基于深度学习实现行人跟踪相关论文总结
基于深度学习实现行人跟踪相关论文总结
[1] Recurrent YOLO and LSTM-based IR single pedestrian tracking
本文提出了一种基于空间监督的递归卷积神经网络的热红外视觉行人跟踪新方法。我们的方法利用长短时记忆(LSTM)将YOLO深度卷积神经网络扩展到时空域。特别地,我们提出了一个新的CNN模型,它既满足精确性又满足鲁棒性,同时在TIR-VOT中保持较低的计算成本。我们的实验结果和性能比较与最先进的跟踪方法在挑战性的基准视频跟踪数据集。所提出的TIR-ROLO方法以45帧每秒的速度实时处理图像,并在遮挡场景中获得了最佳的跟踪性能。
本文提出的方法是利用CNN学习到的亮度特征,利用回归直接预测卷积层和递归单元的跟踪位置。不仅如此,我们的方法基于使用YOLO检测器的跟踪检测方法。YOLO模型以45帧/秒的速度实时处理图像,并收集丰富和健壮的视觉特征,以及初步的位置推断。我们的方法的主要贡献是基于新亮度的CNN网络可以有效地提取适合于TIR-VOT的亮度特征。
结论:在本文中,我们成功地开发了一种新的TIR行人跟踪方法。我们提出的TIR-ROLO方法表明,在维护快速FPS的同时,该方法具有更高的精度和鲁棒性。对于大多数的跟踪场景,我们的方法都能达到较高的跟踪性能。特别是,当行人目标完全被遮挡时,TIR-ROLO对其更有信心。这是因为LSTM使用了来自帧历史的信息,所以某些帧的检测失败不能影响来自后续目标的跟踪。
[2] Infrared Multi-Pedestrian Tracking in Vertical View via Siamese Convolution Network
本文提出了一种基于垂直视角的红外多行人跟踪智能算法。该算法利用改进的Siamese网络对红外图像中的行人进行快速检测和定位。基于Siamese网络的跟踪方法将跟踪问题转化为相似度验证问题,利用卷积网络对新帧特征与目标帧特征之间的相似度评分进行评估。得分最高的候选区域被认为是目标的当前位置。本文将Siamese网络与Faster RCNN相结合,实现了对多行人的跟踪。此外,将相邻帧的跟踪结果引入到当前帧的相似度评价中,提高了步行线变化时的跟踪精度。实验结果表明,该算法具有良好的鲁棒性和跟踪效果,取得了良好的竞争性能。
本文所做的改进。首先,将前一帧的跟踪结果加入到当前帧的相似度评价中,对目标模型进行间接更新。其次,使用Faster-RCNN对图像中所有的行人进行检测,识别出每个行人的状态(被跟踪、被跟踪或不再被跟踪)。然后,根据每个行人的状态,通过SiamFC实现多目标跟踪。最后,为了克服训练数据的不足,视频数据记录在实际场景中以更快的速度利用Faster-RCNN的训练数据。对于Siamese网络,可以使用许多大型可视视频数据集,如OTB、VOT等。
总结:红外多行人跟踪具有广阔的应用前景。它可以用来计算人行道上的行人流量,并估计过马路所需的绿灯时间。它还可以用来计算公共场所出入口的行人数量,从而控制人口密度。此外,监控私人场所(如酒店房间)的人数也是它的应用之一。本文提出的红外多行人跟踪算法结合Fast-Rcnn和Siamfc两种算法,充分发挥了这两种方法在各自领域的优势。最后,采用了一系列的策略来实现多行人跟踪。同时,改进了模拟评估过程,提高了行人姿态变化时的跟踪精度。根据实际情况录制的红外视频的实验结果证明了该算法的有效性和较好的性能。
[3] An Integrated Deep Learning Framework for Occluded Pedestrian Tracking
为了在各种遮挡条件下实现有效的行人跟踪,chen等人[1]提出并开发了一种基于深度学习网络的行人跟踪框架。首先,将行人检测器训练成一种基于更快的R-CNN的跟踪机制,与传统的梯度下降算法相比,该算法缩小了行人检测器的范围,有效地提高了行人检测器的准确性。第二,在目标匹配的过程中,颜色直方图和尺度不变特征变换相结合提供目标模型表达式,和一个完整的卷积网络(FCN)训练提取行人信息在目标模型中,基于一个FCN图像语义分割算法,该算法能有效地消除背景噪音。最后,在一个常用的跟踪基准上进行了大量的实验,结果表明,在各种遮挡情况下,该方法的性能优于其他最先进的跟踪器。
算法流程如下图:

