【paper笔记】Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
科研生活开始了! 精读的第一篇paper
好久没有这么仔细地读一篇paper,以前读都只是知道大概意思就好了,很多细节选择忽略,因为很多时候论文只是需要知道这篇论文在干什么就好了(比如水报告的时候(ˉ▽ˉ;)…)。
即使是精读,我对作者为什么这样做的原因还是有很多不解
笔记里有一些自己的理解还有疑问,还请批评指正!
- 论文基本信息
- 0 摘要 Abstract
- 1介绍 intruduction
- 1.1 Top-N recommendation
- 1.2 前人工作的weakness
- 2 FURTHER RELATED WORK
- 3 PROPOSED METHODOLOGY
- 3.1 Embedding Look-up
- 3.2 Convolutional Layers
- 3.2.1 Horizontal convolutional Layer
- 3.2.2 Vertical Convolutional Layer
- 3.3 Fully-connected Layers
- 3.4 Network Training
- 3.5 Recommendation
论文基本信息
WSDM 2018
Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding.Jiaxi Tang (Simon Fraser University); Ke Wang (Simon Fraser
University)
解决的情景:
基于序列环境下的推荐系统(有用户id,并且有用户的点击序列流)
0 摘要 Abstract
Top-N顺序推荐将每个用户建模为过去交互的一系列项目,旨在预测用户在**“不久的将来”可能会交互的前N个排名项目**。
相互作用的顺序意味着顺序模式起着重要的作用,序列中较新的项目对下一个项目的影响更大。
在本文中,我们提出了卷积序列嵌入推荐模型(Caser)作为解决此要求的解决方案。想法是在时间和潜在空间(in the time and latent space)中将一系列最近的项目嵌入到“图像”中,并使用卷积滤波器将顺序模式作为图像的局部特征。这种方法提供了一种无固定且灵活的网络结构,用于捕获一般偏好(general preferences)和顺序模式( sequential patterns)。
我提出的疑惑:潜在空间(latent space)到底指的是什么?
1介绍 intruduction
1.1 Top-N recommendation
Top-N推荐系统(Top-N recommendation)大多数都只基于用户的日常喜好(general preferences),而没有关心事件序列的发生新进关系(the recency of items)。
存在着两种用户表现:
General preferences,例如一直喜欢Apple手机的人大概率不会去购买三星手机。这代表着用户的长期和静态的行为。Sequential patterns,用户下一个交互的item或动作更可能和用户最近的活动或最近交互的item有关。例如:买了新手机,下一个动作很有可能是购买手机壳之类的。这代表着用户的长期和动态的行为。
1.2 前人工作的weakness
最早研究的top-N sequential Recommendation的工作是基于马尔可夫链的,L-阶马尔可夫链式是基于前L个动作进行推荐的top-N。基于马尔可夫链的研究有PFMC、Fossil等,本质上,马尔科夫链就是通过最大化似然估计来学习一个item-to-item的转移矩阵。
存在的limitation:
Fail to model union-Level sequential patterns
没有考虑联合的序列影响,有些研究考虑了联合的影响,但只是单纯地把各种item的影响进行简单加权和操作,不足以体现一个整体的影响。Fail to allow skip behaviors
没有允许跳过的序列行为影响,也就说过去的行为不是立即对下一个动作会有影响,可能会对后续的几个动作产生影响。作者举了例子:一个游客依次在机场、旅店、餐馆、酒吧和旅游景点办理手续,虽然机场、旅店之后紧接着的不是旅游景点,但直觉上他们是有着比较强的关联的,相反紧接着的序列餐馆、酒吧对旅游景点的影响倒是没那么大。
作者为了证明以上观点做了前期实验,得到了下面的表:
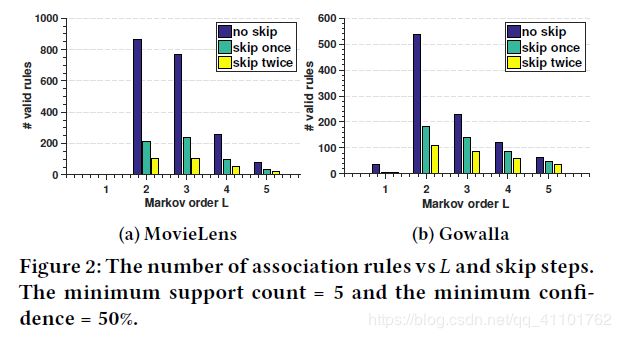
以下示意图很好地展示了weakness:
a)是一般推荐系统考虑的点
b) 、c) 两种是没有考虑到的情况

