机器学习项目案例 简单的数字验证码自动识别
本篇文章将实现一个识别验证码的案例。
基本思路及步骤:
1.先写一个关于验证码生成器的代码,得到一个有关验证码的库
2.对验证码库中的验证码图片进行处理并对其分割
3.训练数据,得到模型
4.对未知的验证码图片进行预测
由于目前的验证码的形式比较多样,但是验证的思路都是类似的,因此就先从简单的数字开始进行识别。我们先需要写一个验证码生成器,生成验证码库。
验证码需要有5个数字,并且有不同的颜色,还要再图片上加一些噪点和一些随机的线。
代码如下:
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import random
def getRandomColor():
"""
获取一个随机颜色(r,g,b)格式的
:return:
"""
c1 = random.randint(0, 255)
c2 = random.randint(0, 255)
c3 = random.randint(0, 255)
if c1 == 255:
c1 = 0
if c2 == 255:
c2 = 0
if c3 == 255:
c3 = 0
return(c1, c2, c3)
def getRandomStr():
"""
获取一个随机数字,每个数字的颜色也是随机的
:return:
"""
random_num = str(random.randint(0, 9))
return random_num
def generate_captcha():
# 获取一个Image对象,参数分别是RGB模式。宽150,高30, 随机颜色
image = Image.new('RGB', (150, 50), (255,255,255))
# 获取一个画笔对象,将图片对象传过去
draw = ImageDraw.Draw(image)
# 获取一个font字体对象参数是ttf的字体文件的目录,以及字体的大小
font = ImageFont.truetype("ARLRDBD.TTF", size=32)
label = ""
for i in range(5):
random_char = getRandomStr()
label += random_char
# 在图片上写东西,参数是:定位,字符串,颜色,字体
draw.text((10+i*30, 0), random_char, getRandomColor(), font=font)
# 噪点噪线
width = 150
height = 30
# 画线
for i in range(3):
x1 = random.randint(0, width)
x2 = random.randint(0, width)
y1 = random.randint(0, height)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=(0, 0, 0))
# 画点
for i in range(5):
draw.point([random.randint(0, width), random.randint(0, height)], fill=getRandomColor())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x + 4, y + 4), 0, 90, fill=(0, 0, 0))
# 保存到硬盘,名为test.png格式为png的图片
image.save(open(''.join(['captcha_images/', label, '.png']), 'wb'), 'png')
# image.save(open(''.join(['captcha_predict/', label, '.png']), 'wb'), 'png')
if __name__ == '__main__':
for i in range(150):
generate_captcha()
运行程序之后生成150个验证码图片,会将验证码保存到文件夹中,相当于一个库,如下:

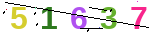


生成验证码之后,我们需要对验证码图片进行处理,具体处理的步骤如下:
1.对验证码图片二值化,首先把图像从RGB 三通道转化成Gray单通道,然后把灰度图(0~255)转化成二值图(0,1)。
2.对二值化验证码图片进行降噪处理,把干扰的点和线去掉
3.对处理后的验证码图片进行分割,根据像素格,把图片中的所有(5个)数字,分别保存到对应的0~9文件夹下。
具体代码如下:
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import os
def binarization(path):
img = Image.open(path)
img_gray = img.convert('L')
img_gray = np.array(img_gray)
w, h = img_gray.shape
for x in range(w):
for y in range(h):
gray = img_gray[x, y]
if gray <= 220:
img_gray[x, y] = 0
else:
img_gray[x, y] = 1
return img_gray
# plt.figure('')
# plt.imshow(img_gray, cmap='gray')
# plt.axis('off')
# plt.show()
def noiseReduction(img_gray, label):
height, width = img_gray.shape
for x in range(height-1):
for y in range(width-1):
cnt = 0
if img_gray[x, y] == 1:
continue
else:
for i in [-1, 0, 1]:
n = x
n += i
if n < 0:
n = 0
for j in [-1, 0, 1]:
m = y
m += j
if m < 0:
m = 0
if img_gray[n, m] == 0:
cnt += 1
if cnt <= 4:
img_gray[x, y] = 1
plt.figure('')
plt.imshow(img_gray, cmap='gray')
plt.axis('off')
plt.savefig(''.join(['clean_captcha_img/', label, '.png']))
def img_2_clean():
captchas = os.listdir(''.join(['captcha_images/']))
for captcha in captchas:
label = captcha.split('.')[0]
img_path = ''.join(['captcha_images/', captcha])
im = binarization(img_path)
noiseReduction(im, label)
def cutImg(label):
labels = list(label)
img = Image.open(''.join(['clean_captcha_img/', label, '.png']))
for i in range(5):
pic = img.crop((100*(1+i), 170, 100*(1+i)+100, 280))
plt.imshow(pic)
seq = get_save_seq(label[i])
pic.save(''.join(['cut_number/', str(label[i]), '/', str(seq), '.png']))
def get_save_seq(num):
numlist = os.listdir(''.join(['cut_number/', num, '/']))
if len(numlist) == 0 or numlist is None:
return 0
else:
max_file = 0
for file in numlist:
if int(file.split('.')[0]) > max_file:
max_file = int(file.split('.')[0])
return int(max_file)+1
def create_dir():
for i in range(10):
os.makedirs(''.join(['cut_number/', str(i)]))
def clean2cut():
clean_img = os.listdir(''.join(['clean_captcha_img/']))
for img in clean_img:
label = img.split('.')[0]
cutImg(label)
if __name__ == '__main__':
img_2_clean()
create_dir()
clean2cut()
二值化并且降噪后的图片如下:

