- 写在前面
- Cross-Entropy Loss (softmax loss)
- Contrastive Loss - CVPR2006
- Triplet Loss - CVPR2015
- Center Loss - ECCV2016
- L-Softmax Loss - ICML2016
- A-Softmax Loss - CVPR2017
- AM-Softmax Loss-CVPR2018
- ArcFace Loss - CVPR2019
- 欧氏距离or角度距离与归一化
- 参考
博客:博客园 | CSDN | blog
写在前面
Closed-set 和 Open-set 人脸识别的对比如下,

两张人脸图像,分别提取特征,通过计算特征向量间的距离(相似度)来判断它们是否来自同一个人。选择与问题背景相契合的度量方式很重要,人脸识别中一般有两种,欧氏距离和余弦距离(角度距离)。
训练阶段和测试阶段采用的度量方式要一致,如果想在测试阶段使用欧氏距离,自然在训练阶段就要基于欧氏距离来构造损失进行优化。
实际上,不同度量方式间存在着一定的内在联系,
- 欧氏距离与向量的模和角度都有关,模固定,角度越大欧氏距离也越大,角度固定,模同比增大欧式距离也增大,模分别增大情况会比较复杂;
- 余弦距离和角度距离有单调关系(负相关),但两者分布的“密度”不同,观察余弦函数曲线可知,在角度从0向\(\pi\)匀速(线性)前进时,余弦值在0和\(\pi\)附近缓慢变化,在\(\frac{\pi}{2}\)附近近似线性变化
- 当向量模长归一化后,欧氏距离和余弦距离有单调关系,所以,在预测阶段,归一化后的特征选取哪种度量进行判别均可
可对不同损失函数按度量方式进行划分,
- 欧氏距离:Contrastive Loss,Triplet Loss,Center Loss……
- 余弦距离(角度距离):Large-Margin Softmax Loss,Angular-Softmax Loss,Large Margin Cosine Loss,Additive Angular Margin Loss……
先从最基本的Softmax Loss开始。
Cross-Entropy Loss (softmax loss)
交叉熵损失,也称为softmax损失,是深度学习中应用最广泛的损失函数之一。
其中,
- \(n\)个类别,\(N_b\)为batch size
- \(x_{i} \in \mathbb{R}^{d}\),第\(i\)个样本的特征,特征有\(d\)维,属于\(y_i\)类
- \(W \in \mathbb{R}^{d \times n}\)为权重矩阵,\(W_j\)表示\(W\)的第\(j\)列,\(b_{j} \in \mathbb{R}^{n}\)为bias
特征\(x\)经全连接层的权重矩阵\(W\)得到与类别数相同的\(n\)个\((-\infty, +\infty)\)实数,相对越大的实数代表越像某一个类别,Softmax的作用是将\((-\infty, +\infty)\)的\(n\)个实数通过指数映射到\((0, +\infty)\),然后归一化,使和为1,以获得某种概率解释。
指数操作会将映射前的小差异指数放大,Softmax Loss希望label对应的项越大越好,但因为指数操作的存在,只需要映射前差异足够大即可,并不需要使出“全力”。
在人脸识别中,可通过对人脸分类来驱动模型学习人脸的特征表示。但该损失追求的是类别的可分性,并没有显式最优化类间和类内距离,这启发了其他损失函数的出现。
Contrastive Loss - CVPR2006
Contrastive Loss由LeCun在《Dimensionality Reduction by Learning an Invariant Mapping》CVPR2006中提出,起初是希望降维后的样本保持原有距离关系,相似的仍相似,不相似的仍不相似,如下所示,
其中,\(\vec{X}_{1}\)和\(\vec{X}_{2}\)为样本对,\(Y=\{0, 1\}\)指示样本对是否相似,\(Y=0\)相似,\(Y=1\)不相似,\(D_W\)为样本对特征间的欧氏距离,\(W\)为待学习参数。相当于欧氏距离损失+Hinge损失

类内希望距离越小越好,类间希望越大越好(大于margin),这恰与人脸识别特征学习的目的相一致。Contrastive Loss在DeepID2中得以使用,作为Verification Loss,与Softmax Loss形式的Identification Loss构成联合损失,如下所示,
这种Softmax Loss + 其他损失 构成的联合损失比较常见,通过引入Softmax Loss可以让训练更稳定,更容易收敛。
Triplet Loss - CVPR2015
Contrastive Loss的输入是一对样本。
Triplet Loss的输入是3个样本,1对正样本(同一个人),1对负样本(不同人),希望拉近正样本间的距离,拉开负样本间的距离。Triplet Loss出自《FaceNet: A Unified Embedding for Face Recognition and Clustering》。

