阿里、字节:一套高效的iOS面试题及答案、iOS知识点回顾、盲点总结
疫情期间比较火的《阿里、字节:一套高效的iOS面试题
》,以下是自己在2020年3月份做了一遍的结果,和盲点总结,欢迎大家交流.
以下题目有些比较简单的就没有作答.部分题目需要篇幅较长的,在《另外一篇博客》中有纯手写作答.
结构模型
介绍下runtime的内存模型(isa、对象、类、metaclass、结构体的存储信息等)
1,isa为Object中的唯一成员变量,指向对象所属的类
2,isa的类型为isa_t 是后来的runtime出现的,
metaclass是元类,可以理解为根类(object类)的类
3,class中存储的主要内容包含:
isa_t superclass
cache_t cache
class_rw_t *data()
为什么要设计metaclass
因为类也是对象,动态创建的时候object类(根类)的类就是meatclass
class_copyIvarList & class_copyPropertyList区别
class_copyIvarList 就是class_ro_t中的ivars, 成员列表,在编译期确定,不能动态添加,
class_copyPropertyList 是属性列表,对应 class_rw_t的property_array_t,它的内容是property_t结构体,内容为name和attribute,对应属性,是成员变量的声明,在编译期前已经存在的属性会在编译期生成以_为开头的同名成员变量,attribute中是对成员变量的一些访问权限控制描述
class_rw_t 和 class_ro_t 的区别
class_rw_t 是runtime 时动态添加方法的操作对象,其中没有ivar相关的内容,在运行时,objc_class中是持有的class_rw_t,class_rw_t又引用的了class_ro_t,其中的方法列表,协议列表,属性列表等都是复制class_ro_t的内容,并且在运行时可以更改,它也是oc作为动态语言的一大特点
class_ro_t 是编译期,编译器对类文件编译产生的,其中包含了类的方法,属性,协议等信息,它是不能被改变的,因为已经确定了大小
category如何被加载的,两个category的load方法的加载顺序,两个category的同名方法的加载顺序
- 0 在runtime加载过程中,加载完所有的类到hash表中后,会去遍历所有的类及其对应的类别列表,一次把它合并到类的
class_rw_t中的信息中,如方法合并到method_list中等,这也是我们一直说类别方法是不是覆盖类中重名方法,而是在方法调用的时候会在method_list的中从后往前找,自然是category的先被找到, - 1,+load方法的优先级: 父类> 子类> 分类
- 2,dyld加载类别的顺序有关,在xcode中的targets-build phases-compile sources中,由上至下依次加载
- 3,两个category的同名方法谁后被加载谁先被调用
- 普通方法的优先级: 分类> 子类 > 父类, 优先级高的同名方法覆盖优先级低的
- +load方法不会被覆盖
- 同一主类的不同分类中的普通同名方法调用, 取决于编译的顺序, 后编译的文件中的同名方法会覆盖前面所有的,包括主类. +load方法的顺序也取决于编译顺序, 但是不会覆盖
- 分类中的方法名和主类方法名一样会报警告, 不会报错
- 声明和实现可以写在不同的分类中, 依然能找到实现
- 当第一次用到类的时候, 如果重写了+ initialize方法,会去调用
- 当调用子类的+ initialize方法时候, 先调用父类的,如果父类有分类, 那么分类的+ initialize会覆盖掉父类的, 和普通方法差不多
- 父类的+ initialize不一定会调用, 因为有可能父类的分类重写了它
category & extension区别,能给NSObject添加Extension吗,结果如何
category:分类
给类添加新的方法
不能给类添加成员变量
通过@property定义的变量,只能生成对应的getter和setter的方法声明,但是不能实现getter和setter方法,同时也不能生成带下划线的成员属性
是运行期决定的
注意:为什么不能添加属性,原因就是category是运行期决定的,在运行期类的内存布局已经确定,如果添加实例变量会破坏类的内存布局,会产生意想不到的错误。
extension:扩展
可以给类添加成员变量,但是是私有的
可以給类添加方法,但是是私有的
添加的属性和方法是类的一部分,在编译期就决定的。在编译器和头文件的@interface和实现文件里的@implement一起形成了一个完整的类。
伴随着类的产生而产生,也随着类的消失而消失
必须有类的源码才可以给类添加extension,所以对于系统一些类,如nsstring,就无法添加类扩展
不能给NSObject添加Extension,因为在extension中添加的方法或属性必须在源类的文件的.m文件中实现才可以,即:你必须有一个类的源码才能添加一个类的extension。
消息转发机制,消息转发机制和其他语言的消息机制优劣对比
在方法调用的时候,方法查询-> 动态解析-> 消息转发 之前做了什么
消息调用流程
- 1,消息发送,转化成objc_sendMsg(receiver,SEL)
- 2,类的cache中查找,类的methodList中查找,父类cache中查找,父类的methodList中查找到object还找不到,进入消息转发阶段
- 3,resolveClassMethod resolveInstanceMethod中判断当前接受者是否可以动态添加SEL,如果不能
- 4,forwrdingTargetForSelector 交给其他接受者处理
- 5,methodSignatureForSelector 返回方法签名 再到forwardInvocation处理异常
load、initialize方法的区别什么?在继承关系中他们有什么区别
-
load:
-
当类被装载的时候被调用,只调用一次
调用方式并不是采用runtime的objc_msgSend方式调用的,而是直接采用函数的内存地址直接调用的 -
多个类的load调用顺序,是依赖于compile sources中的文件顺序决定的,根据文件从上到下的顺序调用
-
子类和父类同时实现load的方法时,父类的方法先被调用
-
本类与category的调用顺序是,优先调用本类的(注意:category是在最后被装载的)
-
多个category,每个load都会被调用(这也是load的调用方式不是采用objc_msgSend的方式调用的),同样按照compile sources中的顺序调用的
-
load是被动调用的,在类装载时调用的,不需要手动触发调用
-
initialize:
-
当类或子类第一次收到消息时被调用(即:静态方法或实例方法第一次被调用,也就是这个类第一次被用到的时候),只调用一次
-
调用方式是通过runtime的objc_msgSend的方式调用的,此时所有的类都已经装载完毕
-
子类和父类同时实现initialize,父类的先被调用,然后调用子类的
-
本类与category同时实现initialize,category会覆盖本类的方法,只调用category的initialize一次(这也说明initialize的调用方式采用objc_msgSend的方式调用的)
-
initialize是主动调用的,只有当类第一次被用到的时候才会触发
说说消息转发机制的优劣
优势: 让语言具有动态性,更加灵活,具有更多让程序员在运行时做动作的可能性.
