04-Kafka Broker启动脚本及对应源码解析
我们已经在IDEA集成工具中导入了Kafka源代码,现在我们先从应用角度去分析一下Kafka启动的过程。
最近因为工作原因要对Kafka源码进行二次开发,所以就开始着手源码的学习。
1.首先我们先看一下kafka-server-start.sh脚本
kafka在启动的过程中我们会用到%KAFKA_HOME%下的bin目录下的kafka-server-start.sh../config/server.properties命令所以先看这个shell脚本。脚本内容如下。
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] server.properties [--overrideproperty=value]*"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" ="x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" ="x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
EXTRA_ARGS="-name kafkaServer-loggc"
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
exec $base_dir/kafka-run-class.sh$EXTRA_ARGS kafka.Kafka "$@"
解释一下上面的大致内容,首先判断传入的参数个数如果小于1的情况会打印一些提示信息,中间会对一些日志和Kafka堆栈内存进行设置,默认是设置1G大小。如果在kafka-server-start.sh 后面加上参数-daemon参数,则在执行过程中会以后台进程进行运行。
最终exec调用了kafka-run-class.sh 后面传入java的类kafka.Kafka
2.再看一下kafka-run-class.sh脚本的内容。
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] [-name servicename] [-loggc] classname[opts]"
exit 1
fi
base_dir=$(dirname $0)/..
if [ -z "$SCALA_VERSION" ]; then
SCALA_VERSION=2.10.5
fi
if [ -z "$SCALA_BINARY_VERSION"]; then
SCALA_BINARY_VERSION=2.10
fi
# run ./gradlew copyDependantLibs to getall dependant jars in a local dir
shopt -s nullglob
for dir in $base_dir/core/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH=$CLASSPATH:$dir/*
done
for file in$base_dir/examples/build/libs//kafka-examples*.jar;
do
CLASSPATH=$CLASSPATH:$file
done
for file in$base_dir/clients/build/libs/kafka-clients*.jar;
do
CLASSPATH=$CLASSPATH:$file
done
for file in$base_dir/tools/build/libs/kafka-tools*.jar;
do
CLASSPATH=$CLASSPATH:$file
done
for dir in$base_dir/tools/build/dependant-libs-${SCALA_VERSION}*;
do
CLASSPATH=$CLASSPATH:$dir/*
done
for cc_pkg in "api""runtime" "file" "json"
do
forfile in $base_dir/connect/${cc_pkg}/build/libs/connect-${cc_pkg}*.jar;
do
CLASSPATH=$CLASSPATH:$file
done
if[ -d "$base_dir/connect/${cc_pkg}/build/dependant-libs" ] ; then
CLASSPATH=$CLASSPATH:$base_dir/connect/${cc_pkg}/build/dependant-libs/*
fi
done
# classpath addition for release
CLASSPATH=$CLASSPATH:$base_dir/libs/*
for file in$base_dir/core/build/libs/kafka_${SCALA_BINARY_VERSION}*.jar;
do
CLASSPATH=$CLASSPATH:$file
done
shopt -u nullglob
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
fi
# JMX port to use
if [ $JMX_PORT ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS-Dcom.sun.management.jmxremote.port=$JMX_PORT "
fi
# Log directory to use
if [ "x$LOG_DIR" = "x"]; then
LOG_DIR="$base_dir/logs"
fi
# Log4j settings
if [ -z "$KAFKA_LOG4J_OPTS" ];then
#Log to console. This is a tool.
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/config/tools-log4j.properties"
else
#create logs directory
if[ ! -d "$LOG_DIR" ]; then
mkdir -p "$LOG_DIR"
fi
fi
KAFKA_LOG4J_OPTS="-Dkafka.logs.dir=$LOG_DIR$KAFKA_LOG4J_OPTS"
# Generic jvm settings you want to add
if [ -z "$KAFKA_OPTS" ]; then
KAFKA_OPTS=""
fi
# Which java to use
if [ -z "$JAVA_HOME" ]; then
JAVA="java"
else
JAVA="$JAVA_HOME/bin/java"
fi
# Memory options
if [ -z "$KAFKA_HEAP_OPTS" ];then
KAFKA_HEAP_OPTS="-Xmx256M"
fi
# JVM performance options
if [ -z"$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC-XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35-XX:+DisableExplicitGC -Djava.awt.headless
=true"
fi
while [ $# -gt 0 ]; do
COMMAND=$1
case $COMMAND in
-name)
DAEMON_NAME=$2
CONSOLE_OUTPUT_FILE=$LOG_DIR/$DAEMON_NAME.out
shift 2
;;
-loggc)
if [ -z "$KAFKA_GC_LOG_OPTS" ]; then
GC_LOG_ENABLED="true"
fi
shift
;;
-daemon)
DAEMON_MODE="true"
shift
;;
*)
break
;;
esac
done
# GC options
GC_FILE_SUFFIX='-gc.log'
GC_LOG_FILE_NAME=''
if [ "x$GC_LOG_ENABLED" ="xtrue" ]; then
GC_LOG_FILE_NAME=$DAEMON_NAME$GC_FILE_SUFFIX
KAFKA_GC_LOG_OPTS="-Xloggc:$LOG_DIR/$GC_LOG_FILE_NAME -verbose:gc-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps "
fi
# Launch mode
if [ "x$DAEMON_MODE" ="xtrue" ]; then
nohup $JAVA $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS$KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS"$@" > "$CONSOLE
_OUTPUT_FILE" 2>&1
else
exec $JAVA $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS$KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS"$@"
fi
最终是一堆参数的设置,最终还是根据是否有-daemon参数来判断是否后台进程启动。--override property=value是若干个可项的参数, 用来覆盖server.properties配置文件中同名的配置项。不管是否后台启动进程,最终是运行了Kafka。
3.打开源码我们来分析一下shell脚本中执行的类kafka.Kafka.scala文件。
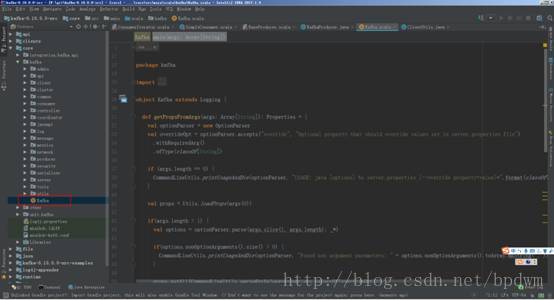
重要的是这个main函数,这个是启动kafka的入口,具体的讲解在下一次博客中分享。
def main(args: Array[String]): Unit = { try { val serverProps = getPropsFromArgs(args) val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps) // attach shutdown handler to catch control-c Runtime.getRuntime().addShutdownHook(new Thread() { override def run() = { kafkaServerStartable.shutdown
//注册shutdown时候的钩子函数 } }) // 执行脚本/bin/kafka-server-start.sh server.properties的入口 kafkaServerStartable.startup // 挂起,处于一直执行状态,除非出现故障 kafkaServerStartable.awaitShutdown } catch { case e: Throwable => fatal(e) System.exit(1) } System.exit(0) } }