本文提出并研究了如图所示的行人跟踪框架。该框架包括两个主要步骤:第一,行人和数据区域检测;第二,目标表示和目标匹配。
[4] Pedestrian Tracking Algorithm for Dense Crowd based on Deep Learning
介绍了基于深度学习的密集人群视觉跟踪算法(DTDL)的发展。本文的主要研究内容如下:(1)基于单点多盒探测器(D-SSD)的密集人群。提出D-SSD检测算法,重建行人数据集,标记人群中行人的头肩,修改候选框大小,使其接近行人头肩的比例,从而获得新的训练数据集。(2)视觉跟踪框架(基于内核相关的卡尔曼滤波器,K-KCF): KCF跟踪框架近年来更受欢迎,KCF用于视觉跟踪下常见的场景在跟踪性能和跟踪速度性能好,但有严重的目标块KCF将跟踪失败,在人口密集的背景下是不可避免的。加入卡尔曼滤波可以在很大程度上解决由于行人遮挡而导致的跟踪失败问题。本文提出了卡尔曼滤波作为辅助的K-KCF视觉跟踪框架。
[5] Unsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts
我们提出了一种基于视觉特征和最小代价提升多环的无监督多目标跟踪方法。我们的方法是基于直接向前的时空线索,这些线索可以从一个图像序列的相邻帧中提取出来,而不需要任何优势。基于这些线索的聚类使我们能够学习当前跟踪任务所需的外观不变性,并训练一个自动编码器来生成合适的潜在表示。因此,即使在没有可靠的时空特征提取的情况下,由此产生的潜在表象也可以作为强大的外观线索来跟踪大的时间距离。我们证明,尽管没有使用所提供的注释进行训练,我们的模型在具有挑战性的MOT基准上为行人跟踪提供了具有竞争力的结果。
算法流程图:

首先,提取目标检测边界盒及其空间信息,计算相邻帧检测之间的空间对应关系。基于这些简单的空间关联,检测可以使用相关聚类等聚类方法分组到tracklets中,也称为最小代价多环。其次,对卷积式自动编码器进行训练,学习检测的视觉特征。目标是学习一个潜在的空间表示,可以用来匹配相同的对象在不同的视频帧。因此,从第一步得到的空间聚类标签信息作为潜在特征的质心。在卷积自编码器中,利用聚类损失使数据样本的潜在表示形式与其中心之间的距离最小化。最后,将数据转换到经过训练的自动编码器的潜在空间中,提取成对的外观距离,对期望的不变性进行编码。这种两两出现的距离不仅用于提供邻近探测之间的附加分组信息,而且也用于长时间距离的探测。使用最小代价提升多环来计算最终的检测分组。
[6] Learning Multiple Instance Deep Representation for Objects Tracking
为了解决图像变化和遮挡可能导致跟踪性能下降的问题,提出了一种基于多实例学习(MIL)的目标跟踪方法。为了实现这一任务,我们首先在图像级手动标记视频流的前几帧,它可以指示视频流中是否有目标对象。然后,我们利用一个预先训练好的具有丰富先验信息的卷积神经网络来提取目标对象的深度表示。由于同一物体在相邻帧中的位置相似,我们引入粒子滤波来预测目标物体在特定区域内的位置。综合实验证明了该方法的有效性。
算法流程如下:

首先在图像手动标记视频流的前几帧,这可以指示视频流中是否有目标对象。然后利用预先训练好的卷积神经网络,利用丰富的先验信息提取目标对象的深度特征。我们引入粒子滤波器来预测目标在特定区域内的位置。
[7] A Modified Multi-Pedestrian Tracking System
本文提出了一种新的基于深度神经网络的多行人跟踪系统,在保证较高识别精度的同时,提高了跟踪效率。该跟踪系统由行人检测器和目标跟踪器两部分组成。我们参考了SSD检测网络的结构来设计我们自己的检测网络,用在复频域实现的图像卷积操作代替传统的池化层。然后,利用连续帧间的相似度训练深度外观模型来跟踪被检测目标。为了评估系统的性能,我们在MOT16基准上实现了该系统。探测器可以提高高达9.3%的跟踪精度,跟踪器以138Hz的频率更新,我们的扩展减少了16.2%的身份开关数量。实验结果表明,本文提出的多行人跟踪系统具有较好的实时性和准确性。
算法流程如下:
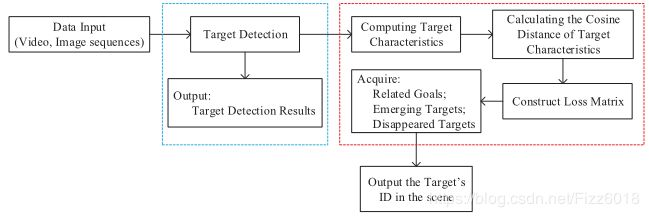
