你的年收入过5万了吗?数据科学家的Python模块和包
全文共2327字,预计学习时长15分钟

图源:unsplash
笔者刚开始学习给数据科学编程时,发现要找到创建模块和包的简单解释以及教程非常困难,尤其是数据科学项目方面。
数据科学代码通常是非常线性的。一般情况下,要先从数据源提取数据,应用一系列转换,然后执行分析、计算或训练模型。但是为了代码的可读性、高效性和可重复性,将代码模块化并打包很有用。
本文将告诉你如何为数据科学和机器学习创建和使用自己的包和模块。笔者将使用成年人数据集,这个数据集通常用来建立分类机器学习模型,目标是预测给定成年人的年收入是否超过5万美元。

模块的数据科学用例
Python模块仅仅是Python的一组操作,通常是函数形式,保存在扩展名为.py的文件中。可以将该文件导入到Jupyter notebook、IPython shell或其他模块中,以便在项目中使用。
尝试运行一个实例。如下代码(从CSV文件中读取)将使用Pandas:
import pandas as pddata =pd.read_csv('adults_data.csv')
data.head()

这个数据集包含许多分类特征。如果打算用它来训练机器学习模型,就需要先执行一些预处理。通过分析这些数据,笔者决定在训练模型之前,采取以下步骤对数据进行预处理。
· 将雇主的单位类型、婚姻状况、家庭关系、种族和性别进行独热编码。
· 选取最常见的值,将余下的值归为“其他”,并对结果特征进行独热编码。该操作在最高教育水平、工作类型、原籍国中执行,因为它们包含大量特殊的值。
· 缩放剩余数值。
执行这些任务需要编写大量代码,这些任务都可能被多次执行,为使代码更具可读性并易于重用,可以将一系列函数写入到一个单独的文件中,并导入到 notebook(一个模块)中使用。

图源:unsplash
编写模块
要创建模块,就需要创建扩展名为.py的新空白文本文件。可以使用普通的文本编辑器,但也有许多人使用集成开发环境(Integrated Development Environment, IDE)。
集成开发环境为编写代码提供了很多附加功能,包括编译代码、调试和与Github集成的工具。它有许多不同类型可用,值得自行尝试,以发现最适合的一款。笔者个人更喜欢PyCharm。
笔者先创建了新的Python文件用以编写模块:
将其命名为preprocessing.py:
在这个文件中编写第一个预处理函数,并且在Jupyter Notebook中测试导入和使用。
preprocessing.py文件的顶部的代码如下,并为其添加了一些注释,理解起来是不是容易多了。
def one_hot_encoder(df,column_list):
"""Takes in adataframe and a list of columns
for pre-processing via one hotencoding"""
df_to_encode = df[column_list]
df = pd.get_dummies(df_to_encode)
return df
将此模块导入Jupyter Notebook中,只需编写以下代码:
import preprocessing as pr
autoreload是IPython的扩展,用起来方便快捷。倘若在导入之前添加了如下代码,无论在模块文件中做出了何种更改,都将同步反映在Notebook中。
%load_ext autoreload
%autoreload 2import preprocessing as pr
测试一下,使用它对数据进行预处理:
cols = ['workclass','marital-status', 'relationship', 'race', 'gender']one_hot_df =pr.one_hot_encoder(data, cols)
现在,将余下的预处理函数添加到preprocessing.py 文件中:
def one_hot_encoder(df,column_list):
"""Takes in adataframe and a list of columns
for pre-processing via one hotencoding returns
a dataframe of one hot encodedvalues"""
df_to_encode = df[column_list]
df = pd.get_dummies(df_to_encode)
return df
def reduce_uniques(df, column_threshold_dict):
"""Takes in adataframe and a dictionary consisting
of column name : value countthreshold returns the original
dataframe"""
for key, value incolumn_threshold_dict.items():
counts = df[key].value_counts()
others = set(counts[counts< value].index)
df[key] =df[key].replace(list(others), 'Others')
returns a dataframe of scaledvalues"""
df_to_scale = df[column_list]
x = df_to_scale.values
min_max_scaler =preprocessing.MinMaxScaler()
x_scaled =min_max_scaler.fit_transform(x)
df_to_scale = pd.DataFrame(x_scaled,columns=df_to_scale.columns)
return df_to_scale
如果返回到Notebook,就可以使用所有的函数来转换数据:
import pandas as pd
from sklearn import preprocessing%load_ext autoreload
%autoreload 2import preprocessing as prone_hot_list = ['workclass','marital-status', 'relationship', 'race', 'gender']
reduce_uniques_dict = {'education' : 1000,'occupation' : 3000, 'native-country': 100}
scale_data_list = data.select_dtypes(include=['int64','float64']).columnsone_hot_enc_df = pr.one_hot_encoder(data, one_hot_list)
reduce_uniques_df = pr.reduce_uniques(data, reduce_uniques_dict)
reduce_uniques_df = pr.one_hot_encoder(data, reduce_uniques_dict.keys())
scale_data_df = pr.scale_data(data, scale_data_list)final_data =pd.concat([one_hot_enc_df, reduce_uniques_df, scale_data_df], axis=1)
现在有了一个完全数值化的数据集,可以用来训练机器学习模型:
转换列的快照
包
当进行机器学习项目时,通常需要或有时需要创建几个相关模块并将其打包,以便一起安装使用。

