Wide &Deep Learning for Recommender Systems
本文思路整理如下:
一, Contribution
二, 实验
实际需求
训练数据
实验环境
2.1本文模型
2.1.1 模型输入
2.1.2 模型训练
2.1.3 模型输出
2.2 实验结果
《Wide & Deep Learning for Recommender Systems》
目的:采用Wide &deep构建模型,从而得以更精准做Google Play推荐。
论文信息:Google发表于DLRS 2016的一篇文章。
一,Contribution:
1)提出了Wide & Deep learning框架,将logistic model和forward dnn网络结合起来,既发挥logistic model的优势,又利用dnn和embedding的自动特征组合学习和强泛化能力进行补充,保证记忆能力与泛化能力的均衡。而且将模型整体学习,理论上达到最优。
2)在Google Apps推荐的大规模数据上成功应用。
3)基于tensorflow开源了代码
二, 实验:
首先:考虑实际需求:
l 超过一百万个应用程序,所以它是难以在服务延迟需求中精确计算每个查询。
基于上面需求,本论文先retrieval粗筛,用machine-learning models和human-defined rules,再ranking精排。
Retrieval部分输入query,是用户信息与上下文信息构成的特征,输出则是经过推荐模型排序的条目列表。
Ranking部分即就是本文重点,Wide & Deep learning框架就是用在这里,以下详细展开。
其次,本文实验数据集:Google Apps。
实验环境:tensorflow
2.1本文模型:
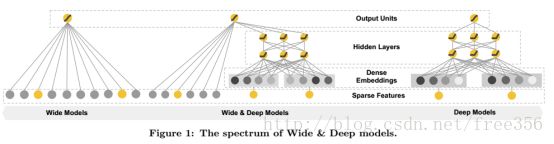
Wide为LR模型, 需要添加特征变换(transformed feature)来保证模型的memorization能力。Deep learning为DNN模型, 对稀疏以及未知的特征组合做低维嵌入保证模型的generalization(泛化, 归纳)能力。具体见下图:
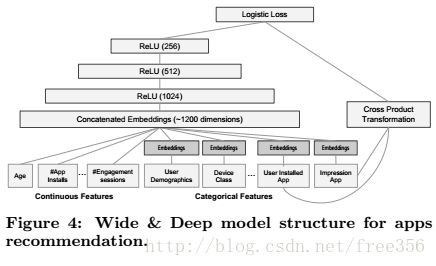
2.2.1 模型输入
l user features (e.g., country, language, demographics)
l contextual features (e.g., device, hour of the day, day of the week)
l impression features (e.g., app age, historical statistics of an app).
2.2.2 模型训练
1,对于Wide部分
Wide部分为简单逻辑回归y=wx+b。
特征集包括原始输入特征和转换特征。转换特征如下: 例如,“(性别=女,语言= EN)”为1,当且仅当构成特征“性别=女性”和“语言= EN”都是1否则为0。这将非线性添加到线性模型。
例如,“(性别=女,语言= EN)”为1,当且仅当构成特征“性别=女性”和“语言= EN”都是1否则为0。这将非线性添加到线性模型。
2,对于deep部分
输入是类别特征(产生embedding) + 连续特征。连续实值特征归一化到[0,1],再划档离散化。
embedding:将高维稀疏的类别特征embedding为低维稠密的向量(Dense Embeddings),与其他连续特征(用户年龄、应用安装数等)拼接在一起。
embedding的结果是在训练时候学出来的。首先对嵌入向量进行随机初始化,然后将这些低维稠密嵌入向量送入前向神经网络的隐层。

其中a是deep部分l层的输出activation结果。
3,对于w&d结合
wide与deep结合的方式,是将两者的输出通过加权最后喂给一个logistic损失函数。值得注意的是,这里是join train并不是ensemble,ensemble是两个模型单独学习,而w&d是同时学习的。
具体训练时,LR部分是FTRL+L1正则,DL用的AdaGrad。
为减少计算时间,实施了一个热启动系统,系统初始化一个新的模型的嵌入和从以前的模型的线性加权模型。文中还提到使用更小的batchs与并行操作以提高推荐引擎的性能。
2.2.3 模型输出
![]()
a是deep部分最后一层的输出activation结果。Y是二进制类标签,标签是应用程序安装,安装为1,不安装0。P(Y=1|X)是一个分数,用于排名。
2.2 实验结果
本文从app acquisitions 和 seving performance两个方面评估 Wide&Deep learning的效果。
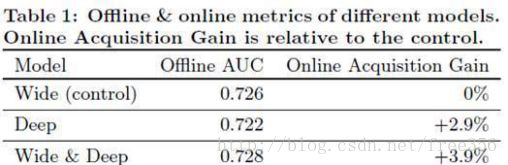
app acquisitions:通过对1%的a线上用户进行A/B testing,Wide&Deep效果明显,线下实现效果提升不大的原因可能是线下的实验数据是固定的,限制了模型的泛化能力。实验效果见Table1:
seving performance:工程现采用并行,并使用较小的batch满足推荐引擎的高并发与低延迟的需求。实验效果见Table2:
