【论文阅读】Attention 机制在脱机中文手写体文本行识别中的应用
论文信息:
作者: 王馨悦,董兰芳
( 中国科学技术大学计算机科学与技术学院,合肥230027)
E-mail: wxy66@ mail. ustc. edu. cn
该方法在针对具有语义信息的CASIA-HWDB2.0-2. 2 数据集上字符准确率达到了95. 76%,比传统的encoder-decoder 框架提升了12.83%.
关键词: 文本行识别; 脱机中文手写体; Attention 机制; LSTM
中图分类号: TP391 文献标识码: A 文章编号: 1000-1220( 2019) 09-1876-05
与中文印刷体相比,手写体字符的书写随意性大,缺乏规范性. 出自不同书写者的同一类汉字在字形、结构上都会有明显的差异; 并且相邻汉字之间会存在粘连,增加了识别的难度. 与英文手写体相比,汉字种类繁多,根据GB2312-80 标准,汉字共有6763 个,其中包括一级汉字3755 个,二级汉字3008 个,同样给中文手写体识别增加了难度.
由于近几年深度学习不断发展,利用深度学习实现文本行识别是一个极具潜力的研究方向,Messina R等人首次提出将MDLSTM-RNN 网络应用到中文手写体文本行识别,在CASIA-HWDB数据集上进行训练,在ICDAR2013 竞赛数据集上进行测试,字符准确率为83.5%.Wu Y C 等人在MDLSTM-RNN 网络基础上做了改进,用分离的MDLSTM-RNN 进行中文手写体文本行识别未加语料库的前提下准确率提升了3.14%. 可以看出利用神经网络进行文本行识别准确率相对较低,有较大的提升空间. 但是由于汉字种类较多,目前成功应用在中文手写体文本行识别中的神经网络较少,因此找到合适的神经网络去拟合大类别的离线中文手写体文本行识别,仍然是一个值得研究的问题.
相比基于切分策略的文本行识别,利用神经网络可以避免字符切分.,实现真正无分割端到端离线中文手写体文本行识别. encoder-decoder是较常见的框架,广泛应用在语音,图像,视频等领域.
- 沈华东等人:文本摘要的自动提取
- Deng Y 等人:将该方法用到了公式识别中;
- O Vinyals 等人 :将encoder-decoder框架应用到图片描述中,
- Xu K 等人首次提出在encoder-decoder框架添加Attention 的思想,应用到图片描述中. 图片描述是指给定一张图片,计算机会自动输出一句话来描述这张图片.
对于离线中文手写体,则是给定一张中文手写体图片,输出对应的可编辑的中文汉字. 通过类比,我们可以将离线中文手写体的识别看作是获得该张图片的描述.
基于Attention机制的encoder-decoder 比传统的encoder-decoder 框架具有更好的识别结果; 同时也表明encoder-decoder 框架可以成功应用到大类别中文手写体文本行识别中. 本文的网络结构与目前成功应用到大类别中文手写体文本行识别中的MDLSTM-RNN网络,具有以下优点:
- 本文不需要利用单字符和中文语料库来扩充中文手写体文本行数据集;
- 也不需要利用其他语言的手写体进行预训练. 本文直接利用已有数据集CASIA-HDWB2. 0-2. 2,在CNN + BLSTM+ Attention + LSTM 网络结构下直接进行训练,并取得了较好的实验结果.
0.网络结构:
基于Attention 机制的encoderdecoder框架,具体的结构为CNN + BLSTM + Attention +LSTM:
cnn用于提取特征,然后将特征图的列向量依次输入到BLSTM(双向长短时记忆模型)进行编码 ,,再将BLSTM 输出结果结合Attention,输入到长短期记忆模型(LSTM)中进行解码:
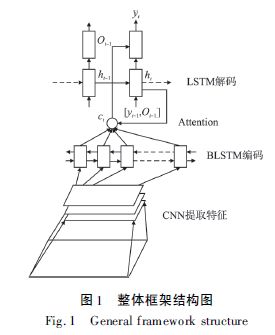
模型:
输入: 经过预处理后的离线中文手写体图片
输出: 识别结果
- 图片预处理,按照图片大小分成33 类;
- For epoch = 1…15:
- 将预处理后的图片输入CNN;
- 将步骤3 得到的特征图,按列依次输入BLSTM 进行编码;
- 将编码后的结果,结合解码时当前时刻隐藏层的输出,作为全连接层的输入,全连接层后连接tanh 激活函数;
- 把步骤5 的输出采用softmax 进行归一化,得到每列对应的概率值,也称为Attention;
- 将步骤4 得到的编码结果和步骤6 得到的Attention,对应相乘得到新的编码结果;
- 将步骤7 的输出和当前时刻的LSTM 隐藏层的输出作为全连接层的输入,全连接层后用tanh 激活函数;
- 将步骤8 的结果用softmax 归一化,归一化后的结果作为词典中字符的概率;
- 目标函数采用条件概率的负对数似然.