第一步:输入实时数据流(视频或图像序列);第二步:道路场景中的行人检测,找出每个场景中行人的具体位置并突出显示;第三步:训练行人的外貌模型和跟踪特征;第四步:计算检测到的目标特征和跟踪到的目标特征的余弦距离。第五步:构建损耗矩阵,完成检测数据关联;在道路场景中,我们可以得到相关的目标、消失的目标和增强的目标;第六步:输出并显示场景中每个行人的ID。
[8] Deep Alignment Network Based Multi-Person Tracking With Occlusion and Motion Reasoning,
我们提出了一种基于深度对准网络的,具有遮挡和运动推理的多人跟踪方法。具体而言,首先通过深度对齐网络对不准确的检测进行校正,在该网络中,使用对齐估计模块自动了解这些检测的空间变换。使来自对准网络的深层特征将具有更好的表示能力,并因此导致更一致的轨迹。然后,设计了一种从粗到精的方案,以构造具有空间,运动和外观信息的区分性关联成本矩阵。同时,开发了一种有原则的方法,使我们的方法能够通过运动推理和行人路线网络的重新识别能力来处理遮挡。最后,通过简单但实时的匈牙利算法解决关联问题。在MOT16,ISSIA足球,PETS09和TUD数据集上进行的全面实验验证了我们提出的跟踪器的有效性和鲁棒性。
算法工作流程如下图:

步骤1.检测和对齐:在图框处,我们首先运行自动检测器以获得具有置信度得分的所有检测结果。然后,我们提出的深度比对网络会纠正不正确的检测。此外,每个对齐检测边界框的外观特征均从我们的深度对齐网络中提取。步骤2.运动预测:基于第t-1帧的先前轨迹,通过运动模型预测每个目标在t帧的可能位置。如果第一个帧是第一帧,我们将直接使用对齐的检测结果来初始化小轨迹。步骤3.关联成本矩阵构建:为获得每个目标的空间,运动和外观信息,为设计具有区别性的关联成本矩阵,设计了从粗到精的方案。步骤4.执行数据关联:给定关联成本矩阵,我们通过简单但实时的匈牙利算法执行数据关联。步骤5.模型更新和遮挡处理:在数据关联之后,设计了一种有原则的方法来允许我们的方法实现遮挡和运动推理。首先,更新成功关联目标的外观和运动信息。然后,对于与当前检测不相关的目标,我们推断它们被遮挡或离开了场景。此外,借助拟议的对准网络强大的深度功能,一旦被遮挡的目标再次出现,我们就可以有效地对其进行重新识别。步骤6.目标对象的数量管理:对于当前检测到的,与任何现有小轨迹都不相关的边界框,我们使用它们来生成新的小轨迹。对于长时间找不到的目标对象,我们将删除它们对应的轨迹。步骤7.重复上述步骤,直到最后一帧。
[9] Pedestrian tracking by learning deep features
行人跟踪技术现已广泛应用于许多智能系统,例如视频监视,安全区域。但是许多方法都遭受照明,人体姿势或人体附属物的困扰。随着卷积神经网络(CNN)的发展,可以学习深度特征。在本文中,训练图像将被划分为多个子区域以减少诸如袋子之类的人类附带品的影响。其余区域几乎是固定区域。然后,将这些固定区域输入到CNN网络中以学习深度特征。为了使用不同大小的训练图像进行复制,CNN网络架构开发了任意大小的合并层。然后,这些深度学习的特征向量可用于行人识别。在我们的工作中,光流用于行人跟踪。实验结果表明,该方法可以有效地实现行人跟踪。
[10] Online tracker optimization for multi-pedestrian tracking using a moving vehicle camera
尽管最近已经提出了基于卷积神经网络(CNN)的单对象跟踪方法,但是就实时处理而言,用于多行人跟踪任务的CNN的在线学习是一个重大负担。但是,由于从CNN中提取的特征具有很好的表示能力,并且具有较高的泛化能力,因此为了减少学习时间,本文采用浅层预训练CNN作为特征提取器代替了对象跟踪器。这项研究使用具有预训练的CNN输出功能的随机蕨(RF)分类器,可以使问题在计算上易于处理且具有鲁棒性。但是,大的随机蕨(RF)分类器需要大量的内存和计算复杂性,并且在多行人跟踪的情况下仍然是在线学习的负担。因此,我们引入了师生模型压缩算法来选择一些最佳蕨类跟踪器,从而减少了在线学习时间。学生随机蕨(RF)跟踪器的在线学习的优势在于,它可以自适应地更新跟踪器,以在有限的时间内抵御各种变化(如姿势和光照以及部分遮挡)的鲁棒性。所提出的算法已成功应用于从移动摄像机捕获的基准视频序列,该摄像机包括多个摆姿势的行人。具体而言,与其他现有技术相比,该算法可产生更准确的跟踪性能。