2 FURTHER RELATED WORK
这部分说的也是各种方法的缺陷,RBM,CNN,RNN,temporal recommendation等…
缺陷有:搜索空间太大、没有考虑序列的影响等
3 PROPOSED METHODOLOGY
作者提出了Caser模型(ConvolutionAl Sequence Embedding Recommendation),这个模型的创新点在于我们将前L个item表示为一个L×d的矩阵E,d是latent dimensions,矩阵E的行保持着交互物品的顺序。然后我们将这个矩阵E视为L个物品的一个image,通过不同的卷积过滤器去学习 image的局部特征(也即在潜在空间中学习sequential patterns)。
设计模型的目标在于:
(1)通过使用水平和垂直两个过滤器Caser可以捕捉到point-level,union-level和skip behaviors;
(2)Caser可以同时对用户的general preferences 和sequential patterns进行一个建模,并且在单个统一框架中概括了几种现有的state-of-the-art的方法。
Caser 由三个部分组成:
- embedding layer
- convolutional layer
- fully-connected layer
对于每个用户u,我们从用户序列Su中提取每L个连续项作为输入,并将它们的下一个T个项作为目标,是通过在用户序列上滑动一个大小为L +T的窗口来实现的,每个窗口都为u生成一个训练实例,它由一个三元组(u、前L项、后T项)表示。
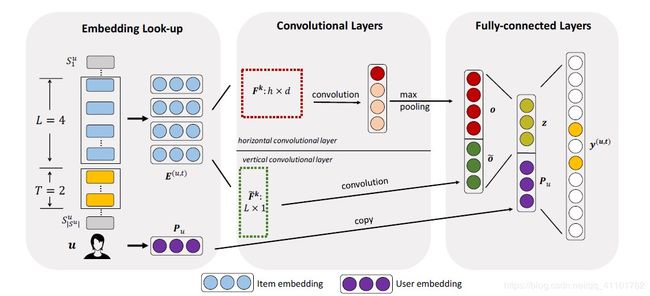
3.1 Embedding Look-up
Caser通过将用户的前L个item进行embedding(第i个物品的embedding表示为Qi)送入神经网络去捕捉顺序特征(sequence features)。
Embedding look-up操作就是将L个物品的embedding堆叠在一起,生成一个矩阵E(u,t),u指的是用户u,t指的是time step
E(u,t)是L✖d维的向量:

Along with the item embeddings,对每个用户u我们还有一个embedding Pu∈R^d ,代表着潜在空间中的user features,也就是用户固有的general preferences
我提出的疑惑:这里的Pu如何得到? 预训练参数?
3.2 Convolutional Layers
我们的方法利用了CNN卷积滤波器在捕获图像特征和自然语言处理的局部特征方面。借用在文本分类中使用CNN的想法,我们的方法将L×d矩阵E视为潜在空间中前L个项的“图像”,并将顺序模式视为此“图像”的局部特征。这种方法可以使用卷积滤波器来搜索顺序模式。
下图显示了两个“水平滤波器”,它们捕获了两个联合级别的顺序模式。这些滤光片以h×d矩阵表示,高度为h = 2,总宽度等于d。他们通过在E的行上滑动来拾取顺序模式的信号。例如,第一个过滤器通过在潜在维度中具有较大的值(机场和酒店具有较大的值)来拾取顺序模式 “((机场,酒店)→长城)”。
同样,“垂直滤波器”是一个L×1矩阵,它将在E的列上滑动。与图像识别不同,这里没有给出“图像” E,因为所有项目的嵌入Qi必须与所有滤波器同时学习。
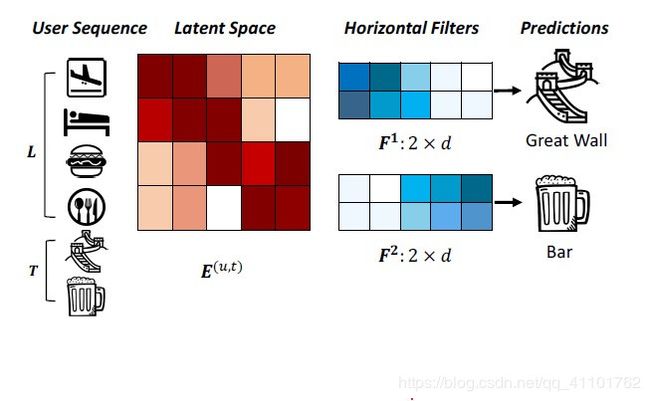
3.2.1 Horizontal convolutional Layer
这里我们需要n个水平过滤器,每个过滤器表示为F^k∈R(h×d)h∈{1,…,L}
F^k:指的是第k个过滤器;h是过滤器的高度;d是物品的embedding维度
如果我们选择前L个物品L=4,则h∈{1,2,3,4},如果每个h有两个过滤器的话,那我们就有了8个过滤器。
F^k从矩阵E的top到bottom滑动,从水平维度上与the items i 进行交互,1 <= i <= L-h + 1。第i次的卷积操作如下:
![]()
最终F^k的卷积结果是:
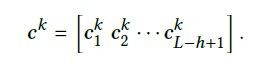
然后,我们将最大池化操作应用于C^k
,目的是从特定过滤器产生的所有值中提取最大值。最大值捕获可以从过滤器提取的最重要的特征。因此,对于该层中的n个滤波器,输出值o∈R^n
![]()
水平滤波器通过其embeddings E与每个后续h items交互。嵌入和滤波器均被学习以最小化对目标项目的预测误差进行编码的目标函数。通过滑动各种高度的滤波器,无论位置如何,都会拾取到明显的信号。
因此,可以训练水平滤波器以捕获具有多个联合尺寸的联合级模式union-level patterns。
3.2.2 Vertical Convolutional Layer
使用代字号(〜)在该层中,假设有n个垂直滤波器〜F^k ∈ R^L×1 每一个垂直滤波器〜F^k 通过在矩阵E上滑动d次(从左到右),产生一个垂直的卷积结果〜C^k :