图源:unsplash
例如,笔者目前在使用的一款针对机器学习模型的谷歌云部署解决方案,名为 AI Platform。此工具要求在机器学习模型中进行打包预处理、训练和预测步骤,以便上传并安装在平台上,来部署最终模型。
Python包是包含模块、文件和子目录的目录。该目录需要包含名为__init__.py的文件。此文件意味着应将其包含的目录视为包,并指定应导入的模块和函数。
下一步,为预处理管道模型中的所有步骤创建包。__init__.py 文件的内容如下。
from .preprocessing importone_hot_encoder
from .preprocessing import reduce_uniques
from .preprocessing import scale_data
from .makedata import preprocess_data
同一个包的模块可以导入到另一个模块中使用。另一个名为makedata.py的模块将被添加进目录中,该模块使用preprocessing.py模块执行数据转换,然后将最终数据集导出为CSV文件,供后续使用。
import preprocessing as pr
import pandas as pd
def preprocess_data(df, one_hot_list, reduce_uniques_dict, scale_data_list,output_filename):
one_hot_enc_df =pr.one_hot_encoder(data, one_hot_list)
reduce_uniques_df = pr.reduce_uniques(data,reduce_uniques_dict)
reduce_uniques_df =pr.one_hot_encoder(data, reduce_uniques_dict.keys())
scale_data_df = pr.scale_data(data,scale_data_list)
final_data =pd.concat([one_hot_enc_df, reduce_uniques_df, scale_data_df], axis=1)
final_data.to_csv(output_filename)
新目录如下所示:
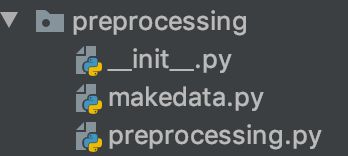
现在可以回到Jupyter Notebook,使用这个包来执行所有的预处理。代码已经变得十分简单干净:
import pandas as pd%load_extautoreload
%autoreload 2
import preprocessing as prdata = pd.read_csv('adults_data.csv')one_hot_list =['workclass', 'marital-status', 'relationship', 'race', 'gender']
reduce_uniques_dict = {'education' : 1000,'occupation' : 3000, 'native-country': 100}
scale_data_list = data.select_dtypes(include=['int64','float64']).columnspr.preprocess_data(data, one_hot_list, reduce_uniques_dict,scale_data_list,'final_data.csv')
在目前的工作目录中,将有一个名为final_data.csv的新CSV文件,包含预处理数据集。现在对其重新读取并检查,以确保包按预期执行。
data_ =pd.read_csv('final_data.csv')
data.head()
本文演示了如何将模块和包用于数据科学和机器学习项目,这样的代码更具可读性和可复制性,你学会了吗?。

我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)