劣势: 高度的动态话导致安全性降低,多层机制势必降低语言执行效率
内存管理
@property定义的变量,默认的修饰符是什么?
关于ARC下,不显示指定属性关键字时,默认关键字:
1.基本数据类型:atomic readwrite assign
2.普通OC对象: atomic readwrite strong
weak的实现原理?SideTable的结构是什么样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fFxRpwzu-1593760800175)(https://github.com/imwangxuesen/Blog/blob/master/Private/temp/sidetable.png?raw=true)]
SideTables, SideTable, weak_table, weak_entry_t
关联对象的应用?系统如何实现关联对象的
全局associatedMap , 每一个对象的disguised_ptr_t结构体为key,对应着一个ObjectAssociationMap, ObjectAssociationMap中存储着本对象所有的key及其对应的关联对象(ObjectAssociation)
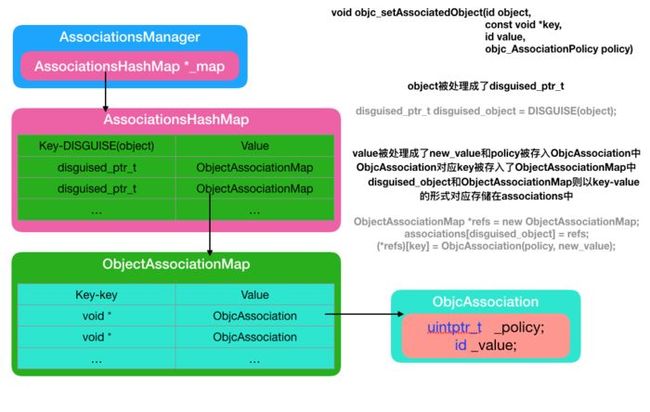
关联对象实现原理
关联对象的如何进行内存管理的?关联对象如何实现weak属性
1, 关联对象的ObjectAssociation中有两个属性(uintptr_t _policy, id value),
_policy 包含 retain, assgin copy, 会对应的对对象进行和普通对象一样的内存管理操作.
2 ,实现weak,用__weak修饰对象,并将其用block包裹,关联时,关联block对象
-(void)setWeakvalue:(NSObject *)weakvalue {
__weak typeof(weakvalue) weakObj = weakvalue;
typeof(weakvalue) (^block)() = ^(){
return weakObj;
};
objc_setAssociatedObject(self, weakValueKey, block, OBJC_ASSOCIATION_COPY_NONATOMIC);
}
-(NSObject *)weakvalue {
id (^block)() = objc_getAssociatedObject(self, weakValueKey);
return block();
}
Autoreleasepool的原理?所使用的的数据结构是什么
双向链表,编译后,autoreleasepool是一个全局变量,每一个线程,在runtime启动时都会准备一个autorelasepool,
主要两个方法, push, pop
push就是在page中插入一个哨兵对象,代表这些属于要一起release的对象,
如果page满了,则创建新的page,并合老的page关联起来,对象指针压栈
pop就是从传入哨兵对象往后,所有对象,依次执行release
Objective-C Autorelease Pool 的实现原理
自动释放池的前世今生
ARC的实现原理?ARC下对retain & release做了哪些优化
理解ARC实现原理
ARC下哪些情况会造成内存泄漏
block中的循环引用
NSTimer的循环引用
addObserver的循环引用
delegate的强引用
大次数循环内存爆涨
非OC对象的内存处理(需手动释放)
其他
Method Swizzle注意事项
1,只交换一次
2,获取方法(class_getInstanceMethod/class_getClassMethod)会沿着继承者链向上寻找,所以防止交换时,交换的方法实现时本类的,绝对不能是父类的
Method swizzling的正确姿势
属性修饰符atomic的内部实现是怎么样的?能保证线程安全吗
不能,它只管setter和getter方法的原子性,如果两个线程循环做属性的累加操作,依旧不行
iOS 中内省的几个方法有哪些?内部实现原理是什么
实现内省的方法包括:
isKindOfClass:Class
isMemberOfClass:Class
respondToSelector:selector
conformsToProtocol:protocol
实现原理:以上方法的实现原理都是运用runtime的相关函数实现的。
class、objc_getClass、object_getclass 方法有什么区别?