汉字识别特征提取:
CNN 1 卷积神经网络 CNN 由若干层卷积层、池化层和全连接层组成. 卷积神经网络和全连接神经网络相比,具有局部感知野、权值共享和下采样这三个结构特性,使得卷积神经网络提取到的特征对输入数据的平移、旋转、缩放都具有较高的鲁棒性。
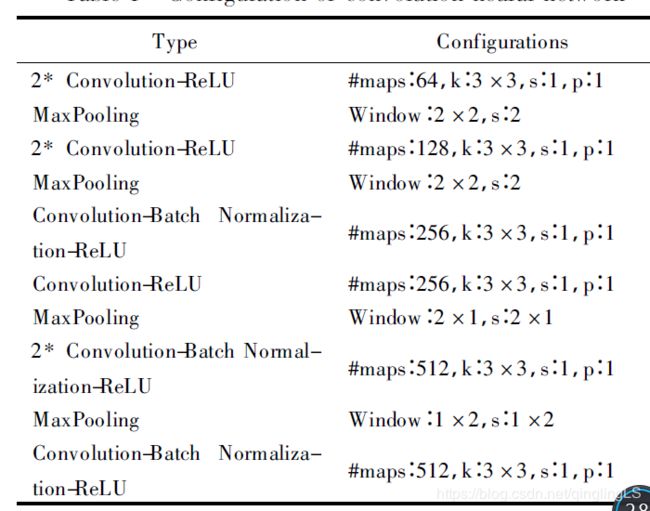
语义信息提取和编码BILSTM:
BILSTM 双向循环神经网络 2 ,这个是LSTM的变种。
设计了隐藏层为256。
LSTM是对RNN(循环神经网络)的改进,使得它可以处理一些长距离依赖,例如: 明天会下雨,记得带伞,这里的伞的图片信息不明确,经过语义上的学习,就知道这里有伞的概率比较大,而下雨和伞就存在长距离依赖。
BILSTM 则可以表示当前时刻的输出不仅与前面的序列相关,还和后面的序列相关。例如: 针对中文手写体文本行识别,假如有一张图片的标签为“我的笔记本坏了,我想买一个新的笔记本”. 如果使用LSTM,从前向后学习,如果“买”这个字的图片信息不明确,根据“坏”这个字,可能学到是“修”,“扔”,“买”等. 但如果使用BLSTM,可以从后向前学习,根据“新”这个字,此时学到“买”的概率会变大. 所以针对具有语义信息的文本行,BLSTM具有更强的学习能力,
语义信息解码LSTM:
LSTM隐藏层为512. 初始学习率为0.1
解码的目的是将图像特征转换为识别结果。Vinyals O 等人3直接用LSTM 进行解码,它是将编码后的向量直接输
入到LSTM 中. 即无论我们当前学习的是什么,它的输入都是整张图片的信息,也就是说 h t h^t ht必须包含原始句子中的所有信息. 但是当句子比较长时, h t h^t ht没办法存放这么多信息,此时便会造成精度下降.
h t h^t ht是BILSTM的最终输出,由输出门和单元状态共同控制。如果想深入了解具体计算过程,可以点击这里---->>>链接待补充
或者自己看原论文。
软边缘attention
为了解决这个问题,Xu K 等人4提出了一种Attention 机制,分为Hard-Attention 和Soft-Attention,
hardAttention 也就是必须直接选定整个区域,或者不选择;soft-attention则是可以选择软边缘,例如图中的红点的小区域就是attention的可视化 。
在使用Attention 机制之后,每一时刻的输入不再是整张图片的信息,而是让decoder 在输入序列中自由的选取特征.

例如在图(a)里,正在识别别“天”时,“天”所在图片的位置的Attention 值会比较大.
attention计算方法:(选读)
e t = a ( h t , { V h , w } ) e_t = a(h_t,\{V_{h,w}\}) et=a(ht,{Vh,w}) α t = s o f t m a x ( e t ) \alpha_t = softmax(e_t) αt=softmax(et) z t = β ( { V h , w } , α t ) ( 9 ) z_t =\beta (\{V_{h,w}\},\alpha_t) (9) zt=β({Vh,w},αt)(9)
a a a 操作用的是Luong M T 等人5 的方法(详细点击–>>>链接待补充) V h , w V{h,w} Vh,w表示特征图第h行,w列组成的向量, h t h_t ht表示LSTM在t时刻的输出,softmax 表示softmax 函数, α t α_t αt就是Attention,它表示特征图中元素对应的权值. β 同样采用Luong M T 等人的方法, z t z_t zt 是decoder 的输入.
解码部分(选读)
o t = t a n h ( W , c [ h t , z t ] ) ot = tanh( W,c[h_t,z_t]) ot=tanh(W,c[ht,zt]) h t = L S T M ( h t - 1 , [ y t - 1 , o t - 1 ] ) ht = LSTM( h_{t - 1},[y_{t - 1},o_{t - 1}]) ht=LSTM(ht-1,[yt-1,ot-1]) p ( y t + 1 ∣ y 1 , … , y t , V ) = s o f t m a x ( W o u t o t ) p( y_{t + 1} | y_1,…,y t,V) = softmax( W^{out}o_t) p(yt+1∣y1,…,yt,V)=softmax(Woutot)
其中 p ( y t + 1 ∣ y 1 , … , y t , V ) p( y_{t + 1} | y_1,…,y_t,V) p(yt+1∣y1,…,yt,V) 表示生成 y t + 1 yt + 1 yt+1 的所有候选字符的概率, t a n h tanh tanh 表示 t a n h tanh tanh激活函数,W,c 表示权重参数,向量 z t z_t zt 和 h t h_t ht 横向连接来预测 y t + 1 y_{t + 1} yt+1 的概率.