损失函数如下,
该损失希望在拉近正样本、拉开负样本的同时,有一个margin,
Softmax Loss最后的全连接层参数量与人数成正比,在大规模数据集上,对显存提出了挑战。
Contrastive Loss和Triplet Loss的输入为pair和triplet,方便在大数据集上训练,但pair和triplet挑选有难度,训练不稳定难收敛,可与Softmax Loss搭配使用,或构成联合损失,或一前一后,用Softmax Loss先“热身”。
Center Loss - ECCV2016
因为人脸表情和角度的变化,同一个人的类内距离甚至可能大于不同人的类间距离。Center Loss的出发点在于,不仅希望类间可分,还希望类内紧凑,前者通过Softmax loss实现,后者通过Center Loss实现,如下所示,为每个类别分配一个可学习的类中心,计算每个样本到各自类中心的距离,距离之和越小表示类内越紧凑。
联合损失如下,通过超参数\(\lambda\)来平衡两个损失,并给两个损失分配不同的学习率,

希望达成的效果如下,

以上损失在欧氏距离上优化,下面介绍在余弦距离上优化的损失函数。
L-Softmax Loss - ICML2016
L-Softmax 即 large-margin softmax,出自《Large-Margin Softmax Loss for Convolutional Neural Networks》。
若忽略bias,FC+softmax+cross entropy可写成如下形式,
可将\(\boldsymbol{W}_{j}\)视为第\(j\)类的类中心向量,对\(x_i\),希望\(\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{y_{i}}\right)\)相比\(\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{j}\right), j \neq y_i\)越大越好,有两个影响因素,
- \(\boldsymbol{W}\)每一列的模
- \(\boldsymbol{x}_i\)与\(\boldsymbol{W}_j\)的夹角
L-Softmax主要关注在第2个因素 夹角上,相比Softmax,希望\(\boldsymbol{x}_i\)与\(\boldsymbol{W}_{y_i}\)靠得更近,于是对\(\cos \left(\theta_{y_{i}}\right)\)施加了更强的约束,对角度\(\theta_{y_i}\)乘上个因子\(m\),如果想获得与Softmax相同的内积值,需要\(\theta_{y_i}\)更小,
为此,需要构造\(\psi(\theta)\),需满足如下条件
- \(\psi(\theta) < cos(\theta)\)
- 单调递减
文中构造的\(\psi(\theta)\)如下,通过\(m\)调整margin大小
当\(m=2\)时,如下所示,

