sklearn 之 单类支持向量机(One-Class SVM)
这里先列出 sklearn 官方给出的使用高斯核(RBF kernel) one class svm 实现二维数据的异常检测:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# Generate train data
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
# plot the line, the points, and the nearest vectors to the plane
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("Novelty Detection")
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu) #绘制异常样本的区域
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred') #绘制正常样本和异常样本的边界
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred') #绘制正常样本的区域
s = 40
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=s, edgecolors='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='blueviolet', s=s,
edgecolors='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='gold', s=s,
edgecolors='k')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([a.collections[0], b1, b2, c],
["learned frontier", "training observations",
"new regular observations", "new abnormal observations"],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
plt.xlabel(
"error train: %d/200 ; errors novel regular: %d/40 ; "
"errors novel abnormal: %d/40"
% (n_error_train, n_error_test, n_error_outliers))
plt.show()
效果如下图:
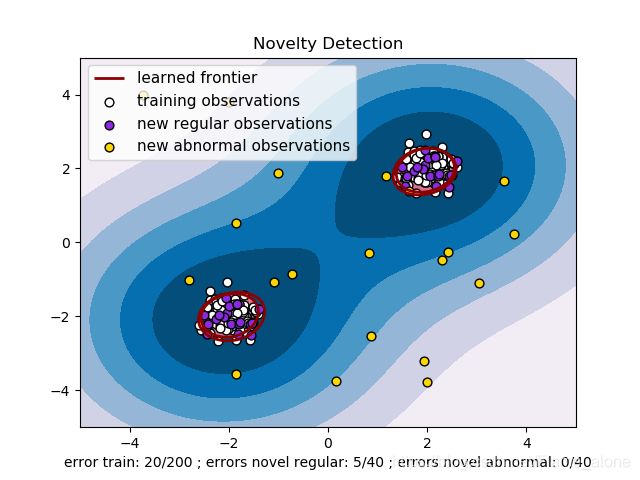
下面简单介绍一下 sklearn.svm.OneClassSVM 函数的用法:
decision_function(self, X)点到分割超平面的有符号距离fit(self, X[, y, sample_weight])训练出样本 X 的软边界fit_predict(self, X[, y])训练出样本 X 的软边界后返回标签(是否异常)get_params(self[, deep])获取估计器训练参数predict(self, X)返回样本 X 的标签
对于可视化图像绘制的函数
matplotlib.pyplot.contour和matplotlib.pyplot.contourf可以绘制出等高线和填充等高线,两个函数的参数和调用方式一样。其中levels代表了分割线的 list,以plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu)这句话为例:表示的是绘制以xx和yy构成的二维平面,以Z作为每个点的高程绘制等高线,从Z.min()到 0 分成 7 份,当 Z 等于这 7 个值时绘制等高线。plt.cm.PuBu代表一种颜色映射,具体的样式见 Colormap reference。matplotlib.pyplot.scatter绘制散点图
下面是改编的代码用于异常检测:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import pickle
import numpy as np
import pandas as pd
from math import ceil
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
def get_dataset_to_pandas(file_name, dropList=[]):
dataset = pd.read_csv(file_name)
for drop_str in dropList:
dataset = dataset.drop(drop_str,axis=1)
return dataset
def pre_scaler(dataset, type_str = "std"):
if type_str == "minmax":
scaler = MinMaxScaler()
elif type_str == "std":
scaler = StandardScaler()
else :
return None
scaler.fit(dataset)
return scaler,scaler.transform(dataset)
def train_test_split(dataset, test_ratio = 0.3, seed = 42):
if seed:
np.random.seed(seed)
shuffle_index = np.random.permutation(len(dataset))
test_size = ceil(len(dataset) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
dataset_train = dataset[train_index]
dataset_test = dataset[test_index]
return dataset_train, dataset_test
def variable_save(variable, file_name):
data_output = open(file_name, 'wb')
pickle.dump(variable,data_output)
data_output.close()
def variable_load(file_name):
data_input = open(file_name, 'rb')
variable = pickle.load(data_input)
data_input.close()
return variable
if __name__ == '__main__':
dataset = get_dataset_to_pandas("walk1.csv", ["Loss","TimeStamp","LT_Foot_TimeStamp","RT_Foot_TimeStamp",'Chest_TimeStamp'])
scaler, dataset = pre_scaler(dataset,"minmax")
X_train, X_test = train_test_split(dataset)
# fit the model
clf = svm.OneClassSVM(nu=0.05, kernel="rbf", gamma="auto")
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
print(n_error_train,",",n_error_test)
# distances = clf.decision_function(dataset)
# save clf and scaler
# variable_save((clf,scaler),'./one_class_svm')
# (clf,scaler) = variable_load('./one_class_svm')
# print(clf,'\n',scaler)
在训练完成之后可以通过 clf.decision_function 检测与边界的距离来判断是否异常和 clf.predict 直接判断是否是异常点。