切割后的图片会保存在对应的数字文件夹中,

比如切割后的数字 6 如下:

1.把数据带入逻辑回归进行建模
(1)把切割好的数据,按照x(二位数组),y(一维数组)的方式传入logisticRegression.fit()函数进行拟合
我们可以通过网格搜索(GridSearch)来进行调参
(2)通过joblib包,把模型保存到本地
2.得到模型后,进行图像验证
(1)根据之前处理图像的步骤,重复操作新的图像
(2)对切割好的每个图像,独立的进行预测
(3)把最后预测结果进行拼接
注意在代码中需要导入之前写的函数,
代码如下:
import os
from PIL import Image
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib
from CAPTCHA.captcha_logistic import *
def load_data():
# 假设20*5像素块构成 20*5 = 100
# [[11...1111]
# [111...111]
# ....
# [11111111]]
# X = [[11111.....11111]] 100位 Y = [0]
X, Y = [], []
cut_list = os.listdir('cut_number')
for numC in cut_list:
num_list_dir = ''.join(['cut_number/', str(numC), '/'])
nums_dir = os.listdir(num_list_dir)
for num_file in nums_dir:
img = Image.open(''.join(['cut_number/', str(numC), '/', num_file]))
img_gray = img.convert('L')
img_array = np.array(img_gray)
w, h = img_array.shape
for x in range(w):
for y in range(h):
gray = img_array[x, y]
if gray <= 240:
img_array[x, y] = 0
else:
img_array[x, y] = 1
img_re = img_array.reshape(1, -1)
X.append(img_re[0])
Y.append(int(numC))
return np.array(X), np.array(Y)
def generate_model(X, Y):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3)
log_clf = LogisticRegression(multi_class='ovr', solver='sag', max_iter=10000)
# 利用交叉验证选择参数
# param_grid = {"tol": [1e-4, 1e-3, 1e-2],
# "C": [0.4, 0.6, 0.8]}
# grid_search = GridSearchCV(log_clf, param_grid=param_grid, cv=3)
# grid_search.fit(X_train, Y_train)
log_clf.fit(X_train, Y_train)
# 将模型持久化
joblib.dump(log_clf, 'captcha_model/captcha_model.model')
def get_model():
model = joblib.load('captcha_model/captcha_model.model')
return model
def capthca_predict():
path = 'captcha_predict/unknown.png'
pre_img_gray = binarizaion(path)
noiseReduction(pre_img_gray, 'unknown')
# cut image
labels = ['0', '1', '2', '3', '4']
img = Image.open(''.join(['clean_captcha_img/unknown.png']))
for i in range(5):
pic = img.crop((100*(1+i), 170, 100*(1+i)+100, 280))
plt.imshow(pic)
pic.save(''.join(['captcha_predict/', labels[i], '.png']))
result = ''
model = get_model()
for i in range(5):
path = ''.join(['captcha_predict/', labels[i], '.png'])
img = Image.open(path)
img_gray = img.convert('L')
img_array = np.array(img_gray)
w, h = img_array.shape
for x in range(w):
for y in range(h):
gray = img_array[x, y]
if gray <= 220:
img_array[x, y] = 0
else:
img_array[x, y] = 1
img_re = img_array.reshape(1, -1)
X = img_re[0]
y_pre = model.predict([X])
result = ''.join([result, str(y_pre[0])])
return result
if __name__ == '__main__':
X, Y = load_data()
generate_model(X, Y)
model = get_model()
result = capthca_predict()
print(result)
将要预测识别的验证码图片:
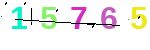
最终识别结果:

可以看到对给出的验证码图片进行了成功识别。