二分类情况下,结合解释如下,
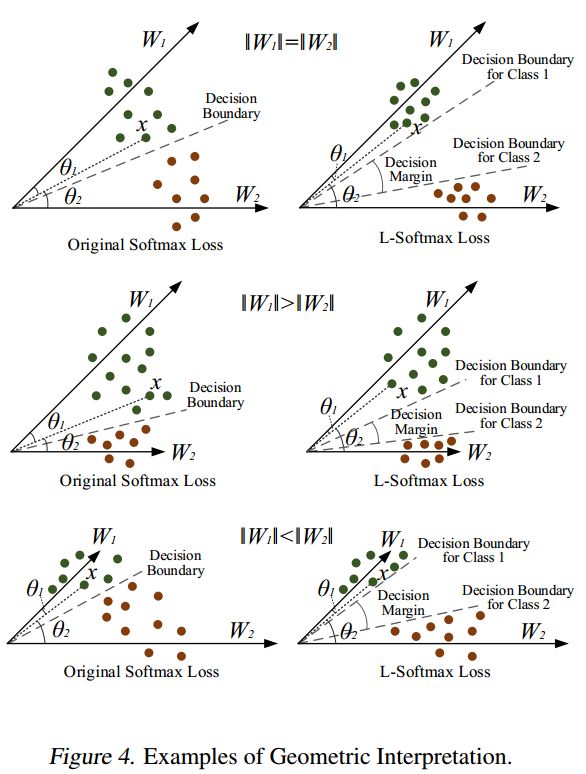
为了梯度计算和反向传播,将\(\cos(\theta)\)替换为仅包含\(W\)和\(w_i\)的表达式\(\frac{\boldsymbol{W}_{j}^{T} \boldsymbol{x}_{i}}{\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\|}\),通过倍角公式计算\(\cos(m \theta)\),
同时,为了便于训练,定义超参数\(\lambda\),将\(\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}}\right)\)替换为\(f_{y_i}\),
训练时,从较大的\(\lambda\)开始,然后逐渐减小,近似于用Softmax“热身”。
A-Softmax Loss - CVPR2017
A-Softmax即Angular-Softmax,出自《SphereFace: Deep Hypersphere Embedding for Face Recognition》。
L-Softmax中,在对\(x_i\)归类时,会同时考虑类中心向量的模和夹角。
A-Softmax的最大差异在于对每个类中心向量进行归一化,即令\(||W_j|| = 1\),同时令bias为0,在分类时只考虑\(x_i\)和\(W_j\)的夹角,并引入和L-Softmax相同的margin,如下所示,
当\(m=1\)时,即不引入margin时,称之为 modified softmax loss。
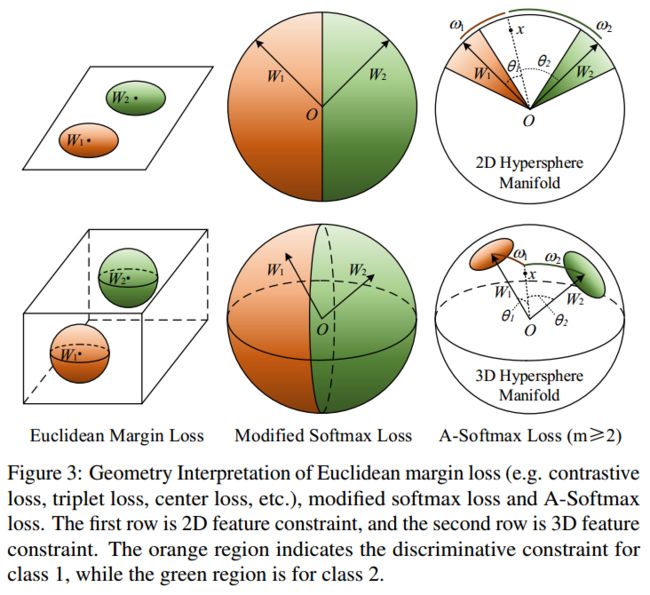
Softmax Loss、Modified Softmax Loss和A-Softmax Loss,三者的决策面如下,

可视化如下,
AM-Softmax Loss-CVPR2018
AM-Softmax即Additive Margin Softmax,出自论文《Additive Margin Softmax for Face Verification》,同CosFace 《CosFace: Large Margin Cosine Loss for Deep Face Recognition》,CosFace中损失名为LMCL(Large Margin Cosine Loss)。
与A-Softmax相比,有2点变化,
- 对\(x_i\)也做归一化,同时保留对\(W\)每一列的归一化以及bias为0
- 将\(\cos(m \theta)\)变成\(s \cdot (\cos \theta - m)\)
相比Softmax,希望获得更大的类间距离和更小类内距离,如果采用的是余弦距离,意味着,要想获得与Softmax相同的\(y_i\)对应的分量,需要更小的夹角\(\theta\),为此需要构建\(\psi(\theta)\),如前所述,需要
- \(\psi(\theta) < cos(\theta)\)
- 单调递减
前面构建的\(\psi(\theta)\),始于\(\cos(m \theta)\),\(m\)与\(\theta\)是乘的关系,这里令\(\varphi(\theta)= s(\cos (\theta)-m)\),
-
\(\cos(\theta) - m\):\(m\)变乘法为加法,\(\cos(m\theta)\)将margin作用在角度上,\(\cos(\theta) - m\)直接作用在余弦距离上,前者的问题在于对类中心向量夹角较小的情况惩罚较小,夹角小则margin会相对更小,同时计算复杂,后者可以看成是Hard Margin Softmax,希望在保证类间“硬”间距的情况下学习特征映射。

-
\(s\):将\(x_i\)也归一化后,相当于将特征嵌入到单位超球上,表征空间有限,特征和权重归一化后\(\mid \boldsymbol{W}_{j}\|\| \boldsymbol{x}_{i} \| \cos \left(\theta_{ij}\right)=cos(\theta_{ij})\)的值域为\([-1, 1]\),即\(x_i\)到每个类中心向量的余弦距离,最大为1,最小为-1,Softmax 指数归一化前,各类的分量差异过小,所以要乘个因子\(s\),将特征映射到半径为\(s\)的超球上,放大表征空间,拉开各分量的差距。

