[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch
论文(2014年): 链接
Pytorch代码: 链接
《Network In Network》是一篇比较老的文章了(2014年ICLR的一篇paper),是当时比较牛逼的一篇论文,同时在现在看来也是一篇非常经典并且影响深远的论文,后续很多创新都有这篇文章的影子。通常里程碑式的经典是不随时间而黯淡的,同样值得好好学习。
NIN的结构有两个创新点,都是比较有里程碑意义的,分别是MLPconv以及全局平均池化
MLP Convolution Layers
在讲之前,我想梳理一下“历史”,我们知道在神经网络还没有出现之前,有个叫感知机(PLA)的东西,它是神经网络的雏形,它所用的激活函数叫阶跃函数,而当激活函数使用非线性函数时,便进入到了神经网络的世界,神经网络的一个重要性质就是它可以自动地从数据中学习到合适的权重参数,不同于感知机时的人工设置参数.而神经网络的别名就是多层感知机(Multi Layer Perceptron,MLP), 即使用sigmoid等非线性激活函数的多层网络.非线性激活函数的重要性很大,如果使用线性激活函数,加深神经网络的层数就没有意义了,如下图1列举了一个经典的例子
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第1张图片](http://img.e-com-net.com/image/info8/ff57bab3323f4def9acfc075de61efe7.jpg) 图1 神经网络为什么要使用非线性激活函数?(来自[3])
图1 神经网络为什么要使用非线性激活函数?(来自[3])
所以神经网络必须使用非线性激活函数, 神经网络出现不久,就引进了一个叫全连接(fully-connected),就是相邻的所有神经元之间都有连接,但是全连接的神经网络当输入数据的尺寸比较大的时候,会带来了一个很严重的问题,就是参数特别多特别多多多,于是才诞生了卷积神经网络CNN,关于CNN的这段曲折的历史,想了解更多的话,可以阅读这篇文章(链接)
CNN中的卷积层中是通过线性滤波器对输入特征图进行卷积运算,然后紧跟其后的是非线性激活函数,这里的非线性激活函数为什么要用非线性前面已经提到了原因,就是为了让隐层变得有意义,而线性滤波器何谓线性?普通的卷积操作可以用一下公式来表示:
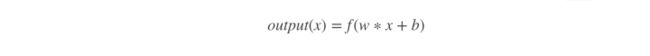
其中,w∗x+b为线性变换,函数f为非线性激励函数,例sigmoid,tanh,ReLUsigmoid,tanh,ReLU等.从公式中可以看到,普通的卷积过程是一个线性变化,可以简单地理解线性就是“直线”, 这是一种线性滤波器,它是一个广义线性模型(generalized linear model, GLM), 当样本的隐含概念(latent concept,即从图像中抽取出来的特征)线性可分时,广义线性模型足以抽象线性可分的隐含概念。然而, 传统的CNN是建立在认为隐含概念是线性可分的假设上,但是这个假设比较理想主义,实际情况中大多隐含概念都是线性不可分的. 但是事情还没结束,GLM感觉自己还能再抢救一下,就发现了可以通过疯狂增加滤波器(卷积核)的数量来cover各个方面的隐含概念[4],然后在下一层卷积的时候把这些隐含概念结合起来,然后再继续抽象更多的隐含概念,那么问题也随之而来 ,GLM为了能尽量全面的cover到所有隐含概念就只能疯狂增加每一层神经元的数量,这就导致产生了很多冗余的参数,同时,使用太多滤波器也给下一层带来了很大的负担,需要考虑来自前一层的所有变化的组合[5].
在maxout网络[6]中, 线性函数的最大化使得分段线性逼近器能够逼近任何凸函数。与传统CNN的卷积层进行线性分离相比,maxout网络更有效 。但是它也有前提:隐含概念位于输入空间的凸集内.