- class: [类 class] 返回本身, [实例 class] = object_getClass(实例)返回isa,其实是返回所属的类
- Class objc_getClass(const char *aClassName) 参数是类名的字符串,返回的就是这个类的类对象
- Class object_getclass(id obj) 返回该对象的isa指针,即obj的所属类
NSNotification相关
NSNotification原理解析
1,实现原理(结构设计、通知如何存储的、name&observer&SEL之间的关系等)
Observation {
block_t block;
thread_t thread;
id observer;
SEL selector;
}
NotificationCenter中有三个存储属性,
1.1,wildcard:链表,存储没有name没有observer的Observation存储在这里
1.2,named:map 有名字,有observer的存储在这里
{key(name):value(Map{key(observer):value(Observation对象)})}
1.3,nameless: map 没有名字,但是有observer的存储在这里
{key(observer):value(Observation(链表))}
2,通知的发送时同步的,还是异步的
同步
3,NSNotificationCenter接受消息和发送消息是在一个线程里吗?如何异步发送消息
3.1是在一个线程
3.2
让通知的执行方法异步执行即可
通过NSNotificationQueue,将通知添加到队列当中,立即将控制权返回给调用者,在合适的实际发送通知,从而不会阻塞当前的调用
4,NSNotificationQueue是异步还是同步发送?在哪个线程响应
NSPostingStyle为NSPostNow是同步,
NSPostWhenIdle和NSPostASAP:异步发送
5,NSNotificationQueue和runloop的关系
NSNotificationQueue将通知添加到队列中时,其中postringStyle参数就是定义通知调用和runloop状态之间关系。
该参数的三个可选参数:
NSPostWhenIdle:runloop空闲的时候回调通知方法
NSPostASAP:runloop在执行timer事件或sources事件的时候回调通知方法
NSPostNow:runloop立即回调通知方法
6,如何保证通知接收的线程在主线程
6.1 发送时使用传入主线程参数
6.2 使用machport在主线程runloop注册,在notification回调中使用machport进行线程间通信,给主线程发送消息(注意在自线程中暂存通知消息,用machport回到主线程后再执行)
7,页面销毁时不移除通知会崩溃吗
iOS9之前不行,因为notificationcenter对观察者的引用是unsafe_unretained,当观察者释放的时候,观察者的指针值并不为nil,出现也指针
iOS9之后可以,因为notificationcenter对观察者的引用是weak
8,多次添加同一个通知会是什么结果?多次移除通知呢
会调用多次observer的action
多次移除没有任何影响
9,下面的方式能接收到通知吗?为什么
// 发送通知
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(handleNotification:) name:@“TestNotification” object:@1];
// 接收通知
[NSNotificationCenter.defaultCenter postNotificationName:@“TestNotification” object:nil];
答案解析
收不到,因为有名字,有observer,在查找对应的notification的时候是在named表中找,找到的不是同一个.
Runloop & KVO
runloop
runloop对于一个标准的iOS开发来说都不陌生,应该说熟悉runloop是标配,下面就随便列几个典型问题吧
app如何接收到触摸事件的
1, 硬件处理相应,封装UIEvent发送到Application(通过注册的machport)
2, 寻找响应者,先发给手势集合,然后仔是从离屏幕最近的开始到离屏幕最远的,从父视图到子视图,通过 hitTest:withEvent
为什么只有主线程的runloop是开启的
main函数中调用UIApplicationMain,处理UI,为了让程序可以一直运行,所以开启一个常驻线程
为什么只在主线程刷新UI
1,UIKit不是线程安全的,如果多线程操作UI会产生很多渲染顺序,资源浪费等不可控情况,甚至会引起页面渲染错误导致的用户流失问题.
2,如果把UIKit设计成安全的,也并不是好的,因为UIkit设计成线程安全的,并不能提高渲染的效率,首先,渲染的过程是
-
core animation 先构建视图布局(layout),重载drawrect进行实时绘制(disply),图像解码和格式转换(prepare), 将layer递归打包发送到render server (commit)
-
render server收到后,将信息反序列化成渲染树,根据layer属性生成绘制指令,并在下一次VSync信号来到时调用OpenGL进行渲染.
