]也是一样的. Blinn's Dirty Pixel书[106]则介绍过滤和反锯齿, alpha, compositing和伽玛修正.
-
Shirley[1169]则介绍samplilng patterns. Mitchell[884]则介绍了反锯齿. Smith的文章[1196]则修正了像素的误解, Smith关于采样和过滤的教程同样有趣[1194, 1195]. Gritz和d'Eon[459]则介绍了伽玛修正的问题. Poynton's Digital Video and HDTV: Algorithms and Interfaces 则介绍了不同媒体的伽玛修正, 以及其他颜色相关的主题