Elastic:使用 Elastic 有监督的机器学习进行二进制分类
Elastic Stack 7.6 版本提供了端到端机器学习管道所需的最后一部分。 以前,机器学习专注于具有异常检测功能的无监督技术。 但是,在7.x发行版中已经发布了一些功能。 在 7.2 中,Elasticsearch 发布了用于将原始索引转换为特征索引的 transforms。 然后7.3、7.4和7.5分别发布了异常值检测(outlier detection),回归(regression)和分类(classification)。 最后,在7.6中,你可以将回归和分类模型与推理提取处理器一起使用,以丰富文档。 所有这些共同完成了端到端机器学习管道的循环。 这些全部在弹性堆栈里实现。
机器学习的种类:

从上面的图中,我们可以看出来机器学习分为两种:
- Unsupervised:无监督的学习
- Supervised: 监督学习
Anomaly Detection 和 Outlier Detection 是数据驱动的,不需要用户指出正常还是异常,这称为无监督机器学习。无监督机器学习是使用户熟悉ML的重要第一步
但是,有一类用例需要通过使用带有标签数据的模型来训练,因此需要一些用户参与,以便你可以使用它对未标签数据进行预测,这就是所谓的 “监督学习”。借助监督学习,你可以训练机器学习模型以基于标记数据学习模式。
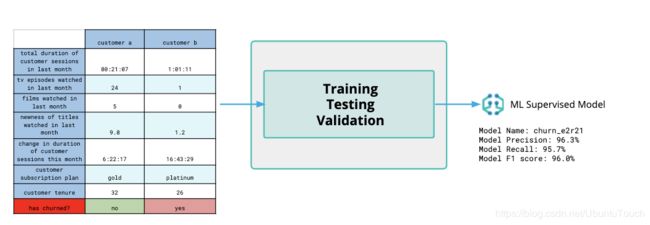
我们可以在监督学习模式下,利用现有的已经被证实的例子作为范例进行学习,从而建立一个 ML Supervised 模型。我们也可以利用这个模型对未来的数据进行推断:
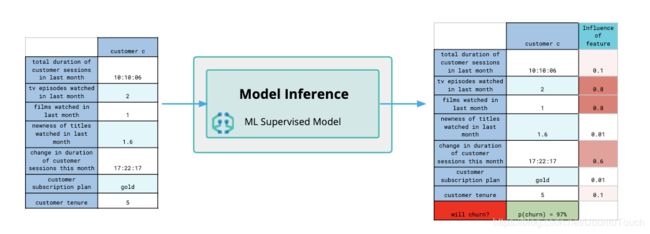
为什么要监督学习?
监督式机器学习根据标记的数据(labeled data)训练模型。这与从未标记数据中学习的无监督模型学习相反。在数据框分析中,我们为你提供了无需了解基础算法即可创建监督模型的工具集。然后,你可以使用经过训练的模型对未观察到的数据进行预测(通过推理)。该模型将通过培训获得的知识应用于预测。
为什么用它代替异常检测?异常检测(无监督学习的一个示例)非常擅长基于时间序列数据的学习模式和预测指标。这在许多用例中都很强大,但是如果我们想通过检测可疑域来识别不良行为者怎么办?自动检测语言并应用适当的分析器进行更好的搜索怎么办?