-
GPU 会等待显示器的VSync信号发出后才进行OpenGL渲染管线,将3D几何数据转换成2D的像素图像和光栅处理,随后进行新的一帧渲染,并将其输出到缓冲区
-
Display, 从缓冲区中取出画面,并输出到屏幕
这里会出现渲染卡帧的问题,原因是因为在一个VSync周期内,GPU没有完成这一帧的渲染任务,导致display过程在缓冲区中拿不到画面,显示器丢帧
如果线程安全的UIKit在子线程中并发大量的提交到core animation处理页面数据,本质上,知识提升了第一步的速度和效率,但是核心的瓶颈在与GPU的处理速度和VSync的同步问题,所以,这样不但没有提升效率和体验,反而提高了风险和耗损,降低了用户体验
PerformSelector和runloop的关系
PerformSelector会在线程的runloop中添加一个Timer,到时去发送指定的消息,
如果某一个线程的runloop没有开启,那么performSelector将不会生效,因为Timer依赖runloop,如果runloop没有启动,那么timer并不能执行,进而方法无法调用
如何使线程保活
1,在线程中加入MachPort
2,在线程中开启where(YES)的循环,优化一点就是加入信号量,模拟runloop eg:
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0)
线程内 {
while(YES) {
dispatch_semaphore_wait(semaphore);
if (退出条件满足) {
break;
}
}
}
dispatch_semaphore_signal(semaphore);
KVO
同runloop一样,这也是标配的知识点了,同样列出几个典型问题
实现原理
- 继承原来的类,实现一个单独的子类
- 重写被检测属性的Set方法,在方法中插入两个方法,开头调用willchange,最后调用didchange,
- isa swizzing, 将原来类的isa指向子类,所以,在调用被检测者的Set方法时,runtime会沿着isa的指向找到对应的类中找方法,顺其自然就找到了新创建的子类中,子类也有重写的set方法,也就顺其自然的执行了,KVO的过程也就实现了,
- 注意,子类的class也被重写了,返回的事父类的名字,这里假装是父类
KVO属性依赖
比如有一个教 fullName 的属性,依赖于 firstName 和 lastName,当 firstName 或者 lastName 改变时,这个 fullName 属性需要被通知到。
- (NSString *)fullName {
return [NSString stringWithFormat:@"%@ %@",firstName, lastName];
}
你可以重写 keyPathsForValuesAffectingValueForKey: 方法。其中要先调父类的这个方法拿到一个set,再做接下来的操作。
-
(NSSet *)keyPathsForValuesAffectingValueForKey:(NSString *)key {
NSSet *keyPaths = [super keyPathsForValuesAffectingValueForKey:key];
if ([key isEqualToString:@“fullName”]) {
NSArray *affectingKeys = @[@“lastName”, @“firstName”];
keyPaths = [keyPaths setByAddingObjectsFromArray:affectingKeys];
}
return keyPaths;
}
你也可以通过实现 keyPathsForValuesAffecting 方法来达到前面同样的效果,这里的就是属性名,不过第一个字母要大写,用前面的例子来说就是这样: -
(NSSet *)keyPathsForValuesAffectingFullName {
return [NSSet setWithObjects:@“lastName”, @“firstName”, nil];
}
pthread_t NSTread 的关系
如何手动关闭kvo
重写 automaticallyNotifiesObserversForKey 方法
通过KVC修改属性会触发KVO么
会,
kvc的原理就是先去调用setKey方法、_setKey 方法
找不到set方法直接设置属性 _key key isKey内部会间听到值的改变
哪些情况下使用kvo会崩溃,怎么防护崩溃
- 移除一个未注册的keyPath
- 观察者已经销毁,但是没有被移除,当观察者的对象发生变化的时候,kvo中的观察者变成了也指针,导致crash
kvo的优缺点
- 不能用block的形式获取通知
- 不能指定自己的selector获取通知
Block
block的内部实现,结构体是什么样的
block是类吗,有哪些类型
一个int变量被 __block 修饰与否的区别?block的变量截获
block在修改NSMutableArray,需不需要添加__block
怎么进行内存管理的
block可以用strong修饰吗
解决循环引用时为什么要用__strong、__weak修饰
block发生copy时机
Block访问对象类型的auto变量时,在ARC和MRC下有什么区别
多线程
主要以GCD为主
iOS开发中有多少类型的线程?分别对比
| 线程框架 | 描述 | 语言 | 生命周期管理 |
|---|---|---|---|
| pthread | 跨平台、Unix/Linux/Windows、使用难度大 | C | 程序员管理 |
| NSThread | 面向对象,可操作线程对象,简单易用 | OC | 程序员管理 |
| GCD | 简单易用,API使用block,代码集中 | C | 自动管理 |
| NSOperation | 基于GCD,多了一些简单实用的功能,比如最大并发数,使其更加面向对象 | OC | 自动管理 |
GCD有哪些队列,默认提供哪些队列
两大类
serial dispatch queue (串行队列) main dispatch queue
concurrent dispatch queue (并行队列) dispatch_global_queue
GCD有哪些方法api
dispatch_sync
dispatch_async
dispatch_once
dispatch_queue_create
dispatch_semaphore_create
dispatch_semaphore_wait
dispatch_semaphore_signal
dispatch_group_create
dispatch_group_enter
dispatch_group_leave
dispatch_set_target_queue
dispatch_barrier_sync
dispatch_barrier_async
dispatch_after
dispatch_apply
dispatch_source_t
GCD主线程 & 主队列的关系(未掌握)
如何实现同步,有多少方式就说多少
1,穿行队列,并发为1
2,dispatch_group_enter dispatch_group_leave
3,dispatch_semaphore_wait dispatch_semaphore_signal
4,dispatch_barrier
5,dispatch_group_notify
6,dispatch_block_wait
7,dispatch_block_notify
dispatch_once实现原理
void dispatch_once_f(dispatch_once_t *val, void *ctxt, void (*func)(void *)){
// val == 0
volatile long *vval = val;
// 第一个线程进来
// dispatch_atomic_cmpxchg(p,l,n) 方法的功能是原子操作
// 方法含义为如果p==l 则 将n赋值给p, 并且返回true
// 如果p != l 则返回 false
// 所以第一次进来 val == 0 , val被赋值为1 , 并且返回ture
if (dispatch_atomic_cmpxchg(val, 0l, 1l)) {
func(ctxt); // block真正执行
// dispatch_atomic_barrier 是一个编译器操作,意思为前后指令的顺序不能颠倒.这里是防止编译器优化将原本的指令语义破坏
dispatch_atomic_barrier();
// 将vval赋值为非零
*val = ~0l;
}
else
{
// 如果在第一个线程进来后执行上边代码块的同时,有其他的线程进来执行
// 则进入空循环,等待vval被赋值为非零.
do
{
// 这有助于提高性能和节省CPU耗电,延迟空等
_dispatch_hardware_pause();
} while (*vval != ~0l);
dispatch_atomic_barrier();
}
}
什么情况下会死锁
死锁发生的条件
- 互斥条件: 某一个资源被占用后,不允许其他线程进行访问,其他线程请求时只能等待被释放后才能使用
- 请求和保持条件: 线程获得资源后,又对其他资源发出请求,但是该资源可能被其他线程占有,此时请求阻塞,但是又对自己获得的资源保持不放
- 不可剥夺条件: 线程已经获得的资源,在未完成使用之前,不可被剥夺,只能使用完成后自己释放
- 环路等待条件: 线程发生死锁后,必然存在一个线程-资源之间的环形链.
