一张图让你轻松搞定yarn资源调度流程
1。yarn概述
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
2.Yarn的重要概念
1)yarn并不清楚用户提交的程序的运行机制
2)yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3)
yarn中的主管角色叫ResourceManager
4)
yarn中具体提供运算资源的角色叫NodeManager
5)这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序……
6)所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
7)Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
3.yarn资源调度全流程(核心
,图片看不清的话,可以下载本地查看
)
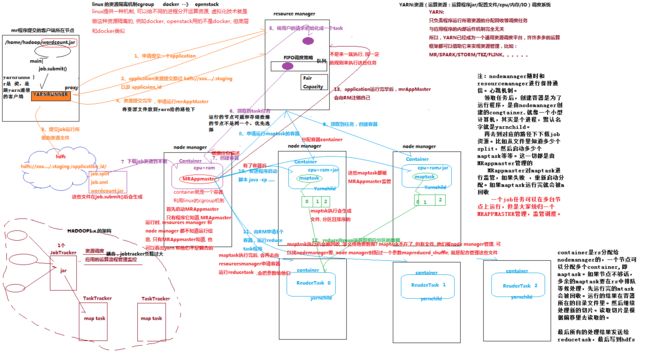
工作机制详解
(
0
)
Mr
程序提交到客户端所在的节点(
MapReduce
)
(
1
)
yarnrunner
向
Resourcemanager
申请一个
application
。
(
2
)
rm
将该应用程序的资源路径返回给
yarnrunner
(
3
)该程序将运行所需资源提交到
HDFS
上
(
4
)程序资源提交完毕后,申请运行
mrAppMaster
(
5
)
RM
将用户的请求初始化成一个
task
(
6
)其中一个
NodeManager
领取到
task
任务。
(
7
)该
NodeManager
创建容器
Container
,并产生
MRAppmaster
(
8
)
Container
从
HDFS
上拷贝资源到本地
(
9
)
MRAppmaster
向
RM
申请运行
maptask
容器
(
10
)
RM
将运行
maptask
任务分配给另外两个
NodeManager
,另两个
NodeManager
分别领取任务并创建容器。
(
11
)
MR
向两个接收到任务的
NodeManager
发送程序启动脚本,这两个
NodeManager
分别启动
maptask
,
maptask
对数据分区排序。
(
12
)
MRAppmaster
向
RM
申请
2
个容器,运行
reduce task
。
(
13
)
reduce task
向
maptask
获取相应分区的数据。
(
14
)程序运行完毕后,
MR
会向
RM
注销自己。
二:mr的运行模式
MAPREDUCE程序运行模式
2.2.1 本地运行模式
-
mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行(yarn的本地模拟器)
-
而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
config.set("fs.defaultFS","hdfs://hadoop102:8020") //这是集群,也可以不用配置,因为配置文件里指定了该配置
config.set( mapreduce.framework.name=local
);//本地,本地里可以不用配置,默认配置lib文件里就是local.
- 怎样实现本地运行?写一个程序,不要带集群的配置文件(
本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数
)
- 本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
如果在windows下想运行本地模式来测试程序逻辑,需要在windows中配置环境变量:
%HADOOP_HOME% = d:/hadoop-2.6.1
%PATH% = %HADOOP_HOME%\bin
并且要将d:/hadoop-2.6.1的lib和bin目录替换成windows平台编译的版本(要安装hadoop的windows版本)
2.2.2 集群运行模式
- 将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
- 处理的数据和输出结果应该位于hdfs文件系统
- 提交集群的实现步骤:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver inputpath outputpath
B、直接在linux的eclipse中运行main方法
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置,一般集群上yarn-site.xml都已配置了。如果不是本地连接的话,不需要配置)
config.set("fs.defaultFS","hdfs://hadoop102:8020")
config.set(mapreduce.framework.name","yarn")
config.set("yarn.resourcemanager.hostname","hadoop103");
方法二:也可以将core_site.xml等配置文件直接复制到工程下,也行。
C、如果要在windows的eclipse中提交job给集群,则要修改YarnRunner类
总结:所谓的hadoop jar ,yarn jar ,java -jar 本质都是启动jar包中main方法。