这些用例需要更丰富的功能集以提供准确的预测。他们也有从中学习的已知示例。就是说,存在一个训练数据集,其中的数据被标记了正确的预测。转换提供构建复杂功能集所需的工具。数据框分析可以训练有监督的机器学习模型。我们既可以部署特征生成,也可以使用监督模型在流数据上进行生产。
监督学习示例:二进制分类
让我们从头开始构建和使用二进制分类模型。 不要被吓到。 无需数据科学学位。 我们将使用 Elastic Stack 中的构建块来创建功能集,训练模型并将其部署在摄取管道中以执行推理。 使用提取处理器,可以在对我们的数据进行索引之前对模型的预测进行丰富。
在此示例中,我们将根据客户元数据和呼叫日志的功能预测电信客户是否会流失。 我们将使用流失客户和未流失客户的示例作为培训数据集。
设置环境
Elasticsearch 及 Kibana
你可以在我们的 Elastic Cloud 上生产免费试用的集群。如果你想使用 Elastic Stack 的本地部署,请参阅我之前的文章:
-
如何在Linux,MacOS及Windows上进行安装Elasticsearch
-
如何在Linux,MacOS及Windows上安装Elastic栈中的Kibana
由于机器学习是需要白金版的一个功能,我们需要在本地的部署中启动白金版。
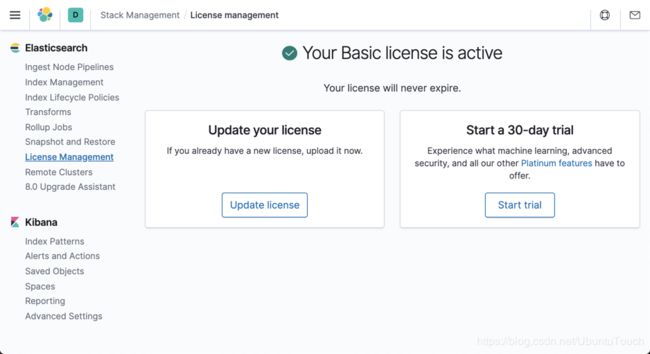
这样我们就完成了白金版的试用配置。
实验数据
我们今天的实验数据将采用 Customer churn demo。这里的实验数据有两个部分:
- calls.csv
- customers.csv
数据来自各种来源的数据集:openml,kaggle,Larose2014。该数据集被分解为订单项,并添加了随机特征。 电话号码和其他数据是捏造的,与真实数据的任何相似之处都是偶然的。
导入数据
你可以参阅我之前的文章 “Kibana: 运用Data Visualizer来分析CSV数据” 来把上面的两个 csv 的数据集导入到 Elasticsearch 中。应该是非常直接的。当我导入完 calls.csv 及 customers.csv 后,我们可以在 Kibana 中查看到如下的两个索引:
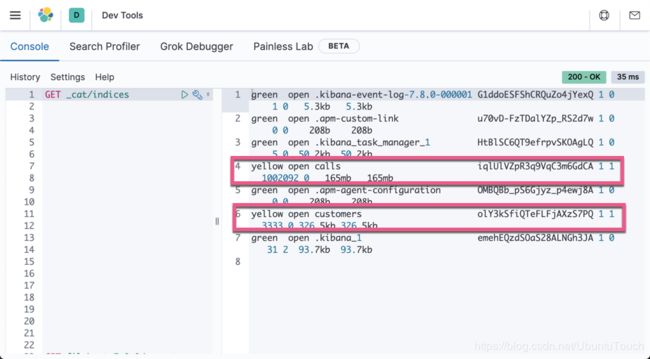
这两个索引的内容如下面的格式:
calls index
{
"column1" : 0,
"dialled_number" : "415-421-9401",
"call_charges" : 0.2647226166736342,
"call_duration" : 2.569473435514605,
"@timestamp" : "2020-09-08T10:16:15.019+08:00",
"phone_number" : "415-382-4657",
"timestamp" : "2020-09-08 10:16:15.019388"
}注意上面的 column1 字段表示为在 csv 文档中的第一列。是个系列号。calls 索引共有 1002092 个数据。
customers index
{
"column1" : 0,
"number_vmail_messages" : 25,
"account_length" : 128,
"churn" : 0,
"customer_service_calls" : 1,
"voice_mail_plan" : "yes",
"phone_number" : "415-382-4657",
"state" : "KS",
"international_plan" : "no"
}注意上面的 column1 字段表示为在 csv 文档中的第一列。是个系列号。customers 索引共有 3333 个数据。其中的一个单词 churn 表示客户是否流失过。1 表示流失过,0则表示没有。
构建功能集
首先,我们要构建功能集。 我们有两个数据源:customers 元数据和 calls 日志。 这需要使用 transforms 和 enrich processor。 这种组合使我们可以将元数据与呼叫信息合并到另一个索引中。如果大家对 enrich processor 还是不很理解的话,你可以参阅我之前的文章 “如何使用 Elasticsearch ingest 节点来丰富日志和指标”。
enrich policy 及 pipeline 定义如下。 我们在 Kibana 的 Dev Tools 中打入如下的命令:
# Enrichment policy for customer metadata
PUT /_enrich/policy/customer_metadata
{
"match": {
"indices": "customers",
"match_field": "phone_number",