比如:
eg1:主线程调用主线程同步任务
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"发生死锁");
});
dispatch_sync(dispatch_get_global_queue(0, 0), ^{
NSLog(@"hhaah");
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"dkjfks");
});
});
有哪些类型的线程锁,分别介绍下作用和使用场景
https://blog.csdn.net/deft_mkjing/article/details/79513500
自旋锁: 线程反复检查所变量是否可用,线程这一过程中保持执行,因此是一种忙等状态,一旦获取了,线程一直保持,直到显示的释放,自旋锁避免了进程上下文切换的开销,因此,对于线程只阻塞很短的场合是有效的.
- OSSpinLock
互斥锁: 避免两个线程同时对某一变量进行读写,通过将代码切片成一个个临界区而达成
- NSLock
- pthread_mutex
- @sysnchronized
- os_unfair_lock
信号量:
- dispatch_semaphore
条件锁:
- NSCondition
读写锁
- pthread_rwlock
- pthread_mutex(recursive)
- NSRecursiveLock
- NSConditionLock
- os_unfair_lock(ios 10)之后
OSSpinLock已经被弃用,因为会出现低优先级线程持有锁,然后高优先级去获取锁的时候,spin lock会进入忙等状态,占用大量cpu时间,这时低优先级队列无法争夺cpu时间片,从而导致任务无法完成,无法释放lock
NSOperationQueue中的maxConcurrentOperationCount默认值
这个志向了一个静态变量,值为-1,是根据系统情况去分配他的数值.
NSTimer、CADisplayLink、dispatch_source_t 的优劣
视图&图像相关
定时器都是依赖runloop运行的,
NSTimer是最见的定时器,注意在使用的时候在滑动的时候不会被触发,需要加入到runloop commonmode 中,在没有runloop运行的子线程,也不会执行
有内存泄漏问题,注意invalied.提供了比较多的初始化方法.比较方便易用
CADisplaylink 是根据屏幕刷新频率处罚的定时器,苹果目前的屏幕刷新频率为60HZ,华为刚出了一个90HZ的以后可能这需要注意下改动,在不同的手机上是不同的频率,他比较准确,在没有什么耗时任务卡住runloop的情况下,很稳定,但是不灵活,适合做UI刷新,添加进runloop即刻启动
dispatch_source_t 是基于gcd 给runloop添加source而实现的定时任务.更加精确,可以设置冗余时间,可以放到子线程
AutoLayout的原理,性能如何
自动布局 Auto Layout (原理篇)
UIView & CALayer的区别
1,UIView是CAlayer的外壳,用来处理响应,包装Layer,继承自UIResponder
2,Layer是实际渲染层,用来处理视图属性,他的代理是UIView,view的frame、bounds等属性实际都是来自layer
3,Layer维护着逻辑树(这里是代码可以操作的),动画树(中间层,系统在此层修改属性,进行渲染相关的操作),显示树(其内容就是现在正被显示在屏幕上的内容)
4,坐标系统:layer比view多了anchorPoint,是各种图形变换的坐标原点,同时会更改layer的position的位置,缺省值为「0.5,0.5」,即layer中央
UIView & CALayer的区别
事件响应链
1,手指点击屏幕,硬件将响应消息转化为UIEvent传入正在活跃的应用时间队列
2,发给手势系统,看看是否可以响应,如果不能,则进入应用
2,第一层是UIWindow响应,调用pointInside:withEvent 检查点是否在该视图内.如果是,通过hitTest:withEvent 调用所有子视图的pointInside:withEvent,和hitTest:withEvent
规则
1,pointInside:withEvent 返回NO,什么都不做
2,pointInside:withEvent 返回YES, 调用对应的hitTest:withEvent,递归检查子视图是否是可以响应事件.
3,pointInside:withEvent 返回YES,并且没有子视图,hitTest:withEvent返回自己,并逐层翻上去.
至此便找到了响应者.
这时响应者链,事件传递链就是一层层翻上去,看看谁可以响应事件.
drawrect & layoutsubviews调用时机
1,drawrect用来拿到上下文绘制视图内容,在UIView的子类中
2,drawrect调用时机:
2.1:loadview之后
2.2:待用setNeedsDisplay或者setNeedsDisplayInRect:出发drawrect,前提条件为view必须有rect
2.3 该方法在调用sizeThatFits后被调用,所以可以先调用sizeToFit计算出size。然后系统自动调用drawRect:方法。
这里简单说一下sizeToFit和sizeThatFit:
sizeToFit:会计算出最优的 size 而且会改变自己的size
sizeThatFits:会计算出最优的 size 但是不会改变 自己的 size
3, layoutsubviews是用来重新布局,(比如改变子视图位置)默认方法中什么都不干,开发者可以自己重写
4, 调用时机:
4.1, setNeedLayout标记,在下一轮runloop时调用layoutsubviews
4.2, 如果在setNeedLayout后立即调用layoutIfNeed会立即出发layoutsubviews
系统调用时机:
1, init不会触发
2, addsubviews会触发layoutSubviews (前提为frame有值)
3, 改变view的frame会触发
4, 滚动srollview
5, 旋转会触发父视图的layoutsubviews
6, 直接调用layoutsubviews
layoutsubviews早于drawrect调用. 前者布局相关,后者绘制相关
UI的刷新原理

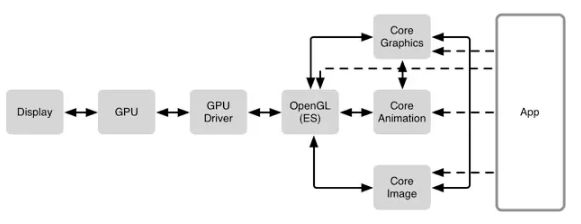
一 图形渲染过程
视图渲染
1,我们创建的View,设置视图相关的属性,比如frame,backgroundcolor,textcolor等,背后实际体现在CALayer上
2,Core Animation将layer解析成图层树,每个节点存储着layer相关的frame,bounds,transform等属性,图层数还能表达各个图层之间的关系.