在 t t t 时刻的解码,需要 t - 1 t - 1 t-1 时刻解码的输出和编码后
的特征图作为输入.首先根据公式计算特征图中列向量对应的权重,再根据公式(9)计算出加权和,将加权和的结果作为 t t t 时刻LSTM 的输入,最终求出 t t t 时刻生成的字符类别.
1.数据集
CASIA-HWDB2.0-2. 2 数据集.
该数据集下共有5019页图像,分割为52230 行和139414 个汉字,共有2703 类.52230 行又分为训练集和测试集,其中41780 行作为训练集,10450 行作为测试集. 并且所有图像均为灰度图像.
数据集获取和下载:
CASIA-HWDB脱机手写汉字数据集以及申请表下载
CASIA Online and Offline Chinese Handwriting Databases
预处理:
crnn的训练是有一些技巧的,需要预处理,例如:—>> cnn+bistm+lstm的训练技巧
算法评估方法:
由于本文采取的是端到端的识别,输入文本行图片,直接输出整行的识别结果. 对于一行的识别结果,如果直接将它和标签从前往后进行比对,这种方法计算出的正确字符数是不准确的. 所以采取了字符串编辑距离( Levenshtein Distance)来计算识别结果和标签的相似程度. 对于两个字符串,定义一套操作方法来把两个不相同的字符串变得相同. 如果两个字符串相同,那么它们的编辑距离为0; 具体的计算方式如下:
- 替换一个字符,编辑距离加1;
- 插入一个字符,编辑距离加1;
- 删除一个字符,编辑距离加1.
最后当识别结果和标签两个字符串相同时,此时的编辑距离就是识别结果中出错的字符的数目,
训练和迭代:
初始学习率为0.1.总共训练了15 个迭代
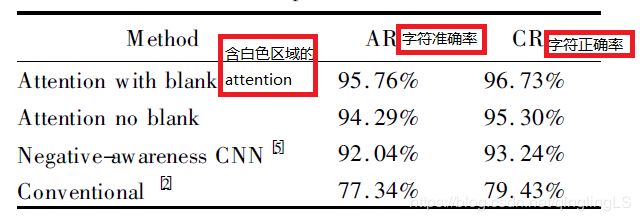
含有空格标签的字符准确率可以提升,例如:大#家#好,
用# 表示blank空格,这样可以在一定程度上抑制前后的联系.
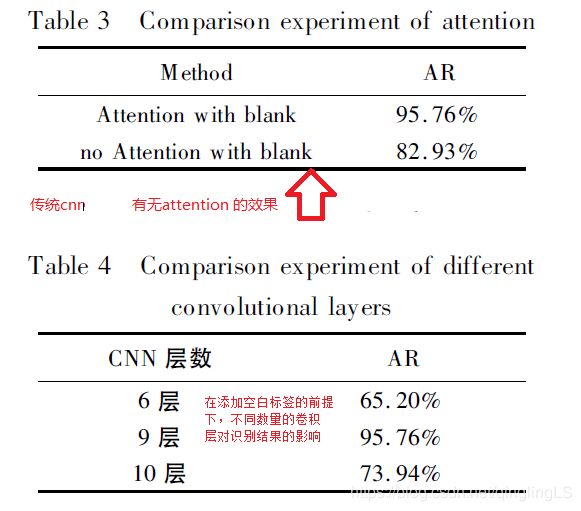
6层的卷积层可能存在欠拟合的情况,而10 层的卷积层可能又存在过拟合的情况.
如果要进一步改进,可以:
将CASIA-HWDB1.0-1.2 中孤立手写字符,转换为带有语义信息的中文手写体图片,然后再修改成合适的网络结构重新进行训练.
LeCun Y,Bengio Y,Hinton G. Deep learning[J]. Nature,2015,521( 7553) : 436-444. ↩︎
Schuster M,Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing,1997,45 ( 11 ) :2673-2681. ↩︎
Vinyals O,Toshev A,Bengio S, et al. Show and tell: aneural image caption generator[C]/ /Computer Vision and Pattern Recognition ( CVPR) ,2015: 3156-3164. ↩︎
Xu K,Ba J,Kiros R, et al. Show, attend and tell: neural image caption generation with visual attention[C]//International Conferenceon Machine Learning( ICML) ,2015: 2048-2057. ↩︎
Luong M T,Pham H,Manning C D. Effective approaches to attention-based neural machine translation[C]/ /Empirical Methods inNatural Language Processing( EMNLP) ,2015: 1412-1421. ↩︎