python爬取视频网站中video标签的m3u8文件与ts文件
文章目录
- 网站分析
- 代码
- 参数配置
- 下载m3u8文件
- 下载ts文件
- 单线程
- 多线程
- 解密
- 合并
- 转换为MP4
网站分析
许多网站使用的都是video加载的视频,无法获得视频的源地址。

但是通过抓包可以获得两类文件,一类是m3u8,相当于ts文件的索引将不同的ts文件串起来;另一类是很多个ts片段,由这些片段构成我们观看的视频。
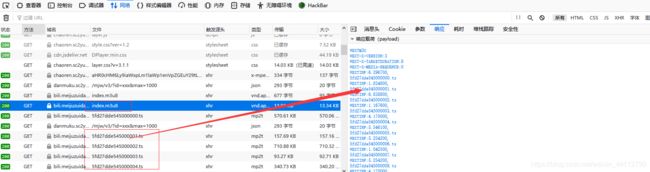
上图的m3u8文件显示的ts文件是未加密的,所以下载下来的ts文件可以直接播放;下载的时候还能注意到这两类文件的是源自同一个上级链接比如https://xxx.com/xxx/index.m3u8和5fd27dde545000000.ts。
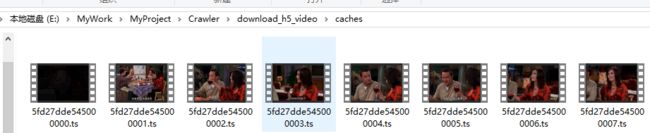
只要将这些文件按顺序拼接为完整的文件就相当于下载成功了,值得注意的是命名格式为5fd27dde545000{}.ts,{}的数字不足3位3位补齐如5fd27dde545000000.ts,大于3位不用补齐如5fd27dde5450001000.ts。
代码
参数配置
为了方便使用,将一些参数单独拿出来作为配置文件。
# 下载必须的配置
URL_BASE = 'https://xxx.com/xxx/{}' # m3u8文件的链接
PATTERN = 'xxx(\d+).ts' # 提取ts片段索引号的正则
# 下面是多线程需要配置的
TS_BASE = 'xxx{}.ts'
THREAD_NUM = 15 # 线程数
TS_NUM = 347 # ts文件的个数,在index.m3u8中找到最后一个ts是多少就写多少
下载m3u8文件
只有一个下载,比较简单,主要是根据它判断是否有加密
def download_m3u8(url):
response = requests.get(url)
file = "./caches/" + url.split("/")[-1]
with open(file, "w", encoding="utf8") as f:
f.write(response.text)
加密的话,会多出一行记录加密方式和密钥,没有这一行就没有加密。
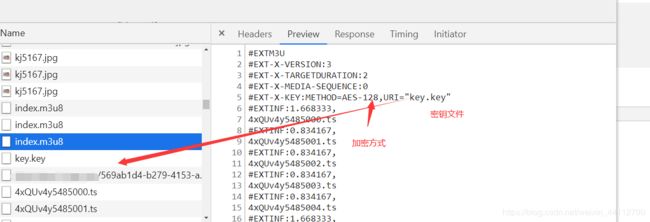
下载ts文件
单线程
有了之前的配置就可以根据我封装的方法下载ts文件了,这里提供两种方式。如果传入ts_list那么下载传入的,否则根据TS_BASE生成ts_list进行下载。
def download_ts(ts_list=None):
'''
:param ts_list: [xxx000.ts, ..., xxx999.ts]
:return:
'''
# 如果ts列表为空,那么构造ts列表
if ts_list is None or len(ts_list) == 0:
ts_list = []
for i in range(0, TS_NUM+1):
idx = str(i) if i > 999 else str(i).zfill(3)
ts_list.append(TS_BASE.format(idx))
# 根据ts列表下载文件
for item in ts_list:
url = URL_BASE.format(item)
file="./caches/"+url.split("/")[-1]
response = my_request(url)
with open(file, "wb") as f:
f.write(response.content)
print(url, file)
其中ts_list可以根据m3u8文件获得,my_request()是我为了实现失败自动重试封装的一个方法https://blog.csdn.net/weixin_44112790/article/details/104197569。
def read_m3u8(file):
ts_list = []
with open(file) as f:
for line in f:
s = line.strip()
if s.find(".ts") > -1:
ts_list.append(s)
return ts_list
@retry() # 利用retry装饰函数,使得抛出异常的时候自动重试知道成功。
def my_request(url):
requests.adapters.DEFAULT_RETRIES = 15
s = requests.session()
s.keep_alive = False # 关闭之前的连接,避免连接过多
try:
response = requests.get(url, timeout=5)
except BaseException: # 捕获异常的时候,这里粗略的写了BaseException,根据需要可写的更具体。
print(url, "请求失败,开始重试")
response = requests.get(url, timeout=5)
return response
到这里,应该可以成功将所有的ts文件下载下来。
from config import *
if __name__ == '__main__':
download_m3u8(URL_BASE.format("index.m3u8"))
# download_ts()
# ts_list = read_m3u8("./caches/index.m3u8")
# download_ts(ts_list)
多线程
为了提高下载速度,可以配置多线程的一些参数用多线程进行下载。
import requests
import time
import threading
# 使用 threading 模块创建线程
import queue
#优先级队列模块
#线程优先级队列(Queue)
from config import *
from retrying import retry
exitFlag = 0
class MyThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print("开启线程:" + self.name+"\n")