3,CoreAnimation 依赖于OpenGL ES或者Metal做GPU渲染,Core Graphics做CPU渲染.如上图所示,在屏幕上显示视图,CPU和GPU要写作,一部分数据通过CoreGraphics、CoreImage由CPU预处理,最终由OpenGL ES或者metal将数据传送到GPU,最终显示到屏幕
3.1,CoreGraphic基于Quartz高级绘画引擎,主要用于运行时图像绘制,开发者可以用来处理基于路径的绘图,转换,颜色管理,离屏渲染,图案,渐变和阴影,图像数据管理,图像创建和图像遮照以及PDF文档创建、显示和分析
3.2,CoreImage用于运行前创建的图像,大部分情况下CoreImage在GPU中完成工作,如果GPU忙,会使用CPU进行处理.支持两种处理模式
显示逻辑
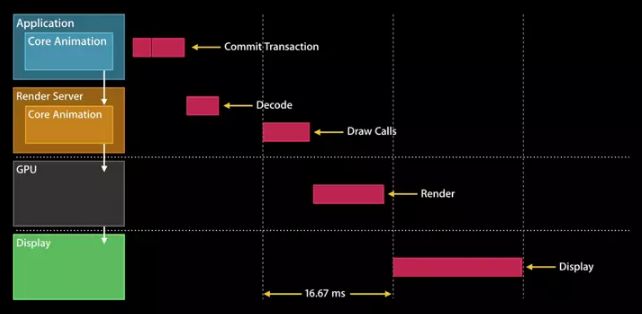
1,CoreAnimation提交会话(包括自己和子树的layout状态等)
2,RenderServer解析提交的子树状态,生成绘制指令
3,CPU执行绘制指令
4,显示渲染后的数据
Core Animation提交流程
在CoreAnimation流水线中,App调用Render Server前的最后一步,Commit Transaciton分为四个步骤
- Layout:视图构建,layoutSubviews方法重载,addSubview方法填充子视图,主要就是进行layer的创建
- Display:视图绘制,设置要成像的图元数据.重载视图的drawRect:方法可以自定义UIView的显示,原理是drawrect方法内部绘制寄宿图,该过程使用CPU和内存,绘制完成放入layer的contents属性指向的backing store
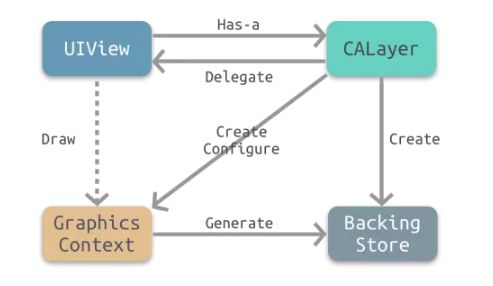
- 具体见http://chuquan.me/2018/09/25/ios-graphics-render-principle/
- Prepare: 准备阶段,该阶段一般处理图像解码和转换工作.
- Commit: 将图层进行打包(序列化),并发送至Render Server,该过程递归执行,因为图层和视图都是以树形存在.
- 当runloop进入休眠(BeforeWaiting)和退出(Exit)会通知Observer调用
_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv进行打包,并发送至Render Server - 这里CoreAnimatino会创建一个OpenGL ES纹理,并确保位图被上传到对应纹理中.
- 当runloop进入休眠(BeforeWaiting)和退出(Exit)会通知Observer调用
渲染服务(Render Server)
- 反序列化CoreAnimation提交的数据.
- 过滤图层间遮挡部分
- 将图层书转化为渲染树(对应每个图层的信息,比如顶点坐标、颜色等信息的抽离出来,形成树状结构)
- 将渲染树递归提交给OpenGL ES/Metal
- OpenGL/Metal生成绘制命令,结合固定的渲染管线.提交到命令缓冲区(CommandBuffer)供GPU读取使用
图形渲染管线(Graphics Rendering Pipeline)
OpenGL/Metal的作用是在CPU上生成GPU可以理解的一系列指令,并提交给GPU
图形渲染管线,实际上指的是一堆原始图形数据经过一个输送管道,期间经过各种变化处理最终出现在屏幕的过程,通常情况下,渲染管线可以描述成vertices(顶点)到pixels(像素)的过程
如图:

关于图中详细解析,看链接内
屏幕显示

CPU计算显示内容–>GPU渲染–>渲染结果放到帧缓冲区(iOS是双缓冲)–>视频控制器按照VSync信号逐行读取帧缓冲区数据,传递给显示器显示

隐式动画 & 显示动画区别
什么是离屏渲染
imageName & imageWithContentsOfFile区别,多个相同的图片,会重复加载吗?
imageName:
加载后会由系统管理内存,内存占用比较小,对象释放,内存不会,多次加载相同图片不会重复加载.