综上所述,通俗一点来讲, 就是现有的卷积还不能很好地对特征进行抽象,它们都在一个比较理想的前提假设下,而实际中往往比较复杂, 因此我们需要一个更通用的函数逼近器, 也就是说这个卷积该如何去卷才能在隐含概念处于更复杂的分布时也依然能够逼近潜在概念的更抽象的表示。我们知道在较高的层的卷积核会映射到原始输入的较大区域(通过感受野的增大得知),它通过结合较低层的语义特征来生成更高层次的语义特征,所以作者认为在结合之前能够把这些局部特征更好的抽象出来,那么对后面的网络的进一步处理有着有更大的意义
径向基(Radial basis network)和多层感知机(multilayer perceptron,MLP)是两个著名的通用函数逼近器。在这项工作中,作者选择了多层感知器,也就是说作者利用多层感知器去进行卷积,这样能够更好地把特征抽象出来,选择多层感知器有两个原因:
-
多层感知器其实就是神经网络, 它与卷积神经网络的结构一样,都是通过反向传播训练。它们可以相互兼容。
-
其次多层感知器符合特征再利用的原则,我的理解是特征里面还有可以用的特征。
基于这个MLP,作者将原来的GLM改造成了MLPconv,下面分别对它们进行讲解
普通卷积层(卷积核大小大于1)即文中提到的GLM, 相当于单层网络,抽象能力有限,其计算公式(省略了偏置b)和示意图如下:
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第2张图片](http://img.e-com-net.com/image/info8/0062c85214b94b77a61099368b3ccfef.jpg)
![]()
为了提高特征的抽象表达能力,作者提出了使用多层感知机(MLP)来替代传统卷积层。
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第3张图片](http://img.e-com-net.com/image/info8/090f3db9a23947d7b0c74605ec35c57b.jpg)
如上图所示,MLPConv其实就是在常规卷积(卷积核大小大于1)后接若干层若干个1x1卷积(后面我再讲为什么是1x1卷积),这些1x1卷积如果看成神经元的话,这样就像是MLP(多层感知机)了,也就是说这里有一个微型的神经网络,而且还是全连接,用这个微型的神经网络也就是MLP来对特征进行提取, 这也是文章的最大创新点,所以为什么要叫Network in Network,公式如下图所示, n为网络层数,第一层为普通卷积层(卷积核尺寸大于1),后面层用的是1x1卷积。(这里每层mlp采用Relu来进行激活)
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第4张图片](http://img.e-com-net.com/image/info8/3d0b21abb39743f69f1787ea01ebb69f.jpg)
![]()
综上所述,像Mlpconv这样的卷积操作,也就是这种利用了MLP这个更通用的函数逼近器,使得网络能够逼近潜在概念的更抽象的表示.
我们下面举个例子去感受一下MLPconv的卷积过程,并顺便讲解下为什么要用到1x1卷积
假设输入数据尺寸为27X27,通道数为3,然后经过一个常规卷积,即4个3X3的卷积核,输出特征图尺寸为9X9,通道数为4,然后经过4个1X1的卷积,输出特征图尺寸为9X9,通道数为4,最后再经过4个1X1的卷积,输出特征图结果依旧是尺寸为9X9,通道数为4(每一层MLP由ReLU激活)
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第5张图片](http://img.e-com-net.com/image/info8/51b844efc733498bb869cc92664cac54.jpg)
这里的1X1卷积除了为了保持特征图的尺寸而使用外,个人觉得它也把各通道的输入特征图进行线性加权,起到综合各个通道特征图信息的作用,多几层这样的1X1卷积的话,那最终提取的特征会更加抽象。其实可以做个假设,如果不用1X1卷积而是用更大的卷积核,那和连续用GLM有什么区别?就是因为用了1X1卷积,才增强了常规卷积的抽象表达能力。
其实MLPconv就是在常规卷积后面加了N层1X1卷积,所以很容易理解,并且从代码的层次来讲,这种结构也比较的容易实现
在当时作者应该是第一个使用1x1卷积的,具有划时代的意义,之后的Googlenet借鉴了1*1卷积,还专门致谢过这篇论文,现在很多优秀的网络结构都离不开1x1卷积,ResNet、ResNext、SqueezeNet、MobileNetv1-3、ShuffleNetv1-2等等. 1x1卷积作为NIN函数逼近器基本单元,除了增强了网络局部模块的抽象表达能力外,在现在看来, 还可以实现跨通道特征融合和通道升维降维。
全局平均池化 GAP
INI不采用传统的全连接层进行分类,而是直接输出来自最后一层mlpconv的feature maps,然后通过全局平均池化层,然后将得到的向量送入softmax层。在传统的CNN中,由于完全连接的层之间充当了一个黑盒子,很难解释来自目标成本层的类别级信息是如何传递回之前的卷积层的。相比之下,全局平均池更有意义和可解释性,因为它加强了feature map和类别之间的对应。此外, 全连通层容易发生过拟合,严重依赖dropout正则化,而全局平均池本身就是一个结构正则化器,从本质上防止了整体结构的过拟合
![[论文解读]深度学习基础模型NIN(Network in Network)+Pytorch_第6张图片](http://img.e-com-net.com/image/info8/90e27e5207c54f3faf6293e2faffca23.jpg) Network In Network(NIN): three mlpconv layers and one global average pooling layer
Network In Network(NIN): three mlpconv layers and one global average pooling layer
reference
1、NIN(Network in Network)学习笔记
2、深度学习网络篇——NIN(Network in Network)
3、《深度学习入门基于Python的理论与实现》
4、Quoc V Le, Alexandre Karpenko, Jiquan Ngiam, and Andrew Ng. Ica with reconstruction cost for efficient overcomplete feature learning. In Advances in Neural Information Processing Systems, pages 1017–1025, 2011.
5、Ian J Goodfellow. Piecewise linear multilayer perceptrons and dropout. arXiv preprint arXiv:1301.5088, 2013.
6、Ian J Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, and Yoshua Bengio.Maxout networks. arXiv preprint arXiv:1302.4389, 2013.