"enrich_fields": ["account_length", "churn", "customer_service_calls", "international_plan","number_vmail_messages", "state", "voice_mail_plan"]
}
}
# Execute the policy so we can populate with the metadata
POST /_enrich/policy/customer_metadata/_execute
# Our enrichment pipeline for generating features
PUT _ingest/pipeline/customer_metadata
{
"description": "Adds metadata about customers by phone_number",
"processors": [
{
"enrich": {
"policy_name": "customer_metadata",
"field": "phone_number",
"target_field": "customer",
"max_matches": 1
}
}
]
}现在,我们可以构建一个利用新管道的 transform。 下面的就是这个 transform 的定义:
# transform for enriching the data for training
PUT _transform/customer_churn_transform
{
"source": {
"index": [
"calls"
]
},
"dest": {
"index": "churn",
"pipeline": "customer_metadata"
},
"pivot": {
"group_by": {
"phone_number": {
"terms": {
"field": "phone_number"
}
}
},
"aggregations": {
"call_charges": {
"sum": {
"field": "call_charges"
}
},
"call_duration": {
"sum": {
"field": "call_duration"
}
},
"call_count": {
"value_count": {
"field": "dialled_number"
}
}
}
}
}运行上面的命令,它就帮我们生成了一个 transform。当然我们也可以直接使用 Stack Management 所提供的 transforms 的界面来完成这个。详细的操作可以参阅我之前的文章 “Elasticsearch:Transforms 介绍”。
当我们运行完上面的命令后,我们进入到 Stack Management 界面,并点击 transforms:
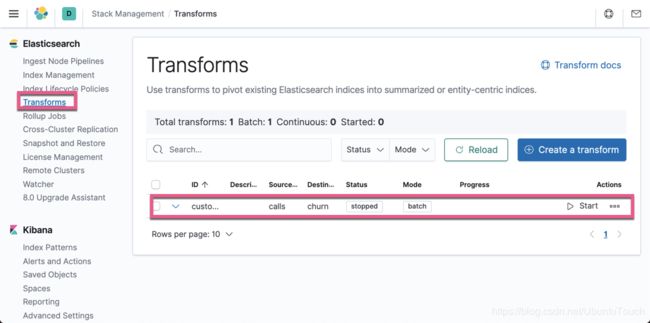
我们可以看见一个新生成的叫做 customer_churn_transform 的 transform。点击上面的 Start 按钮:
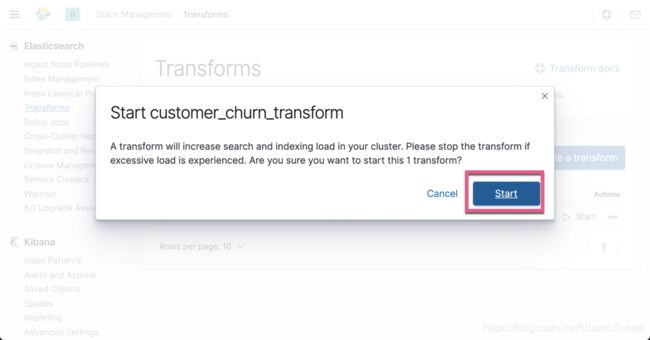
点击 Start 按钮。我们需要等待一段时间让它完成:
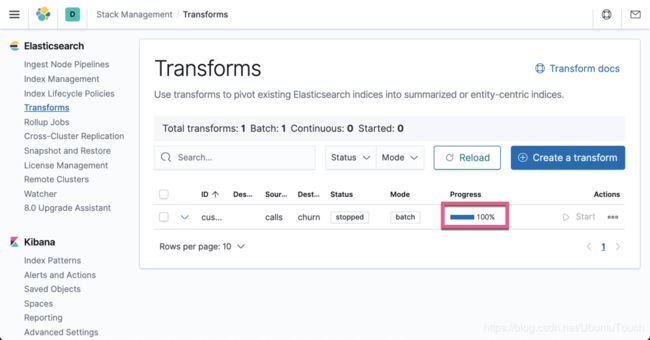
上面显示它已经 100% 的完成了。
如果大家不想使用 Transforms 界面完成,我们也可以直接使用如下的命令来完成:
POST _transform/customer_churn_transform/_start我们也可以使用如下的命令来进行停止:
POST _transform/customer_churn_transform/_stop我们再次查看,有一个新的叫做 churn 的索引已经被生产了:

这个索引含有和 customers 索引一样数目的文档 3333,并且它的文档的内容如下:
{
"call_count" : 308.0,
"phone_number" : "408-327-6764",
"call_charges" : 55.310000000000024,
"call_duration" : 589.5000000000002,
"customer" : {
"voice_mail_plan" : "no",
"number_vmail_messages" : 0,
"account_length" : 105,
"churn" : 0,
"phone_number" : "408-327-6764",
"state" : "NE",
"international_plan" : "no",
"customer_service_calls" : 4
}