适合小图片,频繁重复加载的场景
imageWithContentsOfFile:
内存占用小,相同图片会重复加载,重复占用内存,对象释放,对应的内存也会释放.
适合大图片,不频繁重复加载的场景
图片是什么时候解码的,如何优化
解码:png,jpeg这种都是压缩格式,解码就是解压缩的过程,
图片解码需要大量计算,耗时长,iOS创建UIImage 或者 CGImageSource的时候并不会立即解码,图片设置到UIImageView或者CALayer.contents中的时候,并且CALayer被提交到GPU前,CGImage中的数据才会解码,并且是在主线程.不可避免.
优化方案:
后台线程把图片会知道CGBitmapContext中,然后从Bitmap直接创建图片,
图片渲染怎么优化
图片渲染怎么优化
1,下载图片
2,图片处理(裁剪,边框等)
3,写入磁盘
4,从磁盘读取数据到内核缓冲区
5,从内核缓冲区复制到用户空间(内存级别拷贝)
6,解压缩为位图(耗cpu较高)
7,如果位图数据不是字节对齐的,CoreAnimation会copy一份位图数据并进行字节对齐
8,CoreAnimation渲染解压缩过的位图
以上4,5,6,7,8步是在UIImageView的setImage时进行的,所以默认在主线程进行(iOS UI操作必须在主线程执行)。
如果GPU的刷新率超过了iOS屏幕60Hz刷新率是什么现象,怎么解决
1,GPU处理完后会放入帧缓冲区,视频控制器定时读取缓冲区内容,给屏幕显示
2,如果缓冲区允许覆盖,那么就会产生丢帧,或者和面断层.不允许覆盖,就会丢帧
可以用双缓冲区,或者加大缓冲区的方案解决
性能优化
App启动过程
精准计算启动时间
如何做启动优化,如何监控
XCode中有debug工具:
对于如何测试启动时间,Xcode 提供了一个很赞的方法,只需要在 Edit scheme -> Run -> Arguments 中将环境变量 DYLD_PRINT_STATISTICS 设为 1,就可以看到 main 之前各个阶段的时间消耗
冷启动,热启动
慢的原因是因为主线程的工作量大,比如IO,大量计算
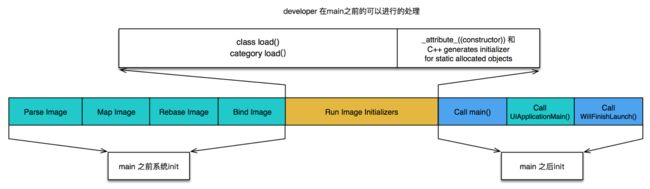
从启动周期每一步分析,优化
main执行之前
main执行之后
首屏渲染之后
main执行之前
- 加载可执行文件(App的.o文件合集)
- 加载动态链接库,进行rebase和bind符号绑定
- Objc运行时预备处理,类注册,category注册,selector唯一性检查等
- 初始化,load方法执行,attribute((constructor))修饰的函数调用,创建C++静态全局变量.
可优化方案:
- 减少动态库加载
- load方法中的内容尽量放到首屏渲染后在执行或换成在initialize中执行
- 控制C++全局变量的数量
- 减少不用的类(类别)和方法
main函数执行之后
这个阶段一般是从AppDelegate的applicationDidFinishLaunching的方法到首屏渲染,展示欢迎页这个阶段
一般包含的动作有:
- 首屏初始化所有配置文件的读写操作
- 首页数据读取
- 首屏渲染计算
可优化方案:
- 只放和首屏渲染相关的业务代码,其他非首屏业务的初始化监听注册,配置文件读取放到首屏渲染后
- 使用time profiler观察方法耗时,优化对应的方法
监控方案:
1,定时任务获取主队列的调用栈,0.002获取一次,记录每次获取的方法内容,对应方法时间累加
2,hook objcMsgSend方法 获取每个方法前后时间,记录时间,需要汇编,难度大
3,使用XCode工具 Timer Profiler 观察方法耗时
如何做卡顿优化,如何监控
卡顿原因:
在一个VSync内GPU和CPU的协作,未能将渲染任务完成放入到帧缓冲区,视频控制器去缓冲区拿数据的时候是空的,所以卡帧
卡顿优化
- 图片等大文件IO缓存
- 耗时操作放入子线程
- 提高代码执行效率(JSON to Model的方案,锁的使用等,减少循环,UI布局frame子线程预计算)
- UI减少全局刷新,尽量使用局部刷新
监控卡帧
-
CADisplayLink 监控,结合子线程和信号量,两次事件触发时间间隔超过一个VSync的时长,上报调用栈
-
在runloop中添加监听,如果kCFRunLoopBeforeSources和kCFRunLoopBeforeWaiting中间的耗时超过VSync的时间,那么就是卡帧了,然后这个时候拿到线程调用栈,看看,那个部分耗时长即可.