对于内积计算来说,很容易证明这个结果等价于矩阵E的L行上的加权求和,其中〜F^k为权重:

利用垂直过滤器,我们可以学习汇总先前L个项目的嵌入值,类似于Fossil方法加权总和以汇总前L个项目的潜在表示。不同之处在于,每个过滤器〜Fk的行为都像不同的聚合器。因此,类似于Fossil,这些垂直过滤器通过对先前项目的潜在表示进行加权求和来捕获点级顺序模式(point-level sequential patterns)。虽然Fossil为每个用户使用一个加权总和,但我们可以使用〜n个全局垂直过滤器为所有用户生成〜n个加权和〜o∈R^d〜n:
![]()
由于垂直过滤器的用途是聚合,因此它们与水平过滤器有一些区别:
(1)每个垂直过滤器的大小固定为L×1。这是因为E的每一列对我们来说都是潜在的,一次与多个连续的列进行交互是没有意义的。
(2)不需要对垂直卷积结果应用最大池化操作,因为我们希望保持每个潜在维的聚合。因此,该层的输出为〜o
3.3 Fully-connected Layers
我们将两个卷积层的输出连接起来,并将它们馈入一个完全连接的神经网络层,以获取更多高级和抽象的特征(features):

其中W∈R^d×(n + d〜n)是将级联层投影到d维隐藏层的权重矩阵,b∈R^d是对应的偏置项,而ϕa(·)是全连接层的激活函数。 z∈R^d是卷积序列嵌入,它编码L个先前项目的所有顺序特征。
为了捕获用户的一般偏好,我们还查找用户的嵌入Pu,并将两个d维向量z和Pu连接在一起,并使用| I |节点将它们投影到输出层,写为:
 其中b0∈R^| I | 和 W0∈R^| I |×2d 分别是输出层的偏置项和权重矩阵。如第3.4节所述,输出层中的值yi^(u,t)与用户u在
其中b0∈R^| I | 和 W0∈R^| I |×2d 分别是输出层的偏置项和权重矩阵。如第3.4节所述,输出层中的值yi^(u,t)与用户u在step t.z时与item i交互的可能性有关。z旨在捕获短期顺序模式,而用户的 embedding Pu 将捕捉到用户的长期的普遍偏好。在这里,出于以下几个原因,我们将用户将Pu嵌入到最后一个隐藏层中:
-
正如我们将在3.6节中看到的那样,它可以具有推广其他模型的能力
-
我们可以将模型的参数与其他广义模型的参数一起进行预训练。这种预训练对于模型性能至关重要。
全连接层是把前面的局部特征重新通过权值矩阵组成一个完整的图,相当于还原了之前的 items 流。
3.4 Network Training
为了训练网络,我们将输出层的值y^(u,t)转换为概率:

其中σ(x)= 1 /(1 + e−x)是Sigmoid型函数。令C^u = {L + 1,L + 2,…,| Su |}是我们要为user u进行预测的时间步长的集合。数据集中所有序列的可能性为:
为了进一步捕获跳过行为,我们可以通过替换上面的等式来立即考虑下一个T个目标项目D^u t = {S^u t,S^u t + 1,…,S^u t + T}。取似然性的负对数,我们得到目标函数,也称为二进制交叉熵损失:
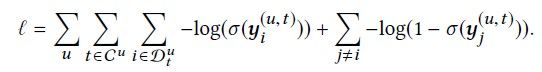
根据先前的工作[6,21,32],对于每个目标项i,我们在第二项中随机采样了几个(在我们的实验中为3个)否定实例j。
模型参数Θ= {P,Q,F,〜F,W,W0,b,b0}通过最小化训练集上述方程中的目标函数进行学习,而超参数(例如d,n,〜n,L,T)通过网格搜索在验证集合上调整。我们采用了一种随机梯度下降(SGD)的变体,称为自适应矩估计,以100的批量大小,可以更快地收敛。为了控制模型的复杂性并避免过度拟合,我们使用两种正则化方法:对所有模型参数应用L2范数和在完全连接的层上使用drop ratio为50%的Dropout技术。我们用MatConvNet 实现了Caser。整个训练时间与训练实例的数量成正比。
3.5 Recommendation
获得训练有素的神经网络后,为了在time step t上为用户提供recommendation,我们采用了latent embedding P^u,并提取了由等式E(u,t)给出的它最后L个项的嵌入作为神经网络输入。我们选择在输出层y中具有最高值的N个项目作为用户推荐。
向所有用户推荐的复杂度为O(| U || I | d),其中卷积运算的复杂度被忽略。请注意,目标项目数T是模型训练期间使用的超参数,而N是模型训练后推荐的项目数。