download_data(self.threadID, self.name, self.q)
print("退出线程:" + self.name+"\n")
def download_data(id,thread_name, q):
@retry()
def my_request(url):
requests.adapters.DEFAULT_RETRIES = 15
s = requests.session()
s.keep_alive = False
try:
response = requests.get(url, timeout=5)
except BaseException:
print(url, "请求失败,开始重试")
response = requests.get(url, timeout=5)
return response
while not exitFlag:
id += 1
if id >= THREAD_NUM:
data = q.get()
url = URL_BASE.format(data)
file = "./caches/" + url.split("/")[-1]
response = my_request(url)
with open(file, "wb") as f:
f.write(response.content)
print(thread_name, url, file)
if __name__ == '__main__':
work_queue = queue.Queue(TS_NUM+1)
threads = []
# 填充队列
for i in range(0, TS_NUM+1):
idx = str(i) if i > 999 else str(i).zfill(3)
work_queue.put(TS_BASE.format(idx))
# 创建新线程并且启动
for thread_id in range(0, THREAD_NUM):
thread = MyThread(thread_id, "Thread-{}".format(thread_id), work_queue)
thread.start()
threads.append(thread)
# 等待队列清空
while not work_queue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print("退出主线程")
解密
如果没有加密直接跳过这一步,进入合并即可。
import os
import re
from Crypto.Cipher import AES
from config import PATTERN, TS_NUM
def check_ts(path):
# 记录已有的片段
lst = os.listdir(path)
ts_idx_list = []
for item in lst:
if item.find('.ts') > 0:
idx = int(re.findall(PATTERN, item)[0])
ts_idx_list.append(idx)
# 检查缺失了哪些片段
for idx in range(0, TS_NUM):
if not idx in ts_idx_list:
print(idx)
print("一共缺少{}个".format(TS_NUM+1-len(ts_idx_list)))
def decode_ts(src, key_path, target):
'''
:param src: 单个加密后的ts源文件路径 如 './caches/ntROGW6R4598270.ts'
:param key_path: 解密key的路径 如 './caches/key.key'
:param target: 解密后的文件名 如 './results/ntROGW6R4598270.ts'
:return:
'''
raw = open(src, 'rb').read()
iv = raw[0:16]
data = raw[16:]
key = open(key_path, 'rb').read()
plain_data = AES.new(key, AES.MODE_CBC, iv).decrypt(data) # 解密失败的话可以换一种模式看看
open(target, 'wb').write(plain_data)
if __name__ == '__main__':
path = './caches/'
check_ts(path) # 检查有没有缺失片段
# 读取缓存批量解密
lst = os.listdir(path)
for item in lst:
if item.find('.ts') > 0 and re.findall(PATTERN, item)[0] >="0": # 后面的条件可以更改解密的开始位置
decode_ts(path+item, path+'key.key', './results/'+item)
print(item)
目录结构是caches和results的话,就可以直接运行我的代码,否则需要自己改一下目录。
合并
将可播放的ts文件片段按顺序合并成一个文件,一定要按顺序!
import os
import re
from config import PATTERN
output = open('./last_result.ts', 'wb+')
ts_list = os.listdir('./results')
ts_list.sort(key=lambda ts : int(re.findall(PATTERN, ts)[0]))
for ts in ts_list:
print(ts)
with open('./results/'+ts, 'rb') as f:
output.write(f.read())
很简单的文件读写操作即可完成,同样注意目录要和代码中的一致。
转换为MP4
合并完的ts文件,已经可以正常播放了,如果有特殊需求可以用ffmpeg将文件转为MP4或者其他格式。
ffmpeg -i xxx.ts xxx.mp4
去下载相应版本的ffmpeg即可使用https://ffmpeg.zeranoe.com/builds/