ArcFace Loss - CVPR2019
ArcFace Loss 即 Additive Angular Margin Loss,出自《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》。
AM-Softmax Loss将margin作用在余弦距离上,与之不同的是,ArcFace将margin作用在角度上,其损失函数如下,

把margin是加在余弦距离(CosFace)还是加在角度(ArcFace)上,在《Additive Margin Softmax for Face Verification》中有这样一段分析,

ArcFace中并没有求取arccos,所以计算并不复杂,而是把margin加在了角度上,但优化的仍是余弦距离。
还有一点需要注意的是,无论margin是加在余弦距离上还是加在角度上,单纯看示意图,很容易看出减少了类内距离,那类间距离增加呢?
文中,给出了类内距离和类间距离的数学描述,如下:
\(W\)是待学习的参数,特征\(x_i\)也是通过前面层的权重学习得到,在训练过程中\(x_i\)和\(W\)都会发生变化,都会被梯度驱使着向Loss减小的方向移动。margin的引入有意压低了类标签对应分量的值,去尽量“压榨”模型的潜力,在softmax中原本可以收敛的位置还需要继续下降,下降可以通过提高类标签对应分量的值,也可以通过降低其他分量的值。所以,\(x_i\)在向\(W_{y_i}\)靠近的同时,\(W_j, j\neq y_i\)也可能在向远离\(x_i\)的方向移动,最终达成的效果就可能是\(x_i\)尽可能地靠近\(W_{y_i}\),而\(W_j, j\neq y_i\)远离了\(W_{y_i}\)。
欧氏距离or角度距离与归一化
这里,再讨论下为什么对\(W\)和\(x\)的模进行归一化,主观思考偏多,未经验证。
在文章为什么要做特征归一化/标准化?中,我们提到,
归一化/标准化的目的是为了获得某种“无关性”——偏置无关、尺度无关、长度无关……当归一化/标准化方法背后的物理意义和几何含义与当前问题的需要相契合时,其对解决该问题就有正向作用,反之,就会起反作用。
特征\(x\)与\(W\)每个类中心向量内积的结果,取决于\(x\)的模、\(W_j\)的模以及它们的夹角,模的大小和夹角的大小都将影响内积结果的大小。
-
对\(W_j\)归一化:如果训练集存在较严重的类别不均衡,网络将倾向于把输入图像划分到图片数量多的类别,这种倾向将反映在类中心向量的模上,即图片数量多的类别其类中心向量的模将偏大,这一点论文One-shot Face Recognition by Promoting Underrepresented Classes中有实验验证。所以,对\(W_j\)的模归一化相当于强迫网络同等看待每一个类别,相当于把同等看待每一个人的先验做进网络,来缓解类别不均衡问题。
-
对\(x\)归一化:对某一个具体的\(x_i\),其与每个类中心的内积 为 \(x_i \cdot W_j = |x_i||W_j|\cos \theta_{ij} = |x_i|\cos \theta_{ij}\),因为每个类别的内积结果都含\(x_i\)的模,\(x_i\)的模是否归一化似乎并不影响内积结果间的大小关系,但会影响损失的大小,比如内积结果分别为\([4,1,1,1]\),模同时放大1倍,变成\([8,2,2,2]\),经过Softmax的指数归一化后,后者的损失更小。在卷积神经网络之卷积计算、作用与思想中,我们知道模式蕴含在卷积核的权重当中,特征代表着与某种模式的相似程度,越相似响应越大。什么样的输入图像容易得到模小的特征,首先是数值尺度较小的输入图像,这点可以通过对输入图像做归一化解决(如果输入图像的归一化不够,对特征进行归一化可能可以缓解这个问题),然后是那些模糊的、大角度的、有遮挡的人脸图像其特征的模会较小,这些图在训练集中相当于困难样本,如果他们的数量不多,就可能会被简单样本淹没掉。从这个角度看,对\(x\)进行归一化,可能可以让网络相对更关注到这些困难样本,去找到更细节的特征,专注在角度上进行判别,进一步压榨网络的潜能。有点Focal Loss思想的感觉。
网络会利用它可能利用上的一切手段来降低损失,有些手段可能并不是你所期望的,此时,通过调整数据、融入先验、添加正则等方式抑制那些你不希望网络采取的手段,修正网络进化的方式,以此让网络朝着你期望的方向成长。
以上。
参考
- A Performance Comparison of Loss Functions for Deep Face Recognition
- InsightFace: 2D and 3D Face Analysis Project
- 人脸识别的LOSS(上)
- 人脸识别的LOSS(下)
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用