如何做耗电优化,如何监控
使用定时器,每隔一段时间获取一次电量,并上报
+ (float)getBatteryLevel {
[UIDevice currentDevice].batteryMonitoringEnabled = YES;
return [UIDevice currentDevice].batteryLevel;
}
电量优化(原则尽量少的减少计算)
- 降低地理位置的刷新频次,蓝牙和定位按需获取.不用关掉
- 整合UI刷新,降低刷新频次
- 避免使用透明元素,image和imageview大小设置相同降低计算
- 使用懒加载,不用的东西不要提前创建
- 选择合适的数据结构存储数据,
NSArray,使用index来查找很快(插入和删除很慢)
字典,使用键来查找很快
NSSets,是无序的,用键查找很快,插入/删除很快 - timer时间不宜太短,设置合理的leeway
- 控制线程个数
- 优化算法,减少不必要的循环
如何做网络优化,如何监控
网络优化分为,提速,节流,安全,选择合理网络协议处理针对的业务(比如聊天的,用socket)
提速
- 增加缓存,比如图片缓存,H5缓存,列表页数据放入数据库缓存
- 降低请求次数,多个借口合并,这里需要服务端配合
- 压缩传输内容,减少不必要数据传输
节流
- 压缩思路同上
- 在用户角度上,在视频等大流量场景要判断是否为wifi网络,并提示用户
安全
- https
- 数据加密,防止中间人窃听
- 加入签名,防止中间人篡改
- 加入https证书校验,防止抓包
开发证书
苹果使用证书的目的是什么
为了防止开发者的应用随意安装在手机上,用证书控制,只有经过苹果允许的应用才可以安装上,防止盗版什么的
这么做的目的是为了整个应用生态的体验着想,当然也有安全因素在里边.
AppStore安装app时的认证流程
AppStore安装app时的认证流程
开发者怎么在debug模式下把app安装到设备呢(这个题不会)
架构设计
典型源码的学习
只是列出一些iOS比较核心的开源库,这些库包含了很多高质量的思想,源码学习的时候一定要关注每个框架解决的核心问题是什么,还有它们的优缺点,这样才能算真正理解和吸收
AFN
AFN3.0解析
AFN2.0解析
SDWebImage
JSPatch、Aspects(虽然一个不可用、另一个不维护,但是这两个库都很精炼巧妙,很适合学习)
Weex/RN, 笔者认为这种前端和客户端紧密联系的库是必须要知道其原理的
CTMediator、其他router库,这些都是常见的路由库,开发中基本上都会用到
请圈友们在评论下面补充吧
架构设计
手动埋点、自动化埋点、可视化埋点
-
手动埋点:代码侵入,不好维护,无法线上动态,但是灵活
-
自动化埋点:全量获取,自定义程度低,灵活性差,效率低.好处是容错高
技术原理:hook关键方法,一类事件的统一入口或者出口,比如统计PV用viewcontroller的viewdidload.统计点击事件用UIControl的sendAction:to:forEvent等 -
可视化买点:开发代价大,自定义程度低,灵活性差.好处就是的运营人员上手快.对业务发展由好处.
MVC、MVP、MVVM设计模式
MVC/MVP/MVVM 三种设计模式简介附demo
常见的设计模式
单例,工厂,MVC、MVP、MVVM、观察者,代理,装饰模式
单例的弊端
- 内存一直占用,滥用导致内存浪费
- 线程安全问题多地方使用其中的数据,线程安全需要注意
- 内容数据如果影响多个地方,代码耦合度很高.
常见的路由方案,以及优缺点对比
如果保证项目的稳定性
设计一个图片缓存框架(LRU)
如何设计一个git diff
设计一个线程池?画出你的架构图
你的app架构是什么,有什么优缺点、为什么这么做、怎么改进
其他问题
PerformSelector & NSInvocation优劣对比
oc怎么实现多继承?怎么面向切面(可以参考Aspects深度解析-iOS面向切面编程)
哪些bug会导致崩溃,如何防护崩溃
怎么监控崩溃
app的启动过程(考察LLVM编译过程、静态链接、动态链接、runtime初始化)
沙盒目录的每个文件夹划分的作用
简述下match-o文件结构
系统基础知识
进程和线程的区别
HTTPS的握手过程
什么是中间人攻击?怎么预防
TCP的握手过程?为什么进行三次握手,四次挥手
堆和栈区的区别?谁的占用内存空间大
栈由编译器申请空间大小,是固定的,连续的,对应线程是唯一的,快速高效,缺点是有限制,先入后出不灵活
堆区是通过alloc分配的,它的内存空间是动态的,由一个空闲内存空间指针链表维护,内存空间不连续,可以很大,但是容易内存碎片化.好处就是查询快.
###加密算法:对称加密算法和非对称加密算法区别
对称加密:
- 加解密一个key
- 安全性低
- 速度快
- 无法确认来源
非对称加密:
- 公钥 私钥
- 安全性高,
- 速度慢
- 可以确定来源
常见的对称加密和非对称加密算法有哪些
对称加密:
DES 3DES AES
非对称加密:
RSA DSA
MD5、Sha1、Sha256区别
MD5 输出128位
SHA1 输出160位
SHA256 输出256位
charles抓包过程?不使用charles,4G网络如何抓包
数据结构与算法
对于移动开发者来说,一般不会遇到非常难的算法,大多以数据结构为主,笔者列出一些必会的算法,当然有时间了可以去LeetCode上刷刷题
八大排序算法
栈&队列
字符串处理
链表
二叉树相关操作
深搜广搜
基本的动态规划题、贪心算法、二分查找
必看
直击2020
神经病院objc runtime入院考试
靠谱的 iOS
还没有熟悉的点
Objc的底层并发API
NSURLCache
1, GCD的源码分析
相关文档:
iOS主线程和主队列的区别
多线程-奇怪的GCD
被遗弃的线程
dispatch_async与dispatch_sync区别
GCD容易让人迷惑的几个小问题
深入理解gcd
深入理解GCD之dispatch_queue
Objective-C runtime机制(5)——iOS 内存管理
Https单向认证和双向认证
Flutter安装