算法流程如下图:
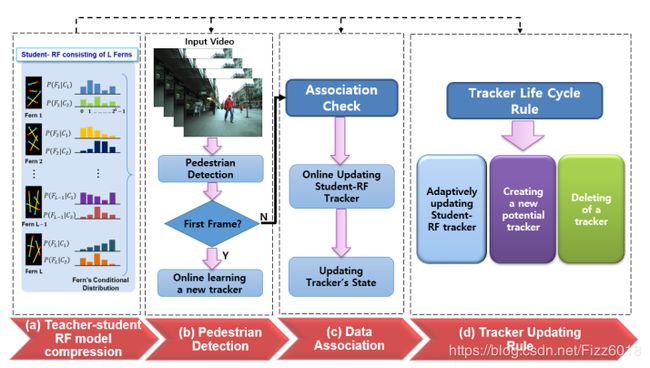
基于跟踪器关联的学生RF跟踪器培训和在线更新的过程:(a)由L个随机厥跟踪器组成的师生RF模型压缩;(b)行人检测;(c)更新学生RF跟踪器模型和数据状态后的状态关联检查;(d)用于创建和删除跟踪器的跟踪器生命周期规则。
论文Reference
[1]S. Yun and S. Kim, “Recurrent YOLO and LSTM-based IR single pedestrian tracking,” 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea (South), 2019, pp. 94-96.
[2]G. Shen, L. Zhu, J. Lou, S. Shen, Z. Liu and L. Tang, “Infrared Multi-Pedestrian Tracking in Vertical View via Siamese Convolution Network,” in IEEE Access, vol. 7, pp. 42718-42725, 2019.
[3]K. Chen, X. Song, X. Zhai, B. Zhang, B. Hou and Y. Wang, “An Integrated Deep Learning Framework for Occluded Pedestrian Tracking,” in IEEE Access, vol. 7, pp. 26060-26072, 2019.
[4]G. Yang and Z. Chen, “Pedestrian Tracking Algorithm for Dense Crowd based on Deep Learning,” 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2019, pp. 568-572.
[5]Ho K, Keuper J, Keuper M. Unsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts[J]. arXiv preprint arXiv:2002.01192, 2020.
[6]L. Chunyu, L. Gang, Learning Multiple Instance Deep Representation for Objects Tracking, J. Vis. Commun. Image R. (2019), doi: https://doi.org/10.1016/j.jvcir.2019.102737
[7]Gong Y, Chi J, Yu X, et al. A Modified Multi-Pedestrian Tracking System[C]//2019 Chinese Control Conference (CCC). IEEE, 2019: 8501-8506.
[8]Q. Zhou, B. Zhong, Y. Zhang, J. Li and Y. Fu, “Deep Alignment Network Based Multi-Person Tracking With Occlusion and Motion Reasoning,” in IEEE Transactions on Multimedia, vol. 21, no. 5, pp. 1183-1194, May 2019.
[9]Huang H, Xu Y, Huang Y, et al. Pedestrian tracking by learning deep features[J]. Journal of Visual Communication and Image Representation, 2018, 57: 172-175.
[10]Kim S J, Nam J Y, Ko B C. Online tracker optimization for multi-pedestrian tracking using a moving vehicle camera[J]. IEEE Access, 2018, 6: 48675-48687.