爬虫-携程酒店信息抓取降妖除魔(上)
#上篇主要讲的具体酒店详情页的信息提取(特别价格),下篇主要讲页面酒店数量及相关信息的提取
#整个爬取过程确实很多坑,需要一步步去破解实现,需要耐心
1.首先找到需要的数据源就很不容易,ajax加载,json数据在html处,最后还需要对html(string)进行解析抓取
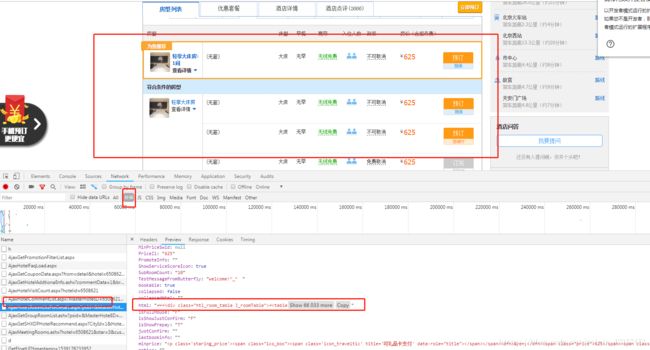
2,爬取提交requests数据headers、data参数也是需要深入分析,get提交参数都在链接里,每个酒店链接就不一样,这也是个坑,最后发现data不用上传很多参数甚至不需要,主要在链接里去掉不必要参数,发现就留下hotel=***就可以了,这样也可以爬取各个酒店只要换个酒店参数id

3.json接口提取出的html通过lxml转化成网页结果再通过xpath进行提取,下面是返回的网页结构需要进一步分析提取数据,这里发现xpath的class熟悉就行,能把对应床型,有无早餐和价格都一下提取出来,最后再zip组合起来

4.具体代码和保存到CSV文件,
import requests
import json
from lxml import etree
import csv
url="http://hotels.ctrip.com/Domestic/tool/AjaxHote1RoomListForDetai1.aspx?hotel=2231618"
headers={
"Connection":"keep-alive",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Content-Type":"application/x-www-form-urlencoded; charset=utf-8",
# "Cookie": "_ga=GA1.2.25372685.1539076865; _gid=GA1.2.1539921360.1539076865; _RF1=221.218.168.188; _RSG=ryKEnlOSLL4qNWeEkzhjwA; _RDG=282a15c45e05fc25103ed14f6c9745cbd3; _RGUID=4555718b-f139-4f35-aead-afdb8ea205f4; GUID=09031090310571422408; _abtest_userid=3f592186-4c0c-4207-ad2f-b720376f06c5; gad_city=96617ee7af8aedd02bbece8583e0066e; MKT_Pagesource=PC; appFloatCnt=3; manualclose=1; HotelCityID=1split%E5%8C%97%E4%BA%ACsplitBeijingsplit2018-10-10split2018-10-11split0; HotelDomesticVisitedHotels1=2231618=0,0,4.8,1741,/200h0r000000hem7x1D5D.jpg,&444199=0,0,4.7,4639,/fd/hotel/g2/M07/15/9F/Cghzf1VJ1UmAdbriAA2Cyd_f31A280.jpg,&452197=0,0,4.5,3875,/200s0d0000006ux7571BA.jpg,&1231824=0,0,4.4,722,/200e0o000000fbr2m36B1.jpg,&1436736=0,0,4.2,3301,/hotel/1000/83/c140ded9c6204366a52f9c7ced8cfd82.jpg,; ASP.NET_SessionId=0mudotd1ppl5zfvvjfbttjbx; OID_ForOnlineHotel=15390768645321d63kcn1539143026071102002; _gat=1; _jzqco=%7C%7C%7C%7C1539076865506%7C1.20073654.1539076865437.1539143028915.1539143032367.1539143028915.1539143032367.undefined.0.0.50.50; __zpspc=9.4.1539143028.1539143032.2%234%7C%7C%7C%7C%7C%23; _bfi=p1%3D102003%26p2%3D0%26v1%3D68%26v2%3D0; _bfa=1.1539076864532.1d63kcn.1.1539135698560.1539143022775.8.69.212094; _bfs=1.4",
"Host": "hotels.ctrip.com",
"If-Modified-Since": "Thu, 01 Jan 1970 00:00:00 GMT",
"Referer": "http://hotels.ctrip.com/hotel/2231618.html",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"
}
html=requests.get(url,headers=headers)
html=json.loads(html.text)
lists=[]
string=html["html"]
new_html=etree.HTML(string)
#xpath 的normalize-space 这个方法可以去掉空格换行这些
fangxin=new_html.xpath('normalize-space (//*[@id="518829"]/a[2]/text())')
# fangxin=new_html.xpath('//*[@id="518829"]/a[2]/text()')[0].strip()
chuangxin=new_html.xpath('//*[@class="col3"]/text()')[1:]
zaocan=new_html.xpath('//*[contains(@class,"col4")]/text()')[1:]
jiage=new_html.xpath('//*[@class="base_price"]/text()')
print("*"*18)
#zip方法三个lists合并一起,python3需要外面加list才能打印
new_list=list(zip(chuangxin,zaocan,jiage))
lists.append(new_list)
print(lists)
#保存为csv文件
with open("jiudianprice.csv", "w", encoding="utf-8",newline="") as f:
k = csv.writer(f, dialect="excel")
k.writerow(["床型", "早餐","价格(元)"])
for cc in lists[0]:
cc = list(cc)
k.writerow(cc)