}显然这里面的数据包含了一个 phone_number 所对应的指标信息:call_charges (通话费用)总和,call_duration (通话时间) 的总和 及 dialled_number (通话次数) 的总数。同时我们可以看出来,它还同时包含了这个 phone_number 所对应的 customer 的信息。这个就是通过上面的 enrich processor 在 transform 的过程中进行丰富的结果。
我们已经建立了通话费用,通话次数和通话时间的总和。 这些功能与我们的客户元数据配对后,就足以建立客户流失预测模型。
我们的功能集中共有9个功能,其中3个是分类功能。 此外,我们还有字段 customer.churn。 这代表了过去是否流失过的客户的历史数据。 这将是我们的监督学习用来建立我们的预测模型的标签。

建立模型
设置好功能集后,就可以开始构建我们的监督模型了。 我们将根据客户致电数据预测客户流失。
注意:在进行下面的操作之前,我们需要为刚才新创建的 churn 创建一个 index pattern。我们取名为 churn*。
导航至 Kibana 中机器学习应用程序中的 “Data frame Analytics” 选项。
首先,要创建工作,请执行以下操作:


请注意就像上面所显示的那样:这是一个 Experimental 的功能。在将来的版本中可能还有演进。点击上面的 Create 按钮:

上面的每一项都很容易理解。我们向下滚动屏幕:
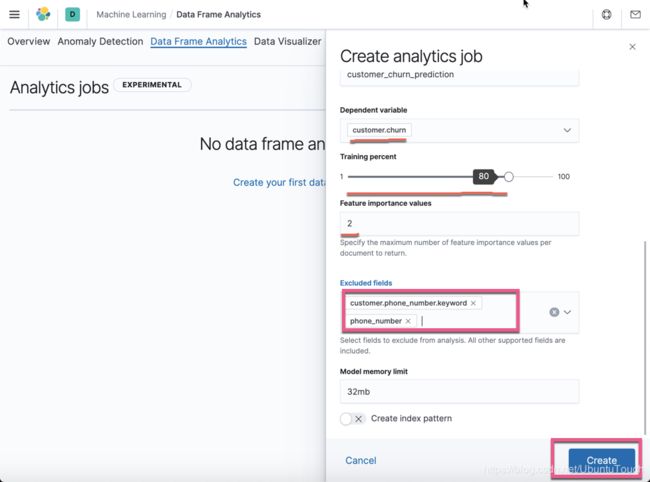
对上面的选项,做一下的说明:
- 依赖的变量是 customer.churn。这个也就是我们想要尝试预测的
- 对于数据量的选择,我们选择 80% 的数据来进行训练,这样我们还可以有 20% 的数据来进行检验我们的模型是否正确
- 我们必须除去那些认为是没有附加任何信息的字段。针对我们的情况,customer.phone_number 及 phone_number 对于每个文档来说都是唯一,并不含有任何有用的信息
- 针对目前我们的模型来说,保留 32m 内存的限制。这样可以让任务的执行者挑选出一个能够满足运行这个任何的节点来运行
此分析作业将确定以下内容:
- 每个功能的最佳编码
- 哪些功能可以提供最佳信息,或者哪些功能可以忽略
- 建立最佳模型的最佳超参数
一旦完成运行,就可以根据其测试和训练数据看到模型的错误率。
我们点击上面界面中的 Create 按钮:
点击 Start 按钮:

点击 Close 按钮:

上面显示已经完成。点击 View:
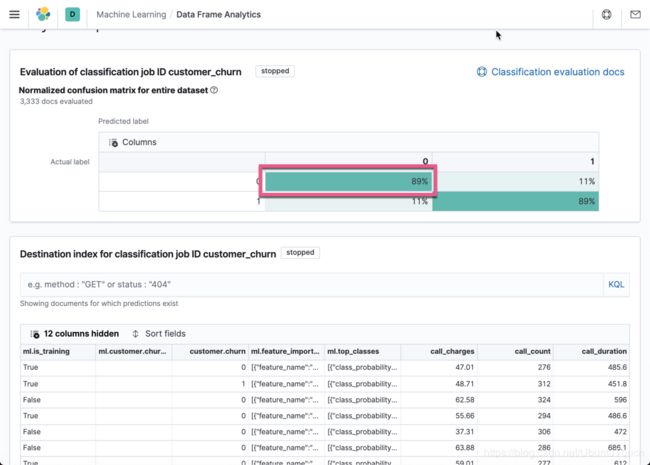
上面显示我们的模型有 89% 的准确率。有 11% 的误差率。这个结果是用我们剩下的 20% 的数据来进行测试的。
相当不错的准确性! 如果你遵循,你的数字可能会略有不同。 训练模型时,它将使用数据的随机子集来进行训练的,所以你的准确率可能会有所不同。
现在,我们有了一个可以在摄取管道中使用的模型。
上面的操作会生产一个叫做 customer_churn_prediction 的索引,我们可以在 Discover 里查询这个索引:

通过这个模型,我们可以查看到虽然有的电话号码的客户没有流失过的历史,但是在机器模型里显示他们极有可能会流失。
使用模型
由于我们知道哪个 data frame analytics 任务创建了此模型,因此可以通过以下 API 调用查看其 ID 和各种设置:
GET _ml/inference/customer_churn*?human=true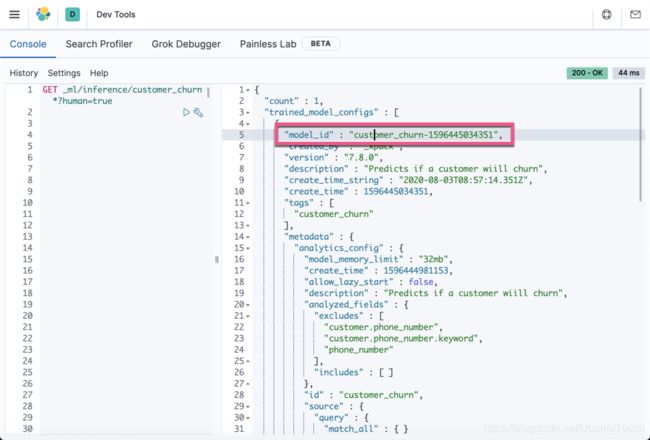
我们可以通过如下的命令来查看这个模型的定义:
GET _ml/inference/customer_churn-1596445034351?include_model_definition=true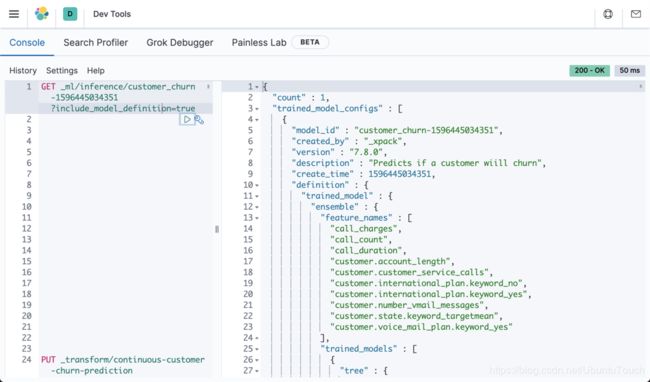
有了模型 ID,我们现在可以进行预测。 我们通过转换构建了原始功能集。 我们将对通过 inference processor 发送的所有数据执行相同的操作。
# Enrichment + prediction pipeline
# NOTE: model_id will be different for your data
PUT _ingest/pipeline/customer_churn_enrich_and_predict
{
"description": "enriches the data with the customer info if known and makes a churn prediction",
"processors": [
{
"enrich": {
"policy_name": "customer_metadata",
"field": "phone_number",
"target_field": "customer",
"max_matches": 1,
"tag": "customer_data_enrichment"
}
},
{
"inference": {
"model_id": "customer_churn-1581693287679",
"inference_config": {
"classification": {}
},
"field_map": {},
"tag": "chrun_prediction"
}
}
]
}是时候将所有内容进行连续 transform 了。这样如果有数据变化,它会自动帮我们进行 transform。
PUT _transform/continuous-customer-churn-prediction
{
"sync": {
"time": {
"field": "@timestamp",
"delay": "10m"
}
},
"source": {
"index": [
"calls"
]
},
"dest": {
"index": "churn_predictions",
"pipeline": "customer_churn_enrich_and_predict"
},
"pivot": {
"group_by": {
"phone_number": {
"terms": {
"field": "phone_number"
}
}
},
"aggregations": {
"call_charges": {
"sum": {
"field": "call_charges"
}
},
"call_duration": {
"sum": {
"field": "call_duration"
}
},
"call_count": {
"value_count": {
"field": "dialled_number"
}
}
}
}
}我们可以通过如下的方法得到一个电话号码的在 customer_churn_prediction 里的数据:
GET customer_churn_prediction/_search
{
"query": {
"match": {
"phone_number": "415-336-7155"
}
}
}上面的命令得到的数据是:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 7.706462,
"hits" : [
{
"_index" : "customer_churn_prediction",
"_type" : "_doc",
"_id" : "NA2u1J6fr9cVSJ2rF-m1GsUAAAAAAAAA",
"_score" : 7.706462,
"_source" : {
"call_count" : 227.0,
"ml__id_copy" : "NA2u1J6fr9cVSJ2rF-m1GsUAAAAAAAAA",
"phone_number" : "415-336-7155",
"call_charges" : 74.9,
"call_duration" : 722.2000000000002,
"customer" : {
"voice_mail_plan" : "yes",
"number_vmail_messages" : 23,
"account_length" : 98,
"churn" : 0,
"phone_number" : "415-336-7155",
"state" : "MS",
"international_plan" : "yes",
"customer_service_calls" : 1
},
"ml" : {
"customer.churn_prediction" : 1,
"top_classes" : [
{
"class_probability" : 0.3313395500975273,
"class_score" : 0.3313395500975273,
"class_name" : 1
},
{
"class_probability" : 0.6686604499024726,
"class_score" : 0.058657841202257775,
"class_name" : 0
}
],
"prediction_score" : 0.3313395500975273,
"prediction_probability" : 0.3313395500975273,
"feature_importance" : [
{
"feature_name" : "call_charges",
"importance" : 1.8459937532908455
},
{
"feature_name" : "customer.international_plan.keyword",
"importance" : 2.152380454272977
}
],
"is_training" : true
}
}
}
]
}
}我们可以把上面的数据(call_count, call_charges, call_duration 及 phone_number)拷出来放到如下的 pipeline 里来做测试:
POST _ingest/pipeline/customer_churn_enrich_and_predict/_simulate
{
"docs": [
{
"_source": {
"call_count": 227,
"call_charges": 74.9,
"call_duration": 722.2000000000002,
"phone_number": "415-336-7155"
}
}
]
}上面的命令显示的结果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"call_count" : 227,
"phone_number" : "415-336-7155",
"call_charges" : 74.9,
"call_duration" : 722.2000000000002,
"customer" : {
"voice_mail_plan" : "yes",
"number_vmail_messages" : 23,
"account_length" : 98,
"churn" : 0,
"phone_number" : "415-336-7155",
"state" : "MS",
"international_plan" : "yes",
"customer_service_calls" : 1
},
"ml" : {
"inference" : {
"chrun_prediction" : {
"model_id" : "customer_churn-1596445034351",
"top_classes" : [
{
"class_name" : 1,
"class_probability" : 0.3313395454234844,
"class_score" : 0.3313395454234844
},
{
"class_name" : 0,
"class_probability" : 0.6686604545765156,
"class_score" : 0.05865784161228542
}
],
"feature_importance" : [
{
"feature_name" : "customer.international_plan.keyword",
"importance" : 2.1523804542729774
},
{
"feature_name" : "call_charges",
"importance" : 1.8459937532908453
}
],
"predicted_value" : 1
}
}
}
},
"_ingest" : {
"timestamp" : "2020-08-04T14:11:39.156736Z"
}
}
}
]
}在上面显示有一个很重要的部分:
"feature_importance" : [
{
"feature_name" : "customer.international_plan.keyword",
"importance" : 2.1523804542729774
},
{
"feature_name" : "call_charges",
"importance" : 1.8459937532908453
}
],如上所示,影响最终 predicted_value 值有两个重要的指标就是 call_charges 及 customer.international_plan。也就是说说这个人觉得话费太高,而且还有国际长途的套餐。我们可以尝试去修改 customers 的索引,把这个客户的 international_plan 变为 “no"。
GET customer_churn_prediction/_search
{
"query": {
"match": {
"phone_number": "415-336-7155"
}
}
}返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 7.197136,
"hits" : [
{
"_index" : "customers",
"_type" : "_doc",
"_id" : "Xa9Fs3MBk67cRVUGHQYW",
"_score" : 7.197136,
"_source" : {
"column1" : 2289,
"number_vmail_messages" : 23,
"account_length" : 98,
"churn" : 0,
"customer_service_calls" : 1,
"voice_mail_plan" : "yes",
"phone_number" : "415-336-7155",
"state" : "MS",
"international_plan" : "no"
}
}
]
}
}通过如下的命令:
POST customers/_update/Xa9Fs3MBk67cRVUGHQYW
{
"doc": {
"international_plan" : "no"
}
}修该完它的 international_plan 为 ”no"。接着执行如下的命令:
# Execute the policy so we can populate with the metadata
POST /_enrich/policy/customer_metadata/_execute这样重新丰富所有的数据。经过10分钟过后(参考上面的 _transform/continuous-customer-churn-prediction 部分),我们再次重新来运行如下的命令:
POST _ingest/pipeline/customer_churn_enrich_and_predict/_simulate
{
"docs": [
{
"_source": {
"call_count": 227,
"call_charges": 74.9,
"call_duration": 722.2000000000002,
"phone_number": "415-336-7155"
}
}
]
}这个和之前的是一样的。我们查看一下返回的结果:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"call_count" : 227,
"phone_number" : "415-336-7155",
"call_charges" : 74.9,
"call_duration" : 722.2000000000002,
"customer" : {
"voice_mail_plan" : "yes",
"number_vmail_messages" : 23,
"account_length" : 98,
"churn" : 0,
"phone_number" : "415-336-7155",
"state" : "MS",
"international_plan" : "no",
"customer_service_calls" : 1
},
"ml" : {
"inference" : {
"chrun_prediction" : {
"model_id" : "customer_churn-1596445034351",
"top_classes" : [
{
"class_name" : 0,
"class_probability" : 0.9585850766911188,
"class_score" : 0.08409130705368165
},
{
"class_name" : 1,
"class_probability" : 0.04141492330888117,
"class_score" : 0.04141492330888117
}
],
"feature_importance" : [
{
"feature_name" : "call_charges",
"importance" : 2.455775179713569
},
{
"feature_name" : "customer.number_vmail_messages",
"importance" : -1.5230966918180966
}
],
"predicted_value" : 0
}
}
}
},
"_ingest" : {
"timestamp" : "2020-08-04T14:33:43.976624Z"
}
}
}
]
}这次显示的 predicted_value 为0。这个充分说明了这个人的国际套餐是这个人即将流失的原因。
当变换看到新数据时,它将创建我们的功能集并根据模型进行推断。 该预测与丰富的数据一起被索引为 churn_predictions。 这一切都是连续发生的。 随着新的客户呼叫数据的到来,转换将更新我们的客户流失预测。 预测是索引中的数据。 这意味着我们可以通过警报进行操作,使用 Lens 构建可视化文件或构建自定义仪表板。
总结
现在可以运用 Elastic 进行用于特征创建,模型训练和模型推断的数据管道。 这意味着可以使用 Elastic APM,SIEM 或 Logs 中的数据来构建监督的机器学习模型。 这为安全,可观察性,物流或好奇心中的许多用例打开了大门。 立即免费试用 Elastic Cloud,以试用新的机器学习功能。 机器学习将